I. INTRODUCTION
The Future Video Coding (FVC) is a state of the art video compression standard that has been standardized since High Efficiency Video Coding (HEVC), has been studied by the Joint Video Exploration Team (JVET) of ITU-T VCEG and ISO/IEC MPEG. FVC provides a software model called the Joint Exploration Model (JEM) [1], which was released up to version 5.0.
With the development of display resolution and types, video compression technology is required for higher-resolution and the newest services such as VR, AR. For that reason, the FVC standard has begun to work newly.
The Joint Exploration Test Model (JEM) of FVC was developed based on the HEVC Test Model (HM) [2],[3],[4],[5]. Consequently, the basic framework of encoding and decoding is the same with the HEVC, however, the internal coding tools of modules of block structure, intra and inter prediction and transform, loop filter and entropy coding are added and modified.
In this paper, we introduce new coding tools to improve the coding efficiency and analyze them in detail. Especially, we have three coding parts: Block structure, intra prediction, and inter prediction mechanisms. Block structure defines the coding unit in encoding procedure and intra prediction method defines how to make the best residual image signal in the picture. Finally, inter prediction usually is about how to get the minimized residual signal from the reference pictures (multiple reference pictures).
This paper is organized as follows. In section 2, an overview of FVC is presented by detailing its major aspects based on Joint Exploration Test Model (JEM) 5.0. Section 3 presents the video coding performance and the average time distribution. Section 4 concludes this paper and presents some ideas for future work.
II. OVERVIEW OF CODING FEATURES OF JEM 5.0
In this section, we would like to introduce major coding tools which have been proposed in JVET.
Figure 1 illustrates important block structure in FVC standard. In HEVC, CTU is split into CUs through the quadtree structure. Each CU is divided into PU or TU according to the module to be performed, and each unit size applied to each process is different. Unlike HEVC standard, FVC adopts quadtree plus binary tree (QTBT) [6] structure which eliminate this multiple partition type concept and support more flexible CU shapes.
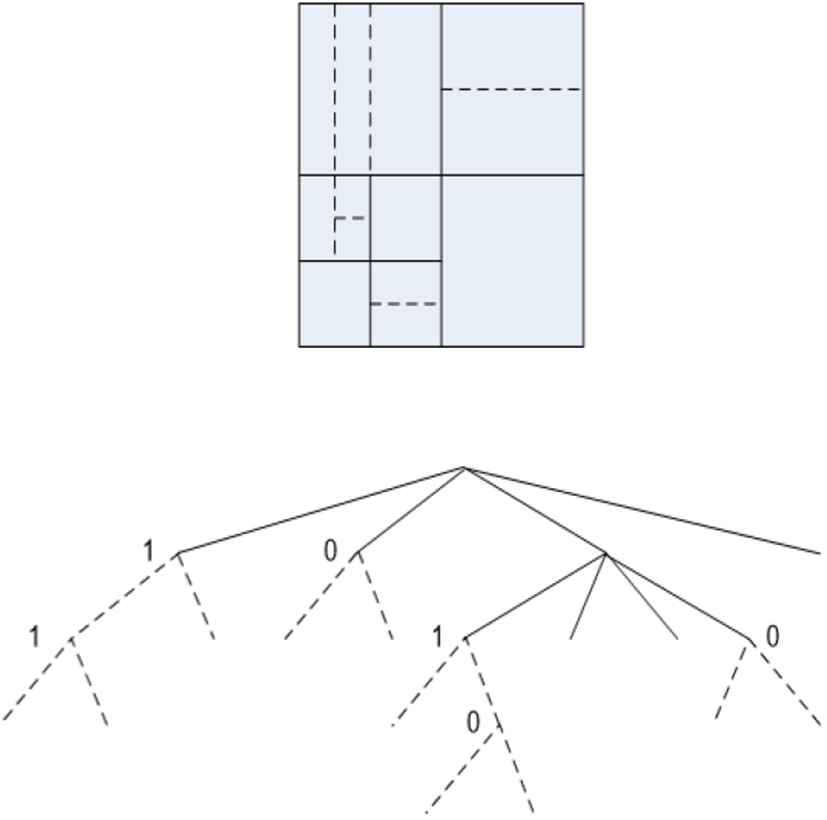
In the QTBT structure, CTU is first divided by a quadtree types, and quadtree leaf nodes are divided by binary tree types. There are two types of binary trees: horizontal and vertical. The leaf nodes of this binary tree are called CUs.
