





I. INTRODUCTION
Speech Recognition that otherwise known as automatic speech recognition (ASR) distinguishes the spoken words, persons and transfers them to a machine-readable configure. By transferring spoken audio into text, speech recognition skill enhances the users to organize digital devices. The traditional tools like keystrokes, buttons, keyboards etc the ASR technique can be broadly used in all walks of life [1].
In recent years, neural networks of deep learning have taken force in the field of artificial sensory development such as machine vision [26], [27]. In the emulation of this sense, the developments evolve from the segmentation of objects into images and localization of elements, e.g., localization of pedestrians where more recently, these techniques of usage of neural networks have been applied to voice recognition [2]. The initial developments that made use of neural networks in speech recognition began to implement different types of basic networks such as time-delay neural networks [3]. Due to the low processing capacity that computers had in the 90’s, the neural networks did not have great depth, however, thanks to the progress in processing speed, it was possible to start deploying ever deeper neural networks, making them increasingly efficient in pattern recognition for this reason the interest has arisen in the application of these in tasks of speech recognition, even above other recognition techniques [4]. The introduction of Deep Neural Networks (DNN) for speech assignments began in the early 2010’s developing DNN in combination with the Hidden Markov Model (HMM) [5], since, it allows modeling the sequential structure of a speech signal.
According to the high performance that Convolutional Neural Networks (CNN) have had in pattern recognition it has been begun to apply the concepts of convolution in DNN to speech recognition obtaining hybrids between convolution and fully connected layers [6]. However, at first, they did not exceed 3 convolution layers combined with a higher number of fully connected layers which limits the ability to acquire patterns and makes the performance not really high [7]. Recently, architectures began to be developed deeper and in combination with other types of neural networks like the recurrent neural networks which help in the temporal relationship that may exist between signal divisions, improving the reduction of error in phonetic recognition [8].
The architectures that have been developed, according to the state of the art have as input feature maps of phonemes which are used in large vocabulary continuous speech recognition, however for more basic applications, the use of phonemes makes them more complicated for its implementation, so, an alternative to reduce the complexity is the recognition of certain number of words delimited by the application, making the implementation of a CNN more feasible and achieve a better performance by the parameters that have to learn [9]. For this reason, in this work two CNN architectures based on the recognition of complete words are built which have not been developed in the state of the art as a complement to this research area [10].
