




I. INTRODUCTION
Advanced driver assistance system (ADAS) means a system that assists the driver in driving. Lane departure warning system means a system that informs the driver when the vehicle leaves the lane, by means of visual, audible, or vibration. It does not be warned when the driver changes lanes or when the flashing signal is switched on [1], [2]. Types of sensors for lane detection are vision sensors, laser sensors, infrared sensors, and so on. This technology was first introduced to the vehicle in 2000 and has since been actively introduced into the manufacturing of some of the latest Advanced Operating System supported models, such as Nissan, Toyota, Honda, Audi, General Motors and Mercedes – Benz.
At present, collision warning using radar rather than vision systems was studied first by the lane keeping system. This is to use the radar to estimate the distance to the vehicle ahead and the speed of the vehicle to estimate the likelihood of a collision, with which the pick-up warning system has many drawbacks. In particular, distance information to the direction aimed by radar is consistent with the direction of travel of the vehicle in which it is intended to be highly accurate, or where it is different from the direction of progress of the actual vehicle, or where it is not intended to be on a road ahead.
Currently, autonomous vehicles with vision systems are first commercialized in Japan, but due to limitations in image noise rejection, the concept of an automatic system that makes it difficult for drivers to create an AVAS, or an AVS Research is actively being carried out on how to prevent accidents by identifying vehicles nearby in advance in order to prevent lane departure, which is the cause of most traffic accidents.
Recent studies have suggested video processing techniques to separate lanes, vehicles, and obstacles from road images obtained in a complex environment such as urban roads. In other words, techniques from video processing techniques to automotive identification and tracking and collision avoidance are also proposed. Sensors such as laser, radar, ultrasonic waves, and infrared rays are used to detect nearby terrain information and obstacles. Detection of the vehicle is essential for safe driving in vehicle driving aids. Research related to this is receiving much attention and various detection algorithms has been proposed. However, the vehicle areas in which vehicles are present shall be extracted from a complex road image to increase the efficiency of the vehicle detector.
Model-based vehicle area extraction techniques, which assume a combination of typical straight lines and curves, are resistant to noise and loss of lane information. However, it is not suitable for detecting vehicle areas in any roadway type because it is focused on a particular type of road. To resolve the above issues, a technique has been proposed to extract the vehicle area from lane detection using the B-snake technique, which applies both straight and curved roads.
It was also suggested that lane detection techniques be used to distinguish between the color and the width information that roads and lanes have. Many studies proposed that the method extract the area of road that is the vehicle area from lane detection using Hough transform, a technique that detects linear components within the video. Hough transform is known as an efficient way to detect pixels listed as a straight line within an image. However, detection of the vehicle road area with a normal Huff transformation is only well applied if the background information in the road image is simple. Road images with complex and diverse backgrounds, such as urban roads, are difficult to estimate the exact area of the road because of the complicated information on the edges.
This paper is composed as followings: Various robust road feature analysis and recognition technologies based on color are discussed in Section 2. Finally, we will make a conclusion in Section 3.
II. RELATED WORKS ON ROAD DETECTION WITH COLOR INFORMATION
This section describes the techniques used to detect roads according to color space. Since the road areas are different colors from the background, color-based road areas can be detected.
When an image of the model is given as RGB, the HSV component of RGB image is obtained using the following formula [3].
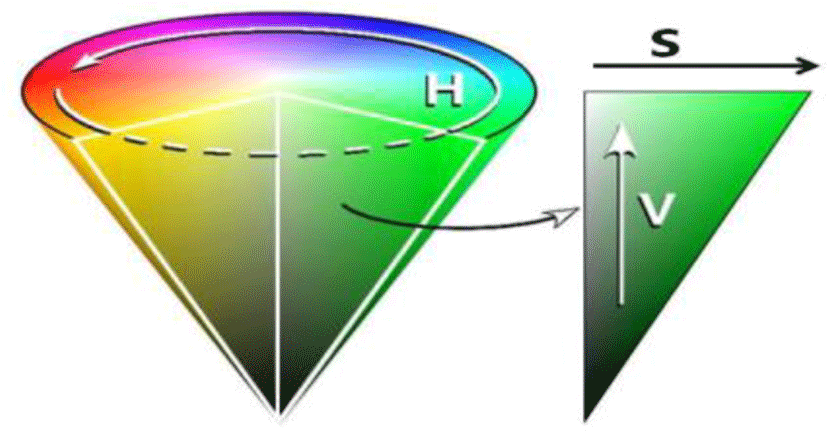
RGB values are normalized to the [0, 1] range, and it is assumed that the angle θ is measured based on the red axis in the HSV space. The color can be normalized to the range of [0, 1] by dividing all the values obtained from Equation (1) by 360°.
Rural roads are very complex and it is difficult to find their edges or features clearly, and it is not easy to find them using gray images. As in other papers, road detection is carried out using a HIS color model, where the brightness component can be separated separately. From the original images in Figure 2 (a), Figures 2 (b), (c), and (d) are photographs of each component of the HIS taken separately. When you look at the picture of the ingredients, you can see that I, the brightness component, best represents the road. Detection of roads using the brightness component I is the complete opposite of other papers. In this paper, only the I-component was used and improved Fuzzy C-Means (FCM) has been employed to detect the road region [4].