The prediction and transform are performed with the corresponding unit size type without any further partitioning. For the QTBT structure, some parameters are defined, which are CTU size (the quadtree root node size), MinQTSize (the minimum quadtree leaf node size), MaxBTSize (the maximum binary tree root node size), MaxBTDepth (the maximum binary tree depth), MinBTSize (the minimum binary tree leaf node size).
In Figure 1, the first figure illustrates a QTBT structure block partitioning example, and the second illustrates the tree structure corresponding with that of above side. The solid lines mean quadtree splitting and dotted lines mean binary tree splitting. In binary tree splitting, flag 0 means horizontal splitting and flag 1 means vertical splitting.
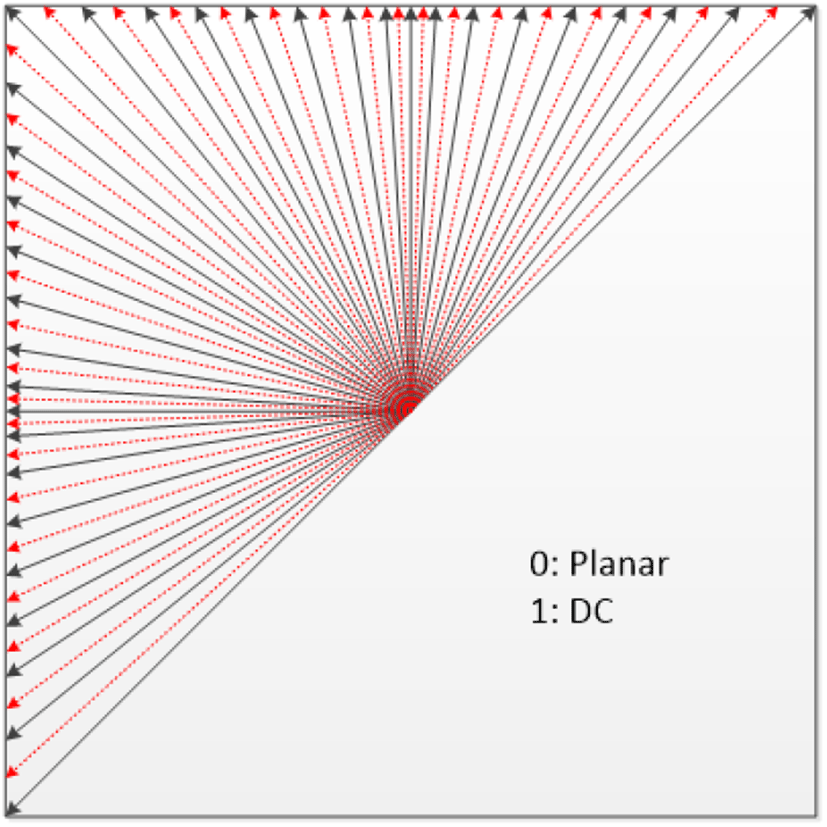
In HEVC, there are 35 modes such as planar, DC, and 33 directional modes in the intra prediction mode. In FVC, the directional intra modes extended to 65, as a result, FVC has 67 modes and adopts methods to reduce candidate modes for each of luma and chroma [7],[8],[9],[10]. In Figure 2, the black line means the existing HEVC directional mode, and the red line means the directional mode newly added in FVC.
