I. INTRODUCTION
In recent years, AI has been the mainstream technology of the 4th Industrial Revolution and has attracted the most attention in businesses, government policy and IT industry. However, it seems difficult for SMEs, Small-Giants and start-ups to follow the precise trends and indicators of the era in the 4th Industrial Revolution [2]. Among the AI industry groups, deep-running and speech-recognition are the most popular areas. Many companies invest and develop in this field, but it is not easy for start-ups and SMEs to survive. Many global companies have successfully developed interactive dialogue-based Chatbots using speech-recognition, but Korean speech-recognition based Chatbots are still poorly recognized than English Chatbots. The reason is that the UI was given more weight. The other is that the research perspective was different from the global one, due to AI research in Korea started later than global, and focused on only commercial aspects [1-3].
The goal of this study is to acquire user-oriented AI technology that has user-friendly interface and user-oriented usability. Therefore, it is necessary to implement the Chatbot system that can lead technological innovation by using accurate sentence analysis, syllable analysis, and automatic estimation word prediction method based on speech and text, and to secure technological ability to operate easily in Korean [2].
II. PREPARATION
Digital speech processing is classified into STT and TTS, that is, recognition and synthesis. Therefore, STT converts speech to text, and vice versa is TTS. STT is one of the hottest areas that have been continuously studied by many researchers. It also serves as an intermediary for dialogue between humans and robots. The reason why STT is attracting attention in AI industry is that it is applicable to various fields and it is one of the good tools to increase profit by fast and clear data processing [3,8].
In order to achieve the goal of this study, mobile applications developed from outside have been analyzed and the feasibility of utilizing the API has been examined. Based on this, practical problems were analyzed and the direction of development was determined. The external APIs to be analyzed is developed by best IT player in Korea such as KaKao, Naver, and ETRI. The advantage of the KaKao STT was obvious speech-recognition and clear and sophisticated word processing. However, it is not easy to systematic techniques in this study by benchmarking [2].
The advantage of ETRI STT was that it was able to analyze Korean sentences obviously and speed up data processing, but it was difficult to transplant to this study compared to other STTs because it used the basic interface.
For this study, various mobile devices such as Galaxy S7, Galaxy Note8, LG G6, Galaxy Tab A and LG V10 have been prepared. The main items tested were speech recognition rate and processing speed for each model. Further, WiFi and three mobile carrier’s networks were used to understand the diversity of the network [7].
MySQL and LINUX (Ubuntu, SSD Samsung 850, x86_64bit, intel-core i5-6600 @ CPU 3.30GHz) were used as database and server. The target application is a beverage ordering system, and the Chatbot engine will be implemented to use this application. The emphasis was on developing an engine that would make it easier to upgrade the application in the future. The reason for using many devices and servers during development is to minimize the inherent characteristic problems of each device [1].
The starting point of this study is the WebChatBot as shown in Fig. 1. This is one of the basic Chatbot systems. Hereinafter this shall be referred as a menu-driven method for convenience. The advantage of this system is that it gives users a clear choice. It is also an important advantage that users are encouraged to select only the choices shown in well-organized stories. However, the administrator had to make all standard choices in advance, which caused frequent network communications and took an average of 1~2 minutes to get the final results. Thus, a persistent problems are a slow response and consuming lots of network resources [3-5].
