
I. INTRODUCTION
China is a major producer and consumer of fur luxury goods. Fur products have also gone out of the exclusive rights of the rich and powerful, and the public’s demand for fur has increased year by year [1]. Fur products are increasingly close to people, and consumers’ preference for fur products is also on the rise year by year [2]. However, the identification of animal fur in the fur production process still relies on the visual identification of skilled workers, which is easily affected by external factors, and it is difficult to ensure the consistency and stability of the product [3-4]. The method of manual visual identification can no longer be matched with the automated fur production process [5]. Zhong Y. et al. studied fur recognition using the compound microscopy [6]. Zoccola M. et al. investigated near-infrared spectroscopy method and used this method for fur recognition [7]. Baichoo N. et al. achieved recognition by analyzing the DNA of fur [8]. Chen H. et al. investigated near-infrared spectroscopy and chemometric models for animal fur recognition [9]. Lu K. et al. verifies that the bag-of-words models and spatial pyramid match is an effective approach to identify the animal fur [10]. Vineis C. et al. studied fur recognition using peptide analysis by ultra-performance liquid chromatography/electrospray-mass spectrometry [11].
With the widespread use of image acquisition equipment, images have gradually become the main information exchange method for human beings, and a large number of image databases have been generated [12]. Relying on the value of big data, machine learning shows a wide range of applications in related fields [13]. A key step in the early stages of machine learning is to manually design a variety of effective features. The degree of discrimination of feature expression will have a decisive influence on the effect of the algorithm. Traditional methods usually rely on artificially designed features, which have many disadvantages [14]. For example, in the face of different scenes and different types of data, it is necessary to design different artificial features, resulting in high labor cost and time cost, and high requirements on experience of feature design [15-16]. Deep learning [17] is an emerging branch of machine learning. Instead of manually selecting features, deep learning uses several layers of networks to perform hierarchical feature extraction on input data and learns data features in this process.
With the rapid improvement of the computing capacity of computer hardware and the rapid popularization of large-capacity storage devices and graphics processors, neural network-based recognition algorithms have gradually become an emerging main direction [18-19]. Based on the research on animal neurons, Yann LeCun designed convolutional neural network in 1998. Drawing on the characteristics of multi-layer perceptron, the network used local connection and weight sharing to carry out calculation, which effectively reduced the parameter scale and greatly reduced the amount of calculation. Alex et al. proposed AlexNet model [20] in 2012, which raised much concern over convolutional neural network in the field of image processing. AlexNet network uses block convolution for parallel training. The Oxford Visual Geometry Group, together with Google Research, proposed the VGGNet network [21], among which VGG-16 network performed better in a number of classification tasks. Microsoft proposed ResNet network [22], which can train deeper networks through jumping connections between layers, so that the problem of gradient disappearance can be effectively alleviated.
In the image recognition task, the arrival of deep learning method has greatly improved the recognition accuracy. Deep learning does not need feature extraction and recognition training as two links, and can automatically extract effective features during training, with very strong feature extraction capability. Moreover, the model obtained after training has strong generalization, with rotation invariance and translation invariance. The weight sharing structure is the biggest characteristic of CNN, which greatly reduces the number of network parameters. CNN shows very good robustness and expansibility, but when CNN is needed to complete image recognition tasks, there will be problems such as gradient disappearance or gradient explosion and over-fitting. In the background of increasing production and consumption of fur, this paper studies the automatic recognition of fur in the process of animal fur production, and proposes an algorithm of animal fur recognition based on feature fusion network.
II. PROPOSED METHOD
Convolutional neural network is a machine learning model with strong adaptability, which is a kind of supervised learning. Based on the idea of biological neurons, the network adopts the structure of biological neural network and the way of weight sharing. By constantly extracting local features of data, the network gradually maps from shallow to deep to high-level feature space step by step, and then completes the classification task. A typical network structure is shown in Fig. 1. Convolutional neural network obtains the probability vector Y ∈ RC×1 through a series of hidden layer mappings. The length of the probability vector is C, where C represents the number of categories. Each value in vector Y corresponds to the probability of a class, and one-Hot encoding is adopted. Finally, the maximum value method is used to determine the category corresponding to the sample.