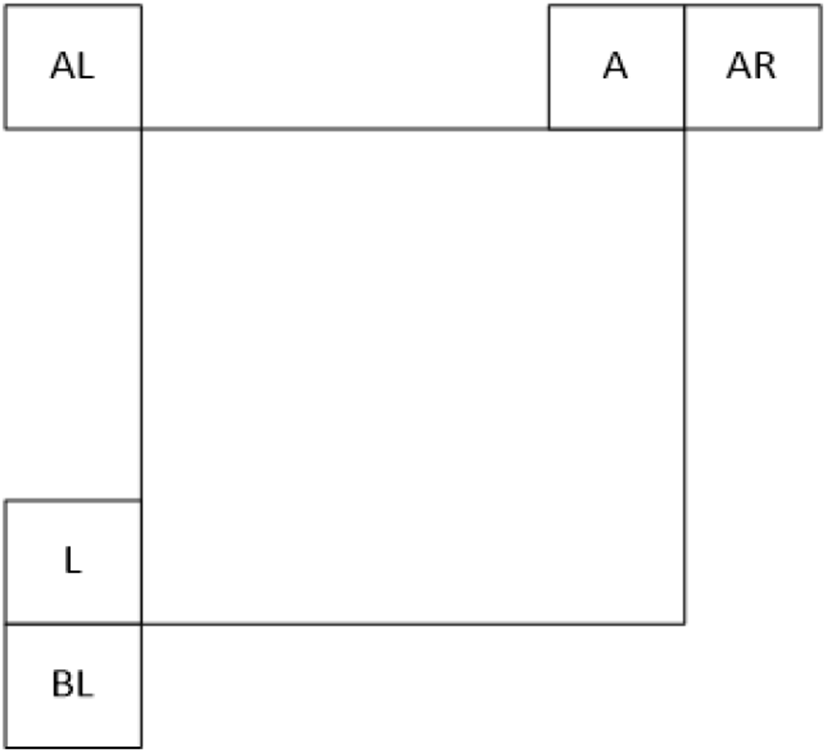
In order to reduce the candidate mode for the luma intra mode coding of the FVC which nearly doubled the number of directional intra modes, 6 Most Probable Modes (MPMs) are employed as shown in Figure 3. The intra prediction modes are classified into three groups, and three steps are taken to create an MPM list with 6 candidates. The three groups are neighbouring intra modes, derived intra modes, and default intra modes. First, in neighbouring intra modes group, add modes of 5 neighbouring blocks, i.e., left(L), above(A), below left(BL), above right(AR), and above left(AL) as shown in Figure 3, planar mode, and dc mode to make a MPM list. If MPM list is not full, go to the group of drived intra modes. In derived intra modes group, −1 or +1 angular modes of the already included angular modes are added. If MPM list still is not full, add the default modes: vertical, horizontal, mode 2, and diagonal mode. As a result, a list of 6 MPM modes is created.
In chroma intra mode coding, a total of 11 modes are selected as the candidate mode list. It consists of 5 traditional intra modes: non-CCLM modes and 6 CCLM [7],[12] modes. Non-CCLM mode refers to the spatial neighbouring block mode as in luma, and the CCLM mode use the luma mode of reconstructed luma sample after encoding for predicting a chroma mode.