In simple words speech recognition could be defined as the development of converting speech signal to a progression of words by means of algorithm demonstrated as a computer program [11]. Speech processing is the main areas of signal processing. The contribution of speech recognition is to develop a method for speech input to machine based readable script, which can be very well used in libraries, banks, and various workplaces for effective management [12]. Regular speech recognition today discovers widespread relevance in tasks that necessitate human machine interface like automatic call processing [13]. Fig. 1 illustrates the architectural framework for generating speech recognition.
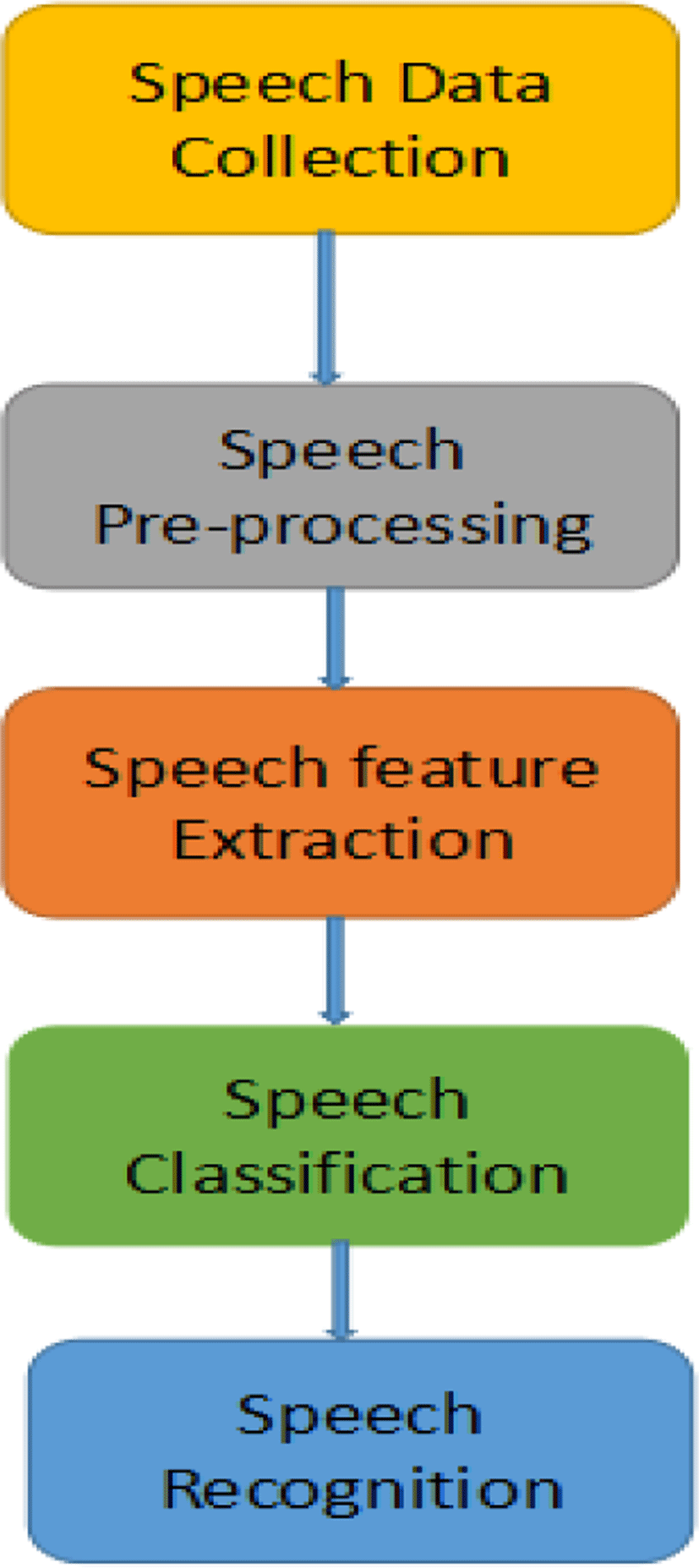
II. EXISTING SYSTEM
In the existing system, a librarian can use barcode to get a particular book details and its availability in the library [14]. But the exact location where the book is placed cannot be easily identified. It is very difficult and laborious to get a particular book or books when large volume of books, manuals, research papers etc. are stacked in big libraries [15]. Moreover, it is time consuming and there is every possibility for misplacement and wrong issue of books or journals etc. [16]. ASR processing of a multimedia document’s soundtrack has proven to be a substantial hindrance for users when searching multimedia digital libraries for sub-document segments (i.e., audio or video clips) [17].
The Phoneme Matching Algorithm has been developed that represents an early attempt to increase the effect of such speech-to-text transcription errors; this study reports on an attempt to enhance the efficiency [18]. The points-based scoring system makes it possible to calculate a Phonetic Divergence Score (PDS) when comparing any two given phoneme series with the difference in the selected phonemes’ scores indicating the degree of phonetic divergence [19]. For the experiments detailed in this study, PDS scores have been standardized by way of dividing the total PDS score by the number of phonemes in the query term, thus a 10-phoneme query term garnering a gross PDS score of 30 would be assigned a standardized PDS score of 3 [20].
Speech technologies must be developed for decades as a distinctive signal processing region, while the preceding decade has brought an enormous development according to the latest machine learning paradigms. In spite of the intrinsic complexity has been proposed that the relations with cognitive systems, speech recognition methods are the most common interdisciplinary knowledge area. The paper fully based on to develop the machine learning methods that are computational intelligence contributes to provide fields that cover speech construction and auditory observation that demonstrates the speech transmission and language, speech recognition. The spoken dialogue construction is consequently speech synthesis.
Moreover, this paper demonstrates the concepts of recent developments in speech signal demonstration, coding that include cognitive coding. The main objective of this paper is to highlight the recent development according to the latest machine learning methods that has an impact in the development of speech signal processing.