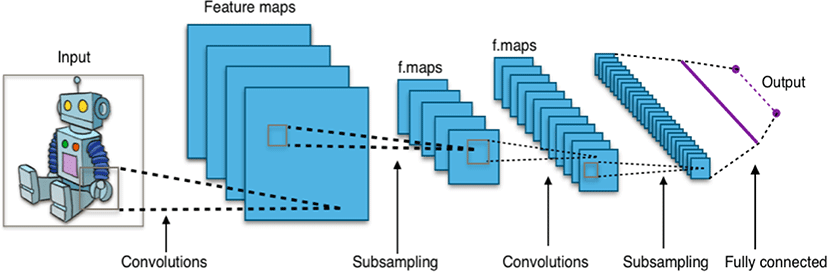
The hidden layer is composed of the following four parts:
(1) Convolutional layer: The main function of the convolutional layer is feature extraction. The feature map output by the convolutional layer is the result of the weighted summation of the feature map of the previous layer and the convolution kernel, and the addition of the bias term. The calculation formula is shown in formula (1), and the convolution operation can extract the local features of the image.
where b is the deviation, Z^l and Z^(l+1) are respectively l+1 layer feature maps, Z(i,j) is the feature map pixels, K is the number of corresponding channels, f is the size of the convolution kernel, s0 is the convolution stride (Stride), g is the non-linear activation function (Fig. 2).
(2) Activation function: The activation function makes nonlinear correction for each convolution. Commonly used activation functions include ReLU, Tanh and Sigmoid.
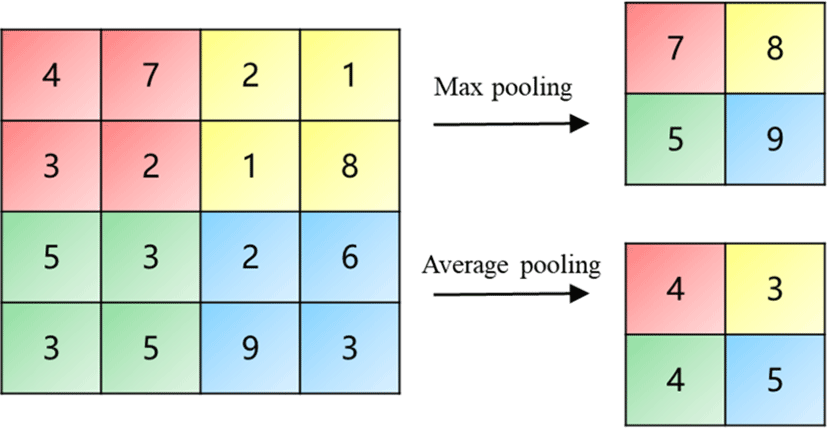
(3) Pooling layer: The pooling layer down-sampling the feature map. Down-sampling can reduce the computational complexity while maintaining the features. Pooling operations mainly include average pooling, maximum pooling, and random pooling, the last of which is less used.
Its general expression is formula (2).
In the formula, s0 is the step size, pixel (i,j), and p is the pre-specified parameter.
(4) Local response normalization layer (LRN): This layer performs the contrast normalization operation on the feature maps that have completed the pooling operation.
The ReLU function, also called the Rectifier function, is an activation function often used in neural networks. Its definition is shown in equation (3), and its derivative is defined in equation (4). The image is shown in Fig. 3:
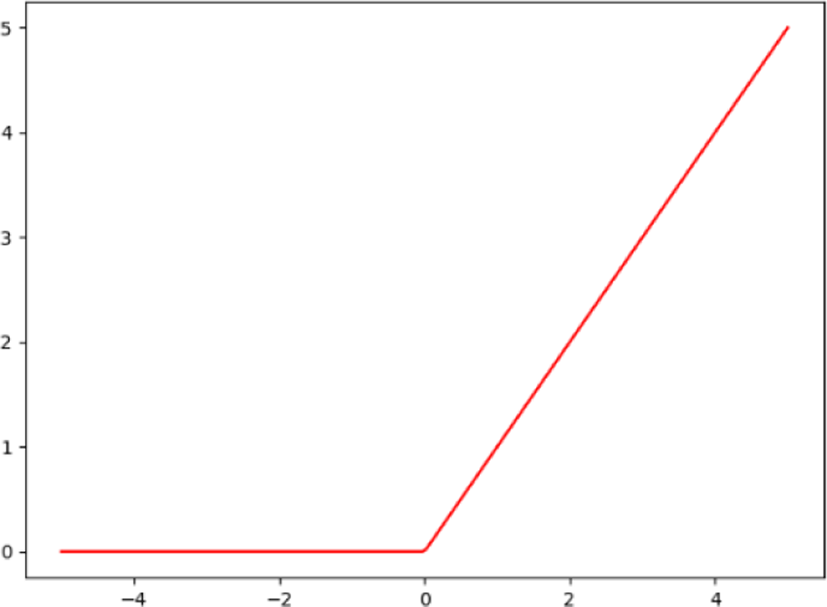
The unilateral suppression feature of ReLU can block the propagation of negative gradients and lead the network to a certain sparse expression ability. However, when the learning rate is large, it may cause a certain number of neurons in the network to irreversibly die, which seriously affects the performance of the network, as shown in formula (5). In order to improve the ReLU activation function, scholars proposed the Leaky ReLU function.
If xi<0, then ηΔωxi≪0, the output is 0 after passing the activation function, and the neuron output is always 0 in subsequent iterations.
Leaky ReLU, also known as the Leaky ReLU function, this activation function improves the shortcomings of the ReLU function that is relatively fragile during training. When the input x<0, the function assigns a non-zero slope a to all negative values, thus when the neuron’s corresponding value is negative, there can also be a non-zero gradient to update the parameters to avoid permanent inactivation. The Leaky ReLU function is shown in equation (6), and the function image is shown in Fig. 4.
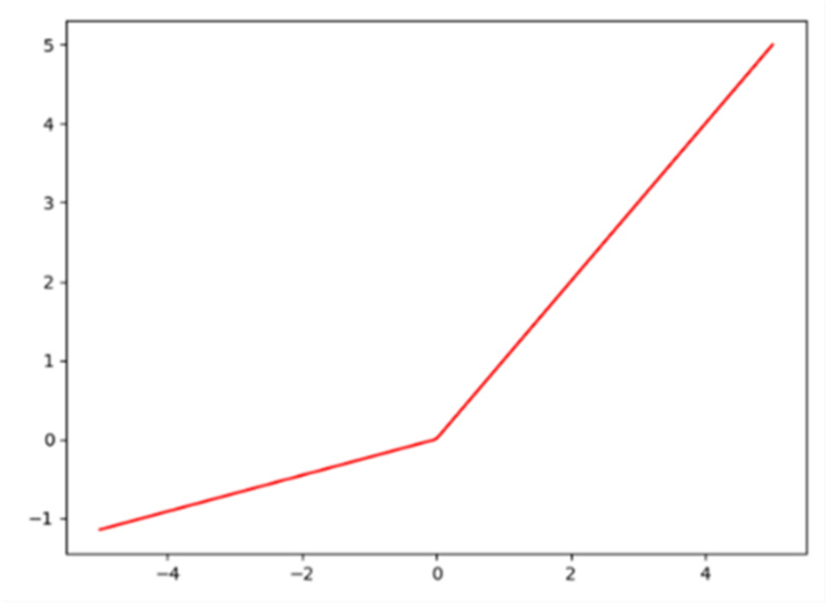
where a is a small constant.
Leaky ReLU uses some negative features, but its utilization is still not sufficient. Aiming at the problem of insufficient utilization of negative features by the activation function, the network model in this paper integrates negative features, as shown in Fig. 6 for details. Network, which is conducive to better use of negative features, can improve the accuracy of fur recognition.
Researchers have conducted a lot of studies on image texture information. Texture is the performance of the regular arrangement of image pixels, which is very stable, robust to environmental noise and lighting, and can not change due to image rotation and movement [23]. The LBP (local binary pattern) operator is a mainstream descriptor for quantitative analysis of texture information, and it is widely used. Its calculation method is based on a 3×3 area definition. The center value of the area is used as the threshold of the local area, and the surrounding 8 values are compared with the threshold to calculate the LBP value of the local area [24], as shown in Fig. 5. The calculation method is shown in formula (7) and (8). Combining the LBP information of multiple local areas will get the LBP feature map of the entire image. Therefore, changes in the texture features of small local areas will have an impact on the final overall feature situation.
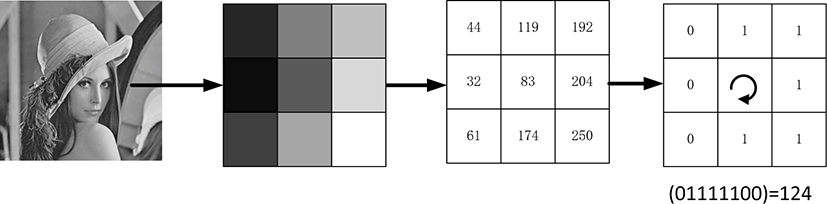
where (xa, yb) is the center point coordinates, p represents the p-th pixel in the neighborhood, ip is the gray value of the neighborhood pixel, ib is the gray value of the center point, and f(x) represents the symbolic function.
This article proposes an improved model design. We have three improvements to the first convolutional layer:
-
(1) The input image is fused with LBP feature map.
-
(2) Invert the feature map of first layer and fuse it with the feature map before the inversion to form a new feature map.
-
(3) The first layer of convolution uses the Leaky ReLU function to activate the new feature map.
The improvement in this paper can effectively integrate the texture features of the image, and effectively retain and increase the positive propagation of negative features, so as to have a positive impact on subsequent recognition and improve the accuracy of recognition. The subsequent convolutional layer, pooling layer, and fully connected layer are operated in a standard manner. The output of the fully connected layer is sent to the Softmax classifier, and finally the category of the fur image is obtained. The network structure of this article finally uses three convolutional layers and three pooling layers alternately, plus a fully connected layer, and finally uses the Softmax classifier to calculate the probability of the corresponding category of the fur. The network structure is shown in Fig. 6.
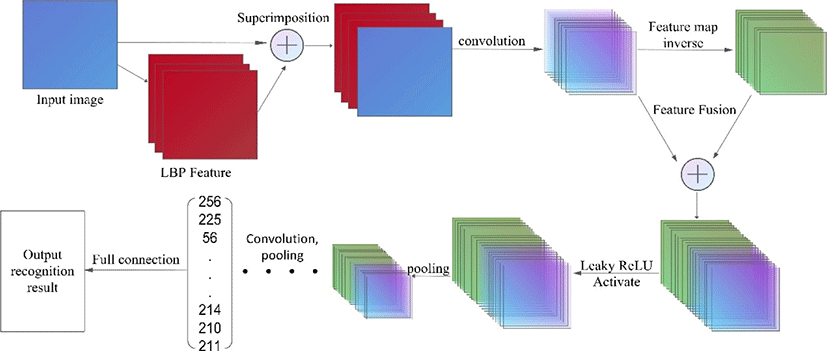
The algorithm flow of the feature fusion network is mainly divided into two stages of training and testing. In the network training stages. First, the network parameters are initialized, and then the final output result is calculated forward according to the initialized parameters, and the gradient is calculated backward according to the deviation between the output result and the true value. Update all parameters along the negative gradient direction, and then judge whether the end condition of training is reached. After the end condition is reached, the training phase is completed, and the network model is trained.
In the testing phase of the network, it is necessary to use the trained model to output the classification results according to the input test images. The process is shown in Algorithm 1.
Algorithm steps (network test phase)
Input: test image I
Output: category results i ∈ (1, N)
(1): Calculate the corresponding LBP feature maps of threesingle channels of the test image I.
(2): LBP feature maps and original image are superimposedand fused by channel dimension.
(3): Perform a convolution operation on the fused image to obtain the feature map of the first layer of convolution.
(4): Reverse the feature map of the first layer of convolution to obtain the corresponding negative feature map.
(5): The feature map of the first layer of convolution and the corresponding negative feature map are superimposed and fused by the channel dimension.
(6): Use the Leaky ReLU function to activate the fused feature map.
(7): Perform a pooling operation on the result after activation.
(8): Complete subsequent convolution and pooling operations.
(9): Pull the characteristic graph to the growth vector.
(10): Use the softmax classifier to output the classification results.
III. EXPERIMENTAL RESULTS AND ANALYSIS
The experiment in this article is performed on the Intel(R) Core i7-8700 CPU 3.20 GHz, the graphics card is RTX 2080Ti, and the operating system is 64bit Win10. The algorithm is completed on the PyTorch framework and implemented with Python 3.7.
The experiment in this paper was carried out with the animal fur dataset and the CIFAR-10 dataset respectively. The animal fur dataset uses the Fur_Recognition dataset, which contains more than 31,000 labeled images, the size of each image being 225×225, divided into training set and testing set. This dataset collected and established by our laboratory. The number of fur images in training set and testing set is 5:1 Divide. The dataset includes American sheep skin (AMS), Australian sheep skin (AUS), French rabbit skin (FRS), domestic rabbit skin (RAB) and domestic rex rabbit skin (REXRAB), 5 animal fur images, as shown in Fig. 7, classified according to the name, and generating a name library.

CIFAR-10 is a dataset for studying object recognition compiled by the Hinton artificial intelligence team. A single image is 32×32 in size, and each category includes 6,000 images. The data set is divided into 5:1 Divide. 50,000 images are used for training and 10,000 images are used for testing. The dataset contains RGB images of 10 types of objects such as truck, frog, deer, airplane, bird, ship, horse, dog, cat and automobile, as shown in Fig. 8. The details of the datasets are shown in Table 1.

LBP features can describe textures well and can effectively distinguish different types of fur images. We compare four different LBP operators through experiments. Table 2 compares the number of patterns of the four operators under three sampling situations , and .
| Original LBP | Round LBP | Rotation invariant mode | Equivalent model | |
|---|---|---|---|---|
| 256 | 256 | 9 | 59 | |
| - | 65536 | 17 | 243 | |
| - | 16777216 | 25 | 555 |
When we select LBP equivalent mode, the recognition accuracy is higher than other modes.
The initial learning rate of the network model in this paper is 1×10-4, and every 2 cycles, the learning rate decays by 0.2, the momentum factor is 0.99, and the weights are updated by backpropagation through stochastic gradient descent. Table 3 and Table 4 are the parameter settings of each layer applied to the fur data set and the CIFAR-10 dataset, respectively.
In order to determine the optimal size of the first-layer convolution kernel, this paper compares the effects of different size of the first-layer convolution kernel on the recognition accuracy throught experiments. For the fur dataset and the CIFAR-10 dataset, four first-layer convolution kernels are set respectively.
Calculate the corresponding recognition accuracy rate, as shown in Table 5. The experimental results show that for the fur dataset, when the first layer convolution kernel is set to 3×3, the recognition accuracy is the highest; for the CIFAR-10 dataset, when the first layer convolution kernel is 3×3 and 5×5, the recognition accuracy rate is relatively close. When the first layer convolution kernel is 5×5, the recognition accuracy rate is slightly higher.
| Dataset | The size of the first convolution kernel | Accuracy |
|---|---|---|
| Fur_Recognition dataset | 9×9 | 76.5 |
| 7×7 | 78.9 | |
| 5×5 | 80.6 | |
| 3×3 | 82.2 | |
| CIFAR-10 dataset | 9×9 | 75.7 |
| 7×7 | 78.8 | |
| 3×3 | 79.9 | |
| 5×5 | 80.5 |
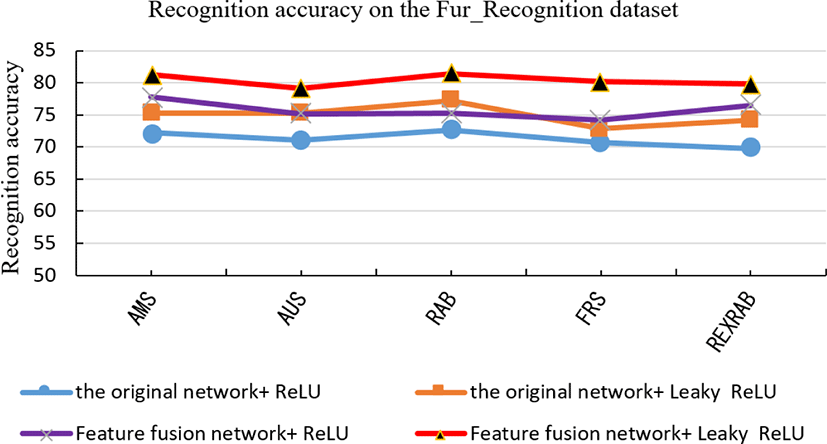
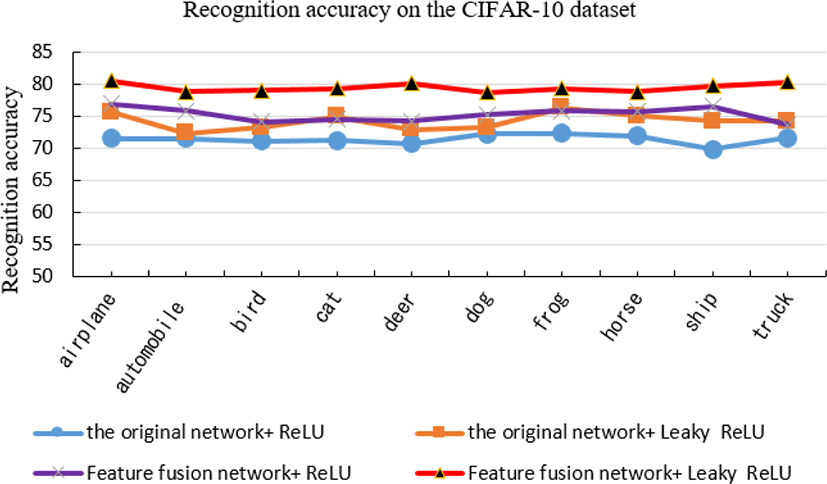
Through the comparative experiments on the Fur_ Recognition dataset and the CIFAR-10 dataset, it can be seen that when the original convolutional neural network is used and the ReLu function is used for the activation operation, the recognition accuracy is low. The experimental results are shown in Fig. 9 and Fig. 10. When the activation function is replaced with Leaky ReLU, the recognition accuracy is improved to a certain extent because some negative features are used. When the activation function is unchanged, the ReLU function is still used to activate, and the LBP feature is integrated before the first layer of the network convolution, and after the convolution is integrated into the inverted feature map, the accuracy is improved compared with the original network. On the fur dataset an increase of 4.18%, an increase of 3.23% on the CIFAR-10 dataset. When the feature fusion network is used, the LBP features and the features that are inverted after the first layer convolution are respectively integrated into the original network, and the ReLU function is replaced with Leaky ReLU to perform the activation function, the recognition accuracy improves greatly. Experimental results show that the algorithm improves the recognition accuracy by 9.08% on Fur_Recognition dataset and 6.41% on CIFAR-10 dataset. Table 6 shows the recognition accuracy of every category in the form of confusion matrix, which shows that the recognition accuracy of the algorithm in this paper is higher than that of the manual visual method in every category.
IV. CONCLUSION
This paper proposes an animal fur recognition network based on feature fusion. Compared with a typical convolutional neural network, this network extracts LBP features from