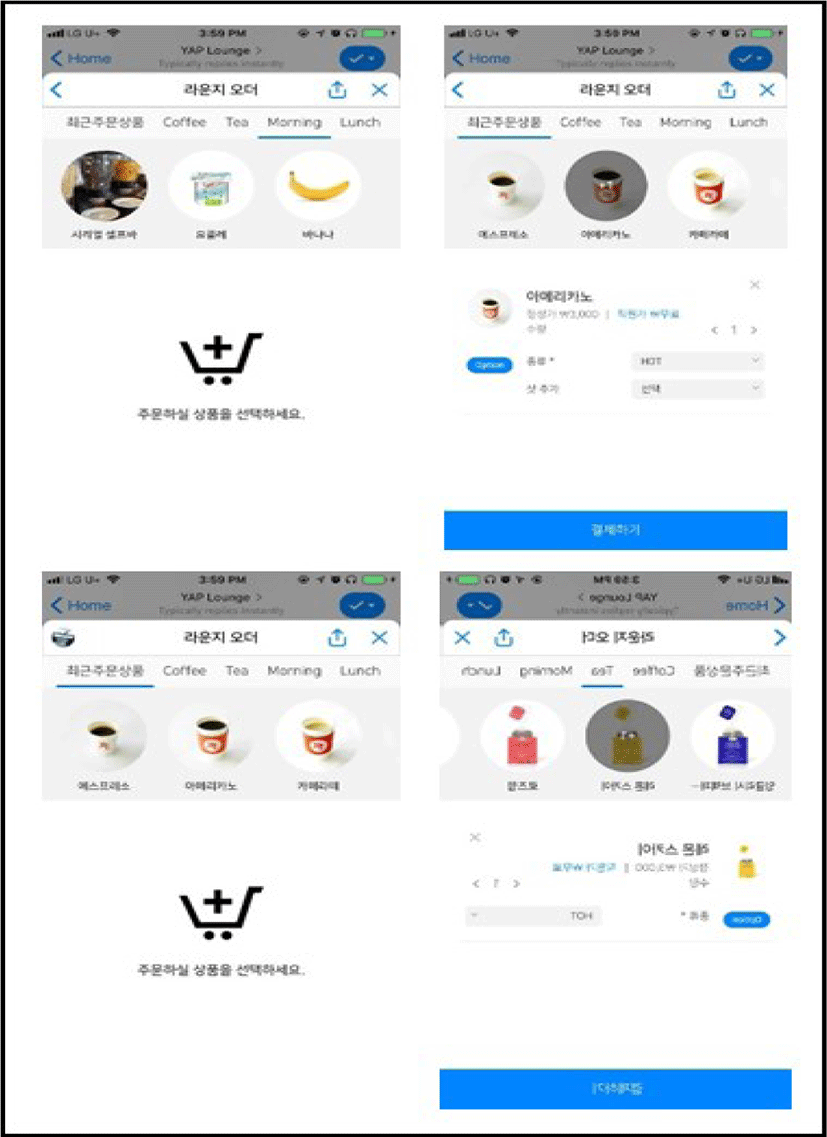
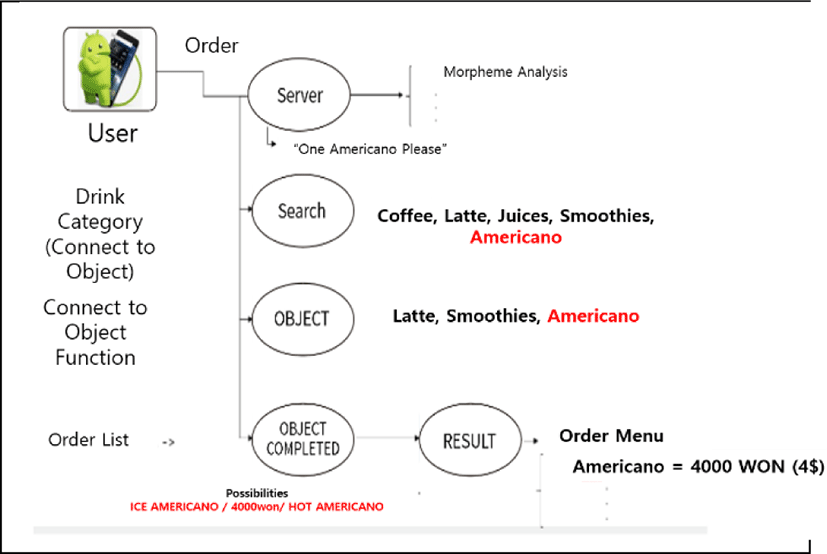
In order to overcome the problems of the menu-driven method, the study for speech-recognition method system has begun. If "Americano" is input by speech, it is designed to be able to distinguish objects, actions, and preferences as shown in Fig. 2.