III. PROPOSED SYSTEM
In the existing system various algorithms are used whereas in the proposed system we have implemented only Artificial Neuron Network (ANN) and accordingly input data’s have to be fed and output results probably the exact one is expected to be derived. By this means considerable time saving is expected and financial implications too can be minimized.
ASR demonstrates into a training method that the system learns the reference represents the dissimilar kind of speech recognition that comprises the application of the vocabulary systems. Every reference is learned from spoken application that stored like templates constructed by several methods which illustrate the pattern related properties. The recognizing phase that input pattern is generated by the references. Fig. 2 demonstrates the Automatic Speech Recognition.
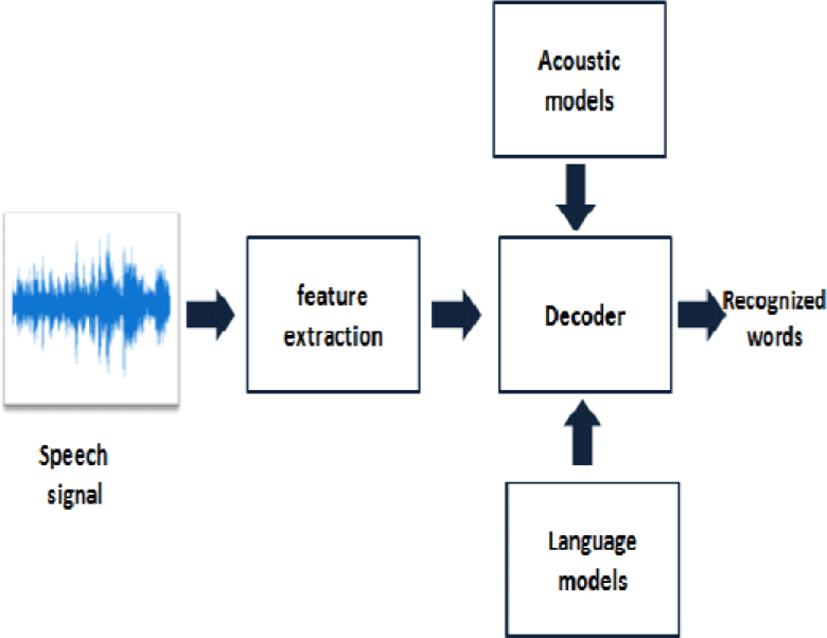
The main objective of speech recognition is too capable of understand the spoken information. The related methods did not execute the expected accuracy, so the proposed methodology has been constructed to implement the speech recognition in an automatic manner with speaker identity. This system could be constructed to implement the feature extraction, modeling, analyzing and also testing process.
A suitable feature which can differentiate the “Cholo” and “Thamo” signal is magnitude analysis of the given signals.
A general condition feature can be applied as,
-
Find the max() of the signal and its location.
-
Let apeak range of the duration of the signal is -5000 to 5000 location for max().
-
Now, find the max() of the amplitude of the location of before the range and after the range.
-
If both magnitudes before highest and after highest are less than (highest-0.3), then the signal will be ‘Thamo’, where (highest-0.3) is our minimum countable max.
-
The exception of this condition will be ‘Cholo’ signal.