The suggested FCM algorithm is as the following:
Step 1. Based on the average gray values of N areas divided in the images computed by the FCM algorithm
Step 2. Locate areas where the grey values change significantly. Here, Cn denotes illumination value of each region and C is the average illumination, respectively.
With Eq. (5), areas in which the grey value satisfies the Cn ≥ α· C are considered as true road areas.
Step 3. All N areas are computed by the FCM algorithm until the condition is satisfied.
Figure 3 shows the performance results of the improved FCM. This method uses the improved FCM algorithm to detect rural roads with I components that are the brightness component. But rural roads are the only way to detect an opaque road, unpaved.

MultI-color detection model has been proposed by using genetic programming (GP) [5]. GP has been employed for the variable element in representation of an object using the tree structure, and many applications are being made for complex and practical design and optimization issues. Figure 4 shows a crossover structure of genetic algorithm.
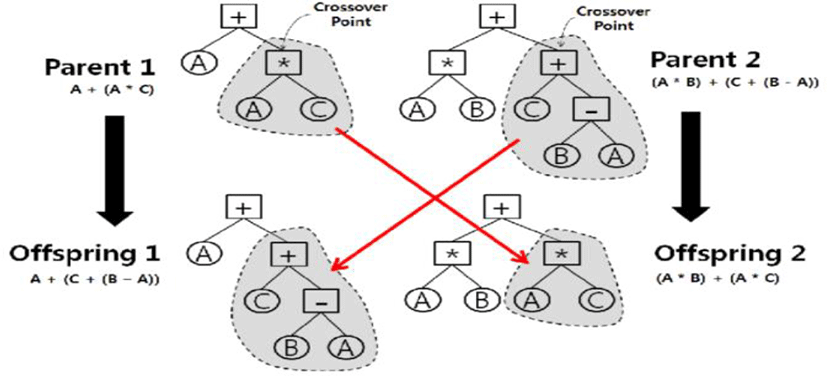
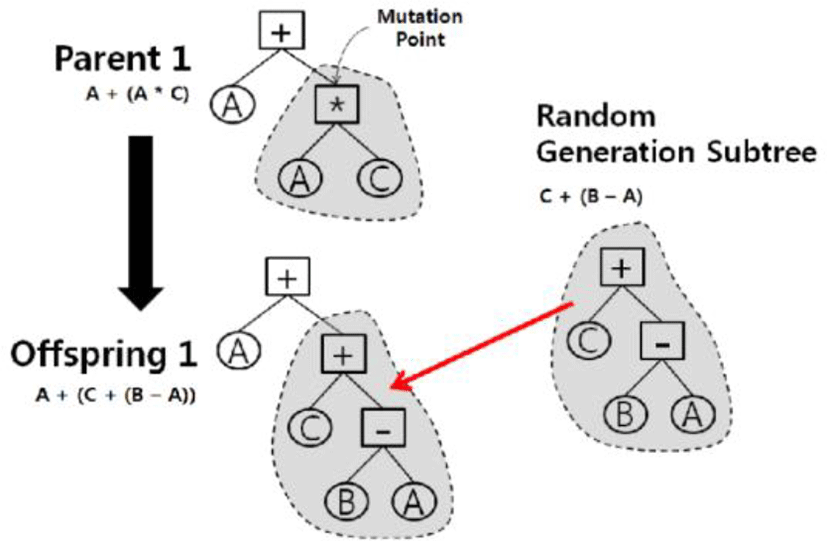
In Figure 5, mutation operation is illustrated in genetic programming. Each node that forms the tree represents a function (Figure 4) or terminal (Figure 4: constants and variables), and each object is composed of a set of functions. The actions of the mating (Figure 4) and the mutation operator (Figure 5) at GP for the subtree are replaced with the subtree at the selection point. The terminals used for the conversion operation use the values of R,G,B,I1,I2,I3,Y,Cb,Cr,H,S,L,L *,a *,b * and the total converted values of channel is in [0, 1]. It uses a total of 16 terminals including random values between [0, 1].
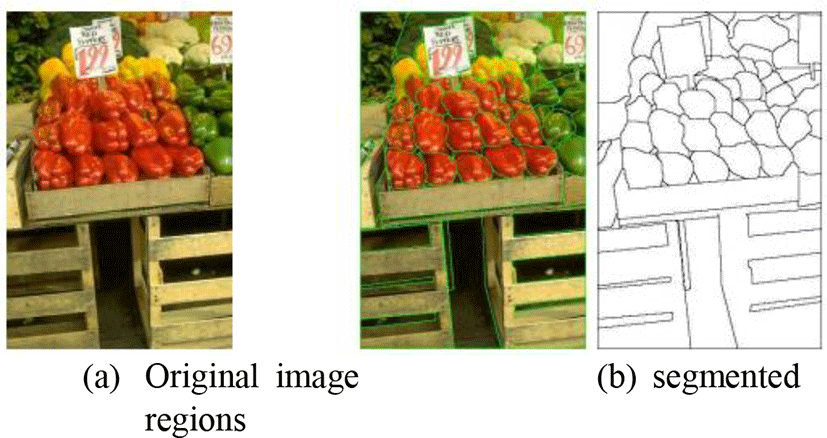
Figures 6 and 7 show some results by segmentation in RGB and HSV color spaces, GP method. From these results, the GP method get the better result than other color space model. GP technique can check exact detection results, except for the noise present in the image with darker brightness for the learned color, but for those that are not learned, it cannot detect some regions according to their brightness areas.