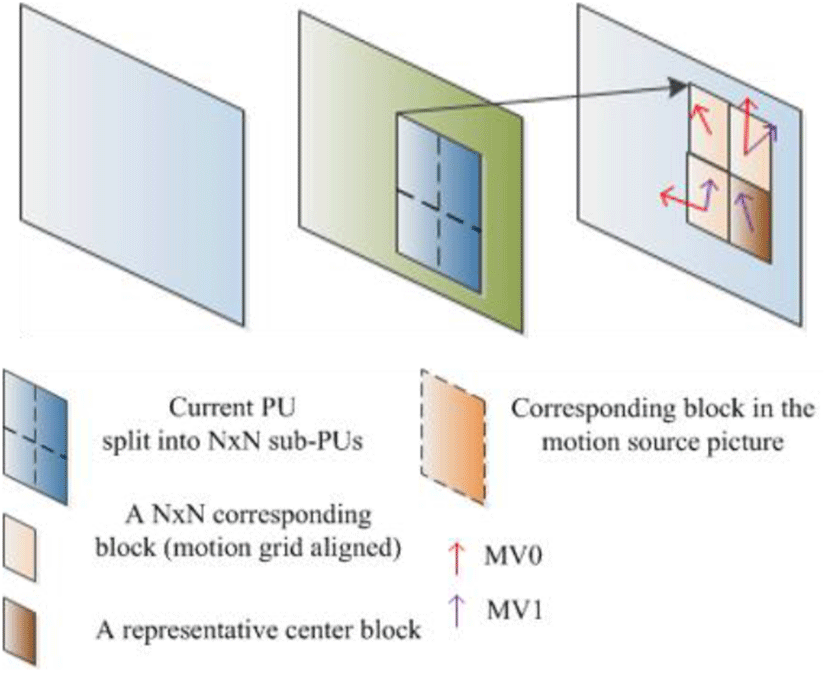
In comparison to the most important algorithms with HEVC, in HEVC, there is the Advance Motion Vector Prediction (AMVP) [11] method which uses motion vectors of 5 spatial neighbors, 2 temporal motion vectors, and zero motion vectors as candidate list and employs them for prediction. In FVC, the Advanced temporal motion vector prediction (ATMVP) and Spatial-temporal motion vector prediction (STMVP) methods are used which improve on AMVP [7],[12],[13]. Both of the aforementioned methods are accessed using the sub-CU. ATMVP is a method for predicting the current CU of the current frame using the motion vector multiple set information of the sub-CU at the same position of the reference frame as shown in Figure 4.
STMVP is a method for motion vector candidate set list is generated by using temporal sub-CUs as the same procedure of TMVP as specified in HEVC and spatial neighboring sub-CU as shown in Figure 5, and then used for predicting.
III. PERFORMANCE ANALYSIS
The reference software model JEM 5.0 [14] and HM 16.10 [15] are used to experiment. Evaluation occurred under 3 profile of all intra, low delay-P and random access. Used standard sequences are ‘ParkScene’ in class B, ‘BasketballDrill’ in class C and ‘FourPeople’ in class E as shown in Table 1. Four base layer QP values of 22, 27, 32, and 37 were used with 32 total frames in each test sequence.
| Class | Sequence | Resolution | Frame rate |
|---|---|---|---|
| B | ParkScene | 1920x1080 | 24 |
| C | BasketballDrill | 832X480 | 50 |
| E | FourPeople | 1280X720 | 60 |
For performance comparison, we employed average BD-rate [16] and the difference of the consumed encoding time (EncT). Bjontegaard’s metric (BD-rate) allows to compute the average gain in PSNR or the average percent saving in bitrate between two rate-distortion curves [16].
The difference of the consumed encoding time (EncT) can be defined as:
Here, T means the checked time. If EncT becomes large positively, then JEM5.0 encoder get more time to process with the same video content and setting. It means that JEM5.0 is slower than HM16.10 software encoder. When EncT is a negative value, it means that JEM5.0 encoder is faster than HM16.10.
Table 2 shows results of variation ratio of BD-rate and time complexity of JEM comparing with HM. For Y, U and V, average BD-rate reduction ratio of 25.46%, 38.00% and 35.78% are accomplished, respectively. We could see that the reduction value of luma was greater than that of chroma. The time complexity variation of all intra has resulted in surprising results. JEM takes about 6.3 times longer than HM encoder. The results of low delay P and random access are about 5.1 and 8.5 times, respectively. Consequentially, in overall, JEM takes about 14 times longer than HM.