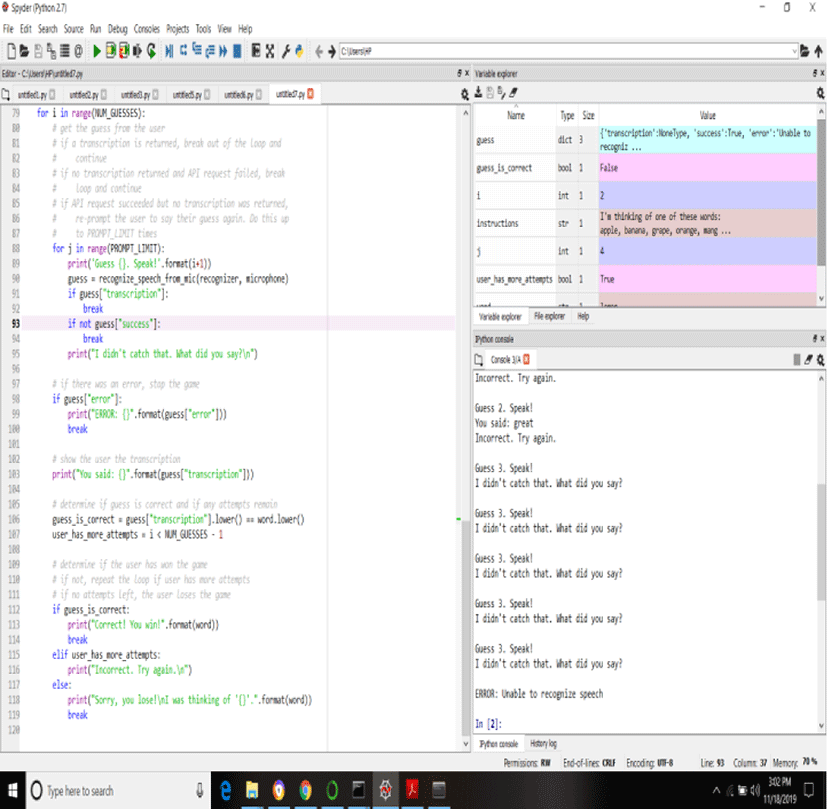
Here is common scenario of a Cholo signal where upper figure is original signal and below the figure is pre-processed signal plot. As I can observe that, here the highest max is 1 and if I take another two max before the highest and after the highest those max magnitudes are very near to the highest and differences are in between 0.3 range. Now, the general scenario of the Thamo signal plot which is given besides, after the pre-processing, the maxs of before and after highest of Thamo signals are quite far (in magnitude) at all.
Therefore, we have set a condition of if-else in my MATLAB code as, If before max and after max is less than [highest-0.3], that signal is Thamo signal. Else of the condition is, Thamo signal; where, before max and after max is greater than [highest-0.3], that means in between this range
Here, we have got 7 succeed and 5 Failed output. So, there are 3 kinds of failure I have found and the reason behind the failure cases are discussed below,
-
Peak range: In some cases, ± 5000 peak range exceed
-
Magnitude range: Due to peak range violation I got smaller magnitude max
-
Noise problem: In noisy signals, sometimes noise becomes max magnitude
At the end of this experiment, we have obtained proper knowledge about how signal works in moving average filter. I passed the signals through 400 points moving average filter and analyzed the data. I found a pattern for to successfully distinguish between ‘cholo’ and ‘thamo’ audio signals. This can also be done in various other methods as I have seen by the other groups. I found this technique effective and unique and thus used this to solve the problem. For audio signal analysis, this experiment proves as a basic and will help us in future experiments.
The development of speech recognition methods is constructed using the innovative machine learning methodologies to implement the accuracy level. According to the improvement of the machine learning approach has been utilized to provide the excessive impact to this development. HCI systems are having the spoken language understanding and demonstration.
The machine learning concept has automation about the speech recognition system to translate the text to speech technology. It is demonstrated that the system with deep learning approach could be capable of recognizing the speech components in an acoustic surrounding with the capability of analyzing the accuracy with human based interaction system using HCI of style and speaker quality.
The reinforcement related machine learning methodology has been utilized the unsupervised methodology to develop the progress with huge number of datasets. The speech signal is involved to provide the automatic speech recognition in accurate way and signal based synthesis detection to generate the adaptive quantization in view of speech coding approaches.
The innovative methods could be constructed to provide the robustness in a huge amount of dynamic speech signal demonstrations. The frame adaptive approach can indicate that the machine learning tools to increase the popularity and provided the exact solutions. The improved performances of the proposed system have proved by utilizing the predictive coefficients. An increasing amount of progress in speech signal processing with machine learning approach.
