
I. INTRODUCTION
In recent years many object detection and classification algorithms are proposed. By using those algorithms, anyone can train their custom object for realtime detection. Human can instantly identify the object in an image at one look, but deep learning algorithm fails in many situations.
Vehicle logo is one of the most essential highlighted descriptors, which can furnish the astute activity framework with valuable data to distinctive vehicles. In past the Vehicle Manufacturer Recognition (VMR) was done using License Plate Recognition (LPR). But due to low picture quality LPR systems fails in different situation and have many detection errors due to the problem of character segmentation of license plate. Vehicle manufacturer recognition is getting more and more complex due to increase of different vehicle models in the market. The main difficulty of VMR is that there are many vehicle models today of almost same design and changing quickly overtime. Therefore, detection of the vehicle logos from various manufacturers is chosen as the main feature of the vehicle. VMR is a field with limited research, among which vehicle logo recognition [1] is widely used because logos are the unique point for the entire manufacturer.
In past many researchers applied different image featured algorithms and models but many of them were not robust in some complex images. In [2] a SIFT based method was proposed for vehicle logo detection and recognition. The system was enhanced by merging features using multiple images. They also used generalized Hough transformation for feature clustering and for affine transformation a generic verification was applied. In [3], the authors used 1200 logo images of 10 distinctive vehicle manufacturers to assess a SHIFT- based approach. Than an enhanced feature matching method was used by merging SIFT points from the provided sample logo. The accuracy presented in this method was 97%, however, the test images were close-up logo images and does not corresponds to street traffic cameras.
II. PROPOSED SYSTEM
In this study we are proposing advance VMR using deep learning. Here, two deep learning algorithms Faster R-CNN [4] and YOLO [5] is compared. This system is divided into two parts: (i) training data (ii) testing data. In training part, we have collected sample images of different vehicle manufacturer logos. In both deep learning algorithms same images were used while training. The training architecture is depicted in Fig.1.
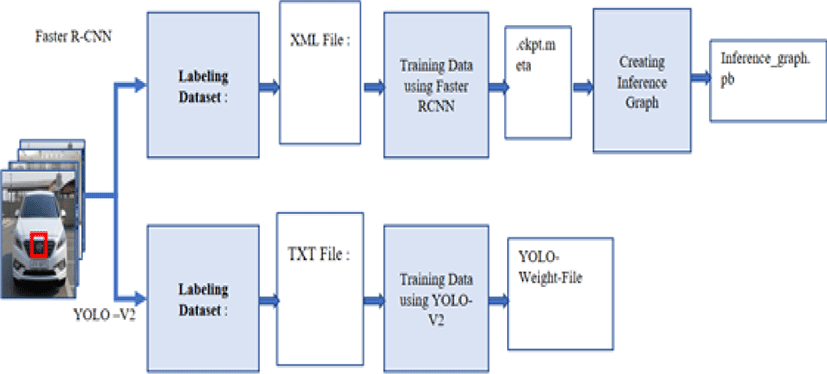
The training architecture of both Faster R-CNN and YOLO are shown in Fig. 1. All the sample images were labelled according to the class of vehicle manufacturer. We have labelled four classes, Hyundai, Kia, Samsung, SsangYong, Daewoo. After labelling, we have trained the image data with both the deep learning models.
Both the trained models were saved for testing images captured from traffic CCTV cameras. Before testing any images, we propose to pre-process each image. For image pre-processing we used advance Perspective Transformation (PT) [6] method through which we make the logo more distinct. PT is proposed because when the images are captured from traffic cameras the logos are not visible for all vehicle model. There is some brand where logos are installed on the bottom of the vehicle’s body. For perspective transformation, a 3x3 transformation matrix is required for processing. For matrix, 4 points are required from the input image and corresponding points. Direct linear transformation algorithm is being used to transform ) to with projection matrix M.
where t is the weight of the feature points. Equation (1) is the scalable variable. We can derive equation (3) from equation (2):
In projection matrix M, we must find 8 elements. If we know 4 pairs of source and destination point, then we can find projection matrix M.