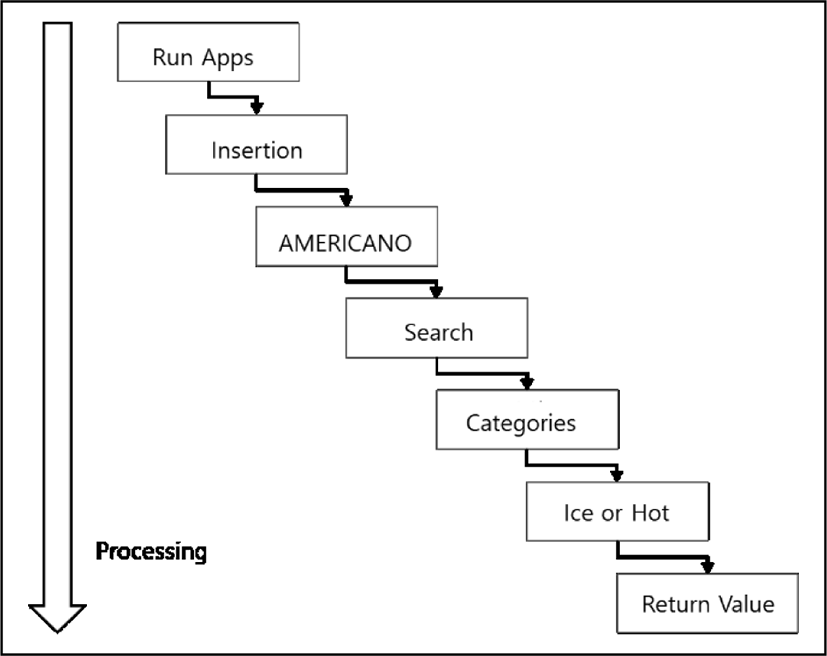
In other words, the menu-driven method consumes a long time and a lot of network resources because it is a method of sequentially generating an answer. On the other hand, the speech recognition method is designed to differentiate the process within one second as soon as the speech is input, and to receive accurate results even with a small number of searches [6].
III. DESIGN
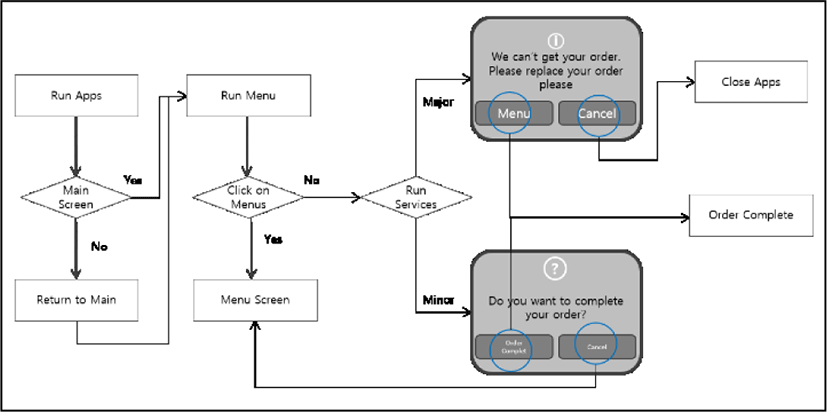
As shown in Fig. 3, the process is expanded after the user clicks on the application. The user service flowchart to show the main screen at launching the application so that the conversation can be made by voice. In addition, the user can select the food in the menu section by clicking on Text, not speech only. Application aimed for text and speech. [5]
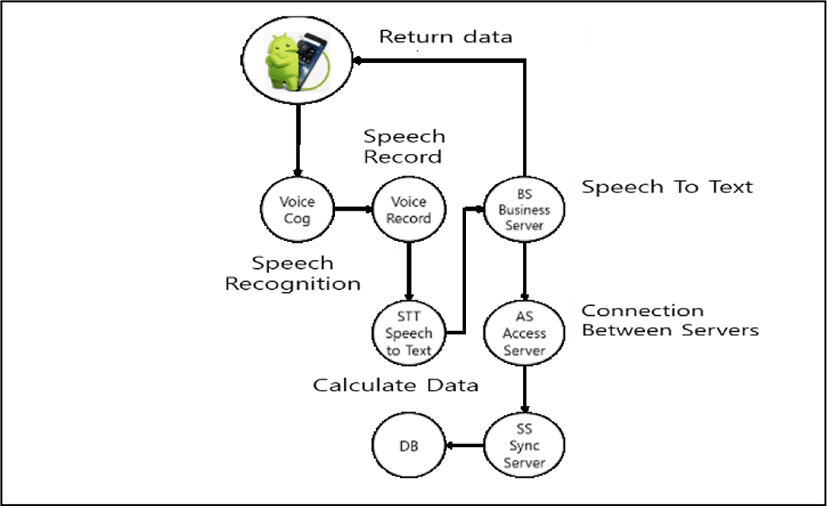
It is an extension of the overall module drawing of data in to the Fig. 4. Servers can combined as Synchronized Sever, Access Server, and Business Server etc. Each servers has different tasks handling. The unique role of Business Server can be explained as a “collection of algorithms”. It is also a conversation between the user and the server. The Access Server gives connection from the Business server and a link from the Synchronized Sever. Synchronized server is one the most important server. Synchronized Server has 2 basic roles in logic. First is connecting to databases. Second, they collect atypical data from Access server and return calculated values to Access Server. In this study, application allocated more than one servers because of avoiding bottleneck in the network. And also during development, operator can monitor dataflow from servers [3-4].