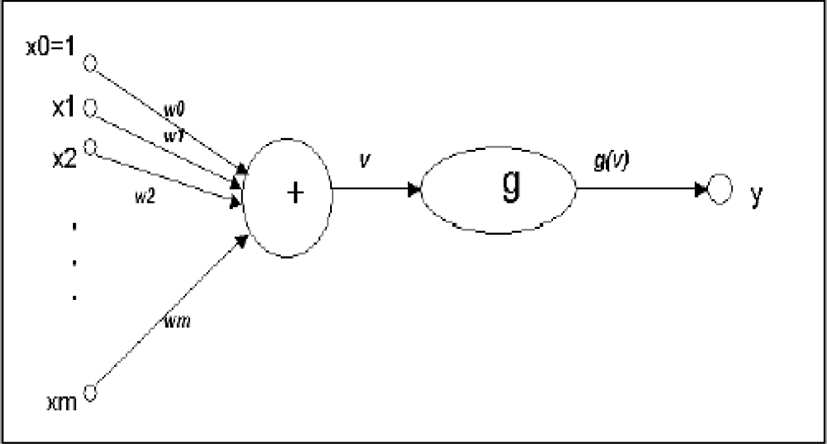
Neural networks have incorporated the Markov chain methodology that the statistical methods are demonstrated as a graph. The Markov models have be utilized for providing the probability based state transitions that the neural networks utilize the connection based state transition. The common dissimilarity within the neural network and Markov model is the parallel connectivity. The state transition is the common strength of the connectivity. Artificial Neurons are the common component of Artificial Neural Network that utilizes the function of organic neuron. It is a mathematical formation that is conceived as a representation of natural neuron. Fig. 3 demonstrates the common artificial neuron.
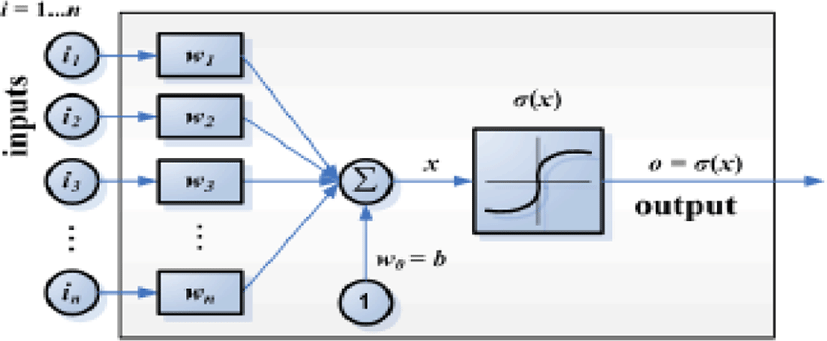
Types of Artificial Neural Network
A Feedforward Network is a mathematical model according to the construction of biological neural networks. The demonstration that flows within the network influences the architecture of the ANN since a neural network modification based on those functionalities. ANNs are measured as non-linear statistical information modeling components that are the multifaceted relationships within the inputs and outputs are modeled. ANN is also called as a neural network. ANNs have 3 layers that are interconnected with other related systems. The initial layer contains the input neurons. Those neurons forward the information to the middle layer, which in turn forwards the output neurons to the final layer. Fig. 4 illustrates the demonstration of the Feedforward network layer.
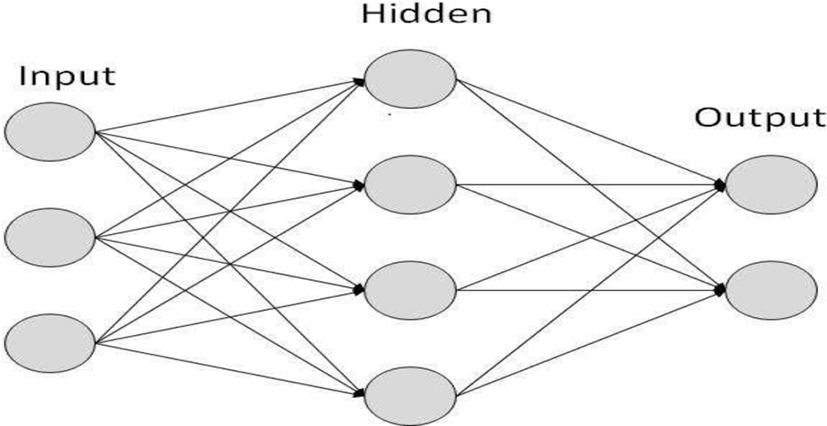
Artificial neural networks are an effort to obtain computers to effort more like the human brain. Your brain doesn’t accumulate detailed encoded functions; it has enormous networks of neurons. These change their communications to every other as latest data past throughout them. Speech recognition with this machine learning is completed with big data-based organizations of data to train these networks.