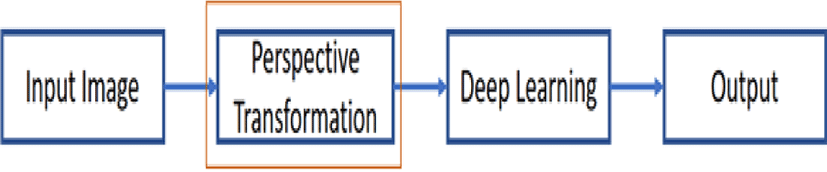
After PT, the transformed images are then used to find the logo of the manufacturer. Fig. 3 shows the architecture of testing process; all the input images are transformed initially before sending it to deep learning algorithm to detect and recognize vehicle manufacturer.

III. RESULT AND DISCUSSION
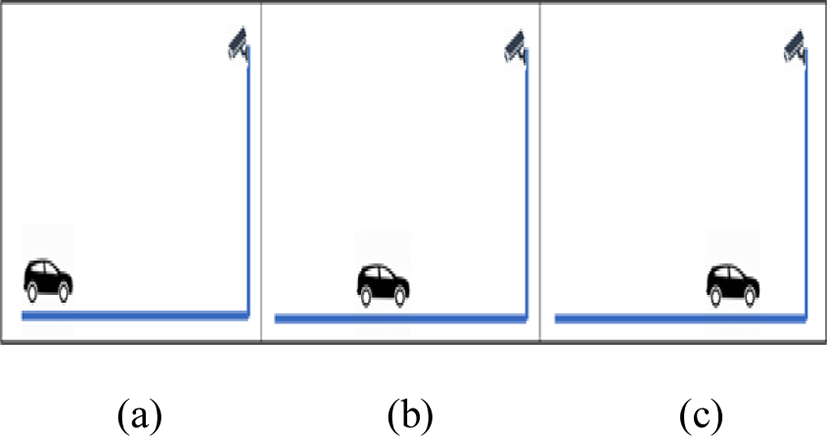
Traffic CCTV camera are generally installed on the top of the road therefore an area of interest must be defined to capture vehicle images . If the car images are taken from location Fig. 4(a), the picture quality is low therefore it’s very difficult for VMR. Vehicle images from Fig. 4(c) is viewed from top, so it is difficult to track the logo. We propose the location shown in Fig 4(b). From this location both front view logo and rear view logo of vehicles have higher detection rate after PT.
The proposed method is implemented on system with an Intel Core i7 CPU, 16GB memory, and GTX 2080 GPU.
Our training dataset consist of classes i) Hyundai with 500 images, ii) Kia with 300 images, iii) Samsung with 300 images, iv) SsangYong with 250 images v) Daewoo with 100 images. All the training data set were combination of front facing camera and few from area shown in Fig. 4(a). All the images were labelled and trained with both the deep learning algorithms.
After training, the trained models are used to test data received from traffic CCTV from the view location Fig. 4(b). To test our algorithm, we have collected vehicle images during day light and night of different vehicle brands as shown in Table 1. As shown in Fig. 5 and Fig. 6, Method 1 is the result of Faster R-CNN without perspective transformation of vehicle images. Method 2 is the result of Faster R-CNN after perspective transformation of vehicle images. Method 3 is the result of YOLO algorithm without perspective transformation of vehicle images. Method 4 is the result of YOLO algorithm after perspective transformation of vehicle images.