| Y | U | V | EncT | |
|---|---|---|---|---|
| All Intra | -22.41% | -31.41% | -27.44% | 6315% |
| Low Delay_P | -25.72% | -42.29% | -40.69% | 515% |
| Random Access | -28.24% | -40.32% | -39.21% | 854% |
| Overall | -25.46% | -38.00% | -35.78% | 1405% |
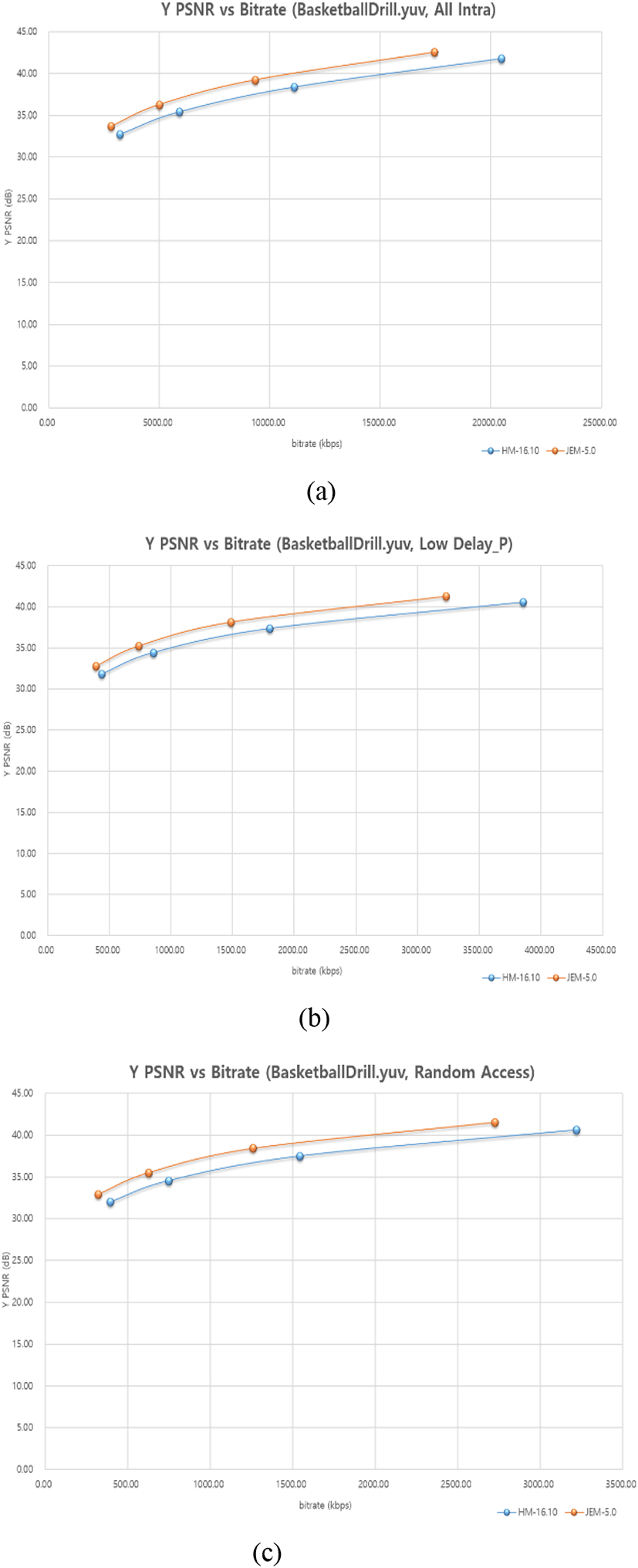
Figure 6 presents rate distortion curves of JEM 5.0 and HM 16.10 for the BasketballDrill video sequence. These results indicate the improvement of the coding efficiency of the new video compression standard. For all intra configuration, we can observe the PSNR improvement of 2.0 dB ~ 2.7dB at same bitrate. In case of low delay P, about 2.0 dB of the quality improvement has been achieved. For random access configuration, over 2.5 dB of PSNR improvement was observed in 2000 Kbps. At this time, the PSNR is over 40dB. This is much improvement when comparing to the HEVC standard.
In order to determine which of the coding components consume most time, we set a timer in encoder. Figure 7 shows the time division of the JEM 5.0 encoder for 3 profile: all intra, low delay P, random access. The Transform and Quantization represent the highest percentage of the coding time in all intra. In low delay p, the inter prediction represent nearly 50% of the encoding time. In random access, consumes more than 60% of the inter prediction encoding time and 27% of the intra prediction encoding time.