IV. COMPOSITION
In entire process, the blank exception handling of the received value will preferentially. Handling can be supported by program was used. And also system will return value as no spaces from insertion. For example, When “아~~~이스” (In English, I~~~ce) entered into the system, system will recognize as “아이스” with no spaces. The system has main constraint from insertion. The entire insertion of synonyms, system must collect at least two cases from insertion. When “커피” (In English, Coffee) entered into the system, the system will represent entire categories related with coffee. And also system will returned as “Smoothies”, “Lattés”,” Frappuccino, etc.” so user can perceivable their purposes. To do synonyms method, Algorithms classified into 4 cases “A.M.E.R.I.C.A.N.O” into 4 cases. “A.M.E”, “A.M.E.R.I”, “A.M.E.R.I.C.A”, “A.M.E.R.I.C.A.N.O”. When system continued to erase 4 cases, system will extract until “C.A.N.O”. Because, that is irregular data from user’s insertion. In this research, the system highly recommend to avoiding irregular data. It depends on Server’s accurate result value can be derived based on high perception. To do further algorithms on other methods, system will tried to find patterns from data. The patterned data always saved in Mass Map as shown in Fig. 6. The main reason for find data will be “collect information of the Object (target).”
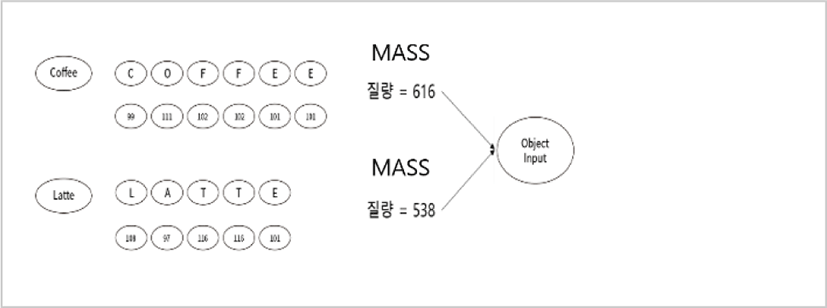
In this method, System will create one of a big map to collect ASCII code from mass map method. Mass map method calculate data structure algorithm that retrieves the basis of deliverables of the input prediction data. Retrieval method using a utilization scheme that extracts values from n parts of data around an infinite loop as a measure to clear data. In this method, system will distributing by one letter from insertion.
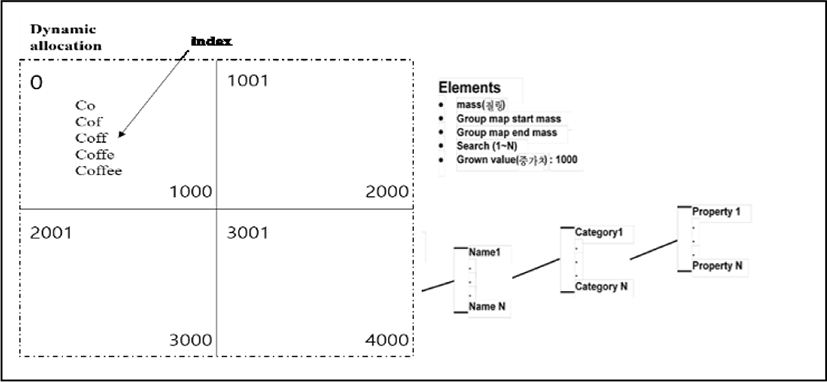
And also System will collect calculated data used by mass map. Based on algorithm, Data structure creates a multi-dimensional array to put ASCII code. For example, “C.O.F.F.E.E” can be specified C = 99, O=111, F = 102, F = 102, E = 101, E = 101, the total mass can be 616 in ASCII value. As we calculated those functions, we can specified patterned data. “Input Mass / increment = index of mass Map.” As shown in Fig. 6 and 7, System created multi-dimensional arrays to extract confidential patterns from data and system can access or find data in less search.