An ANN has a lot of positives but one of the mainly recognized of these is the reality that it preserves essentially train from scrutinizing the data sets. In this approach, ANN is utilized like a random function estimate component. These types of components assist approximation the nearly all cost-effective and ideal approaches for finding the answers while defining computing distributions. ANN understands data samples rather than whole information to demonstrate at solutions, which has the time utilization. ANNs are measured reasonably simple mathematical elements to augment existing data analysis approaches.
Speech Recognition utilizes the implementation of audio files with AudioFile class. This class could be started with the way to an audio file and presents a context manager edge.
Presently, Speech Recognition wires the following file formats:
-
WAV: must be in PCM/LPCM format
-
AIFF
-
AIFF-C
-
FLAC: must be native FLAC format; OGG-FLAC is not supported
Recognizing speech needs audio input, and Speech Recognition uses retrieving this input. The Speech Recognition will have you up and operation in just a small number of minutes and it is demonstrated in Fig. 5. The suppleness and ease-of-use of the Speech Recognition package create it as a replacement for any Python coding. Moreover, maintain for every characteristic of every API it wraps is not definite. You will require expending more time for identifying the obtainable options to find out if Speech Recognition may utilize in your scrupulous case and it is illustrated in Fig. 6 and Fig. 7.
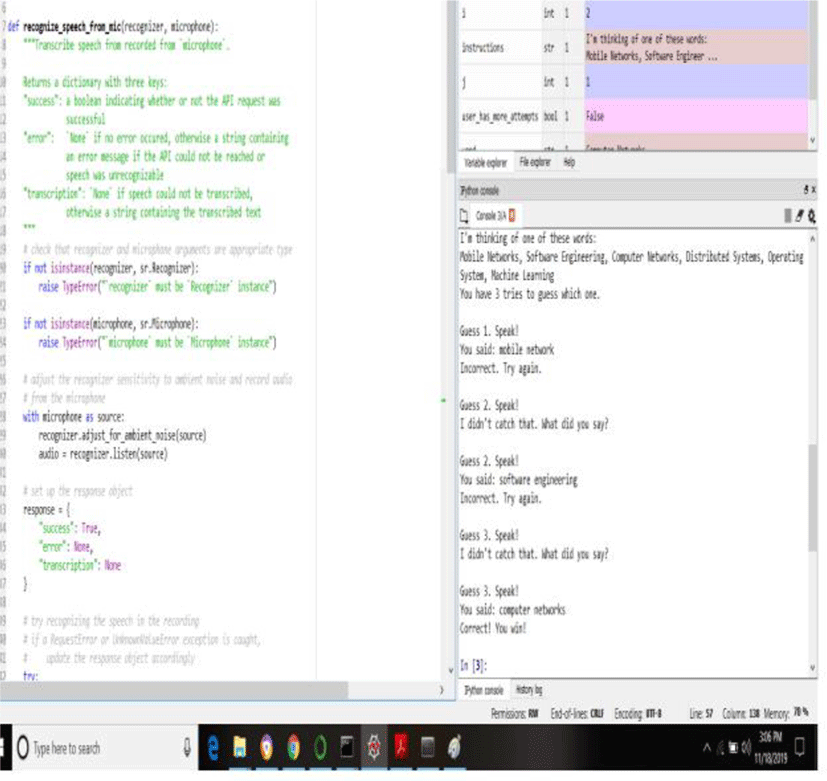
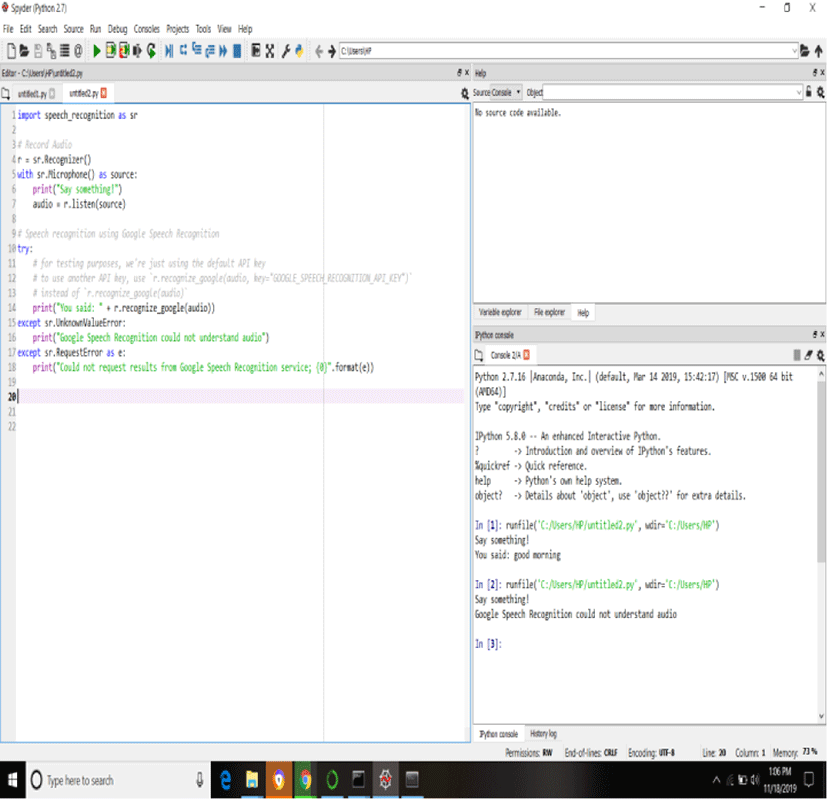
ANNs are comparatively rudimentary electronic networks of “neurons” according to the neural organization of the brain. They procedure has been constructed to store data, analyzing their classification of the system with the mostly used classification of the system. The errors from the original classification of the initial record is fed back into the network, and utilized to adapt the networks algorithm the next time.