| Vehicle Manufacturer | Total Day Images | Total Night Images |
|---|---|---|
| Hyundai | 200 | 186 |
| Kia | 50 | 19 |
| Samsung | 50 | 14 |
| SsangYong | 50 | 10 |
| Daewoo | 10 | 3 |
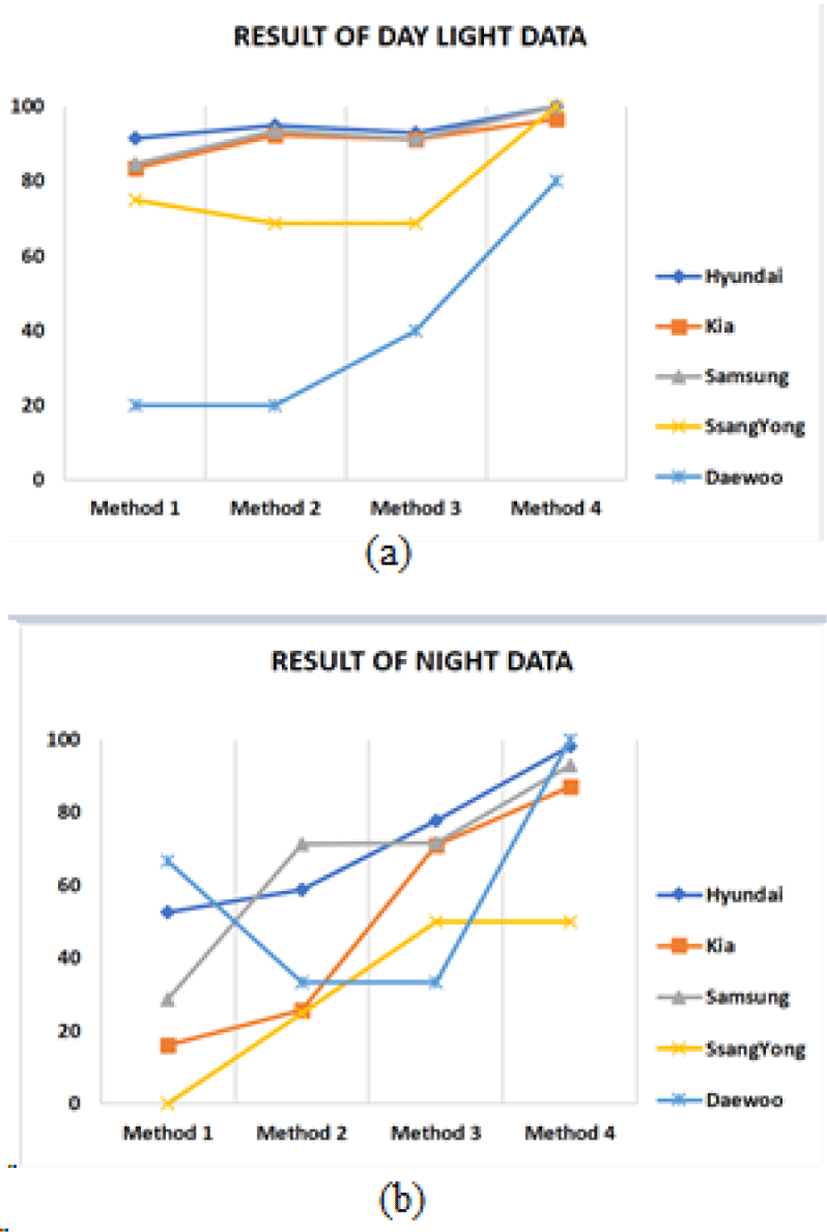
VMR is essential in many sectors, and many algorithms has shown significant results. When VMR is used for the images taken from a traffic camera, it is difficult to recognize due to various reason. As, shown in Fig. 5, method 1 has a good result but the result after PT has enhanced significantly in method 2. Furthermore, method 3 has a better result than method 1 and 2, but when PT is applied in method 3, the result has a drastic change.
As shown in Fig. 5, detection rate of Hyundai, Samsung, SsangYong in method 4 has reached to 100 percentage, whereas Daewoo has increased from 20 percentage in method 1 to 80 percentage in method 4. In night test data as shown in Fig. 6, the result has significantly changed from method 1 to method 4. In Table 2 all the results in percentage are shown from method 1 to method 4 on both day and night test data.
IV. CONCLUSION
This proposed system has compared two well-known object detection and recognition algorithm for vehicle manufacturer recognition. These object detection algorithms have good results but failed in some cases while detecting small objects such as vehicle logo from images captured from traffic cameras. To overcome the problem, we propose to apply perspective transformation algorithm to the images before applying it to deep learning algorithm. We also propose an area from where vehicle images need to capture. Among all the four methods, our proposed method 4 has best results on both day and night images.
There are some issues with night data as the picture quality is very low. In future, we plan to increase the picture quality of the images to detect and recognize vehicle logos.