V. EVALUATION AND DISCUSSION
In this study, we performed the task of deriving the result with only ‘Object’ as the pilot version. Thus, we evaluated how many objects are in a sentence, and the ability to recognize and sort all of these objects. As mentioned earlier, the final goal was to classify this sentence into three if the sentence was entered. The first classification is an object. Therefore, it is difficult to interpret the whole sentence which is entered by speech only on this study. Therefore, in this basic study, it is only to find all the objects, recognize them, and evaluate the rate of recognition.
For example, when the speech “아이스 아메리카노 주세요” (Can I have an Ice-Americano?) is entered, the main object is to find a “Coffee”. If “Americano” is found, this is a 100% probability, due to which will be replaced by coffee. Of course, this sentence is incomplete. The complete sentence would be “아이스 아메리카노 커피 1 잔 주세요” (Can I have a cup of Ice-America Coffee?). Or rather “~~카노 주세요” (~~~ kano please) is somewhat unclear, but if it will be deduced the word “kano” as “Americano” and also replace it with "Coffee" and recognize it as an object, The probability is 100%.
In natural languages, objects always follow a lot of modifiers. For example, ‘dark’, ‘cool’, ‘warm’, ‘delicious’, or ‘not too much bitter’. This modifier thus changes the language to various feelings such as smooth, rough, dry, and so on. However, this modifier is a very cumbersome noise for algorithms. Therefore, filtering out all these modifiers is one of the important algorithms. Assuming that the just a dry sentence “커피 한잔 주세요” (Please give me a cup of coffee) is entered, this sentence is classified as “Object”, “Action”, “Preference”, ie, “coffee”, “give”, “a cup”. At this time, if only "coffee" is recognized as an object, the probability is 100%, but if “a cup” is also recognized as an object, its probability of recognition falls to 50%.
Therefore, although “cup” is recognized, algorithms must filter them out as “Preferences” rather than “Objects”. To evaluate this, 25 natural language sentences were enter as shown in Table 1, and the recognition rate of the object was evaluated.
As shown in Fig. 8, the dash line represents the total number of objects, and the dot line represents the number of recognized objects. And the solid line represents the probability.
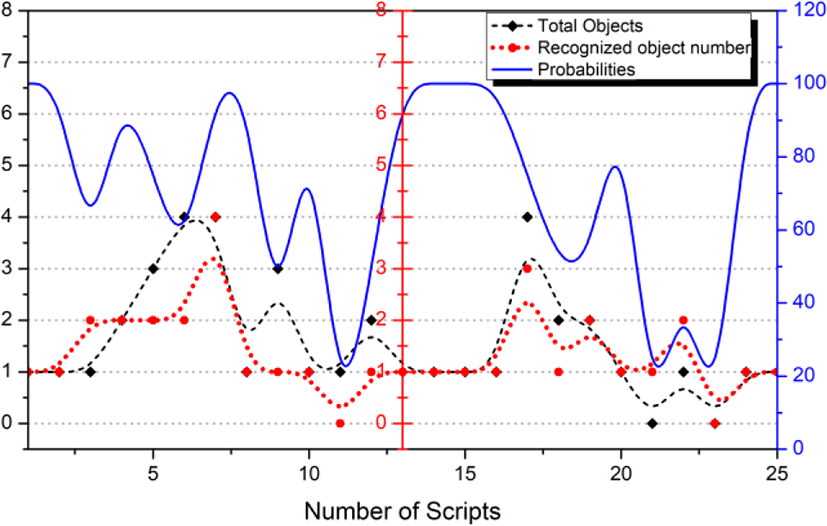
As described hereinabove, the recognition rate is close to 90%. Of course, this can be a high recognition rate because it is only for objects. However, it is expected that “Action” and “Preference” will show high recognition rate.
VI. CONCLUSION
In this study, the Korean sentences are defined in exactly three fields as Action, Object, and Properties. The result of object derivation performed with n numbers of algorithms but the system could not interpret it as a complete AI form. And also calculated-value could be little bit vague. However, if study added “Action” and “Properties”, system can make dialogue with fully-constructed paragraph.
This study is only a part of AI application. Due to interactions between human and AI, Our future study aimed to build perfect chatbot application for the ordering system. In the future study, we would expected that users can be able to use our technology and skills to have conversation with AI.