In the training phase, the correct class for each record is known (this is termed supervised training), and the output nodes can therefore be assigned “correct” values -- “1” for the node corresponding to the correct class, and “0” for the others and it is illustrated in Fig. 8.
clc
clear all
close all
signals = [‘E:\nufaer\test_data\V-2.mp3’];
audo = audioread(signals);
figure;
subplot(2,1,1);
plot(audo);
title(‘Original audio signal’);
m=400;
b=(1/m)*ones(1,m);
pstv=abs(audo);
audof=filter(b,1,pstv);
audof=audof / max(audof);
subplot(2,1,2);
plot(audof);
title(‘Pre-processed signal’);
maxmag=max(audof)
maxloc=find(audof==maxmag);
nextmag=max(audof(maxloc+5000:end))
prevmag=max(audof(1:maxloc-5000))
if((nextmag<(maxmag-0.3))&&(prevmag<(maxmag-0.3)))
disp(‘signal is thamo’);
else
disp(‘signal is cholo’);
end
IV. CONCLUSION
In this paper, we have tried to introduce a simple approach which could be used to recognize connected speech and the person concerned. The speech features extorted are compared with related speeches in the database for identification. This approach utilizes it possible by the speech of the broadcaster and it will be simple to authenticate their independence. It generates control access to various applications like window speech recognition. Indeed, the application of this technique will certainly enhance smooth and perfect administrative innovations in the day today activates wherever manpower is entertained in multiples such as libraries banks and various workplaces etc. In the present study I have tried to develop a device which will enable to find the presence of a particular data from the cluster of datasets using python. In future this device can be taken to the next level by using Artificial Neural Network (ANN) which will lead us to work with incomplete knowledge on information related to the speech and the person concerned. Further in the new application the network layers will be built and trained to show the pictorial representation of in-built data.