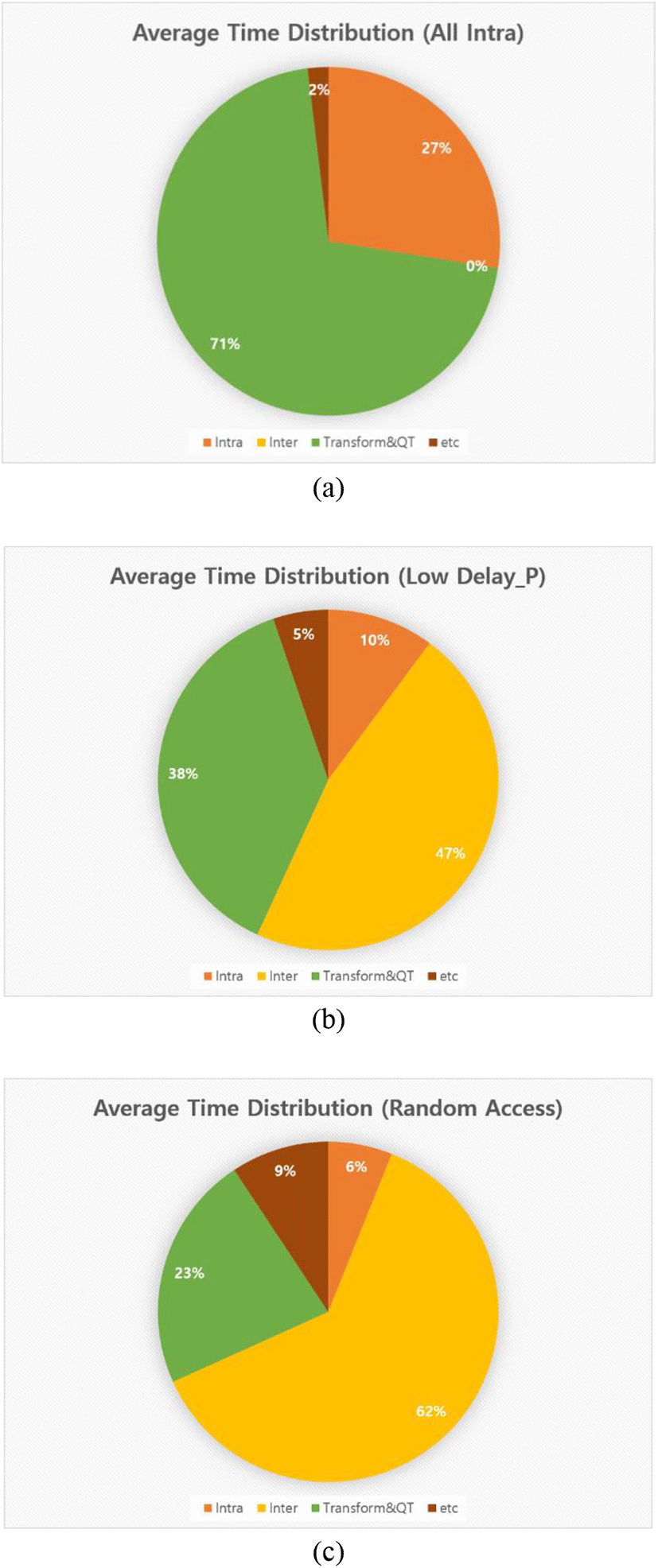
For this reason, we can assume that the I-frame coding consumes the most time in the transform and quantization and the P-frame or B-frame coding consumes the most time in the inter prediction coding.
IV. CONCULSIONS
In this paper, a comprehensive coding features for the FVC standard comparing with HEVC have introduced and analyzed. The most important feature of the FVC is the block structure with a QTBT structure which simplify the coding units and improve the coding efficiency. The improved intra and inter prediction changes also contributed to performance improvements. Through experiments, the FVC based on JEM 5.0 software provides an average BD-rate reduction of 25.46%, 38.00% and 35.78% for Y, U and V, respectively. Also the FVC technology took about 14 times longer than HEVC encoding system. For future work, we need to more analysis to improve the coding efficiency of the FVC.