The human brain unconsciously carries out image segmentation to understand scenes. Many problems with computer vision also require high quality video segmentation. Image search, object tracking, face recognition, augmented reality, and gesture recognition can be solved more than half as long as the segmentation is carried out successfully.
Splitting of normal natural images, such as Figure 8, is a very difficult problem. The split expression of the input image f may be defined by equation (6) [6]-[8].
Here ri is the i-th area obtained from segmentation and n is the number of zones. The first condition means that the regions can not overlap each other, and the second is the demand that all areas cover the entire image. The third equation q(ri) is a condition function that all pixels belonging to an area ri must have the same characteristics (similar business cards). So, the third and the fourth expressions are that it is a requirement that pixels belonging to the same area should have the same characteristics and that neighboring areas have different characteristics.
Figure 9 shows the connectivity in image segmentation [9]-[10]. Indicates the properties connected to pixel values of the same characteristic in the centered circle image. Image segmentation algorithms are constantly evolving and developing more than ever before, but they limit their practicality under unrestricted circumstances. Many currently deployed application systems use more local features than areas. However, when one recognizes, one uses domain information, not local characteristics.

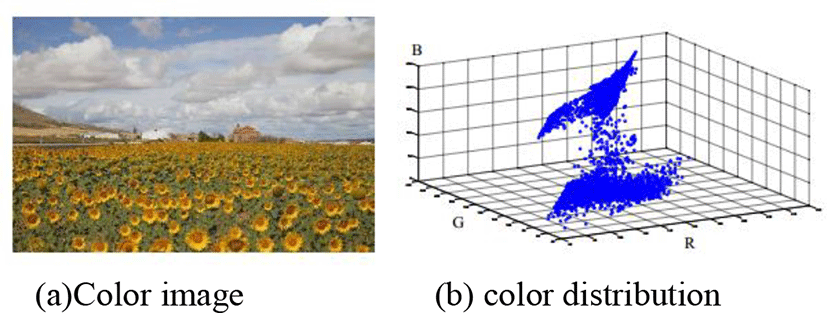
In the case of color images, pixels can be mapped to three-dimensional space. Figure 11 shows the mapped result. The dots floating in the 3-dimensional space will be closer to each other as the colors are similar. Color division can be carried out using these properties. The representative approach is data clustering mechanism [11]-[13].
The CAMShift algorithm uses MeanShift’s shortcomings with a technique to self-size search windows to improve the MeanShift algorithm in the Color Segment method for use in the tracking environment [14], [15].
Used to track objects at high speed and have poor performance in light-change, noisy backgrounds. Using the distribution of Hue values in the areas of the detected object, the location to be changed is predicted and detected, and then the object is centrally tracked.
Once a region of interest (ROI) is given, it converts to the Hue value of the SHV color model, builds, stores, and uses a 1-dimensional histogram of the areas of interest. It is used by setting several windows within the image and by repeatedly changing the size and position of each window's center point, where the position of the pixels within the window is averaged separately for the pixel values to be averaged.
This process is repeated until the windows are assembled, and whether or not the windows are collected is determined by a change in the location and size of the windows. That is, the changed window will converge when its position and size do not differ from the previous value. When all windows in an area are clustered, the maximum window output can vary. Figure 11 shows a result by CAMshift algorithm.

V. CONCLUSION
In this paper, video processing techniques were investigated on a color-based basis to separate lanes, vehicles, and obstacles from road images obtained in a complex setting, such as a city road. From our analysis, we need to choose the right color space, first, because it can be insensitive to the variety of lighting changes. Also we should define some prior knowledge such as the region of interest (ROI). With these information, we have to develop the color segmentation or merging algorithm to suppress some noise components. The geometric structure of camera view can be also recommended in the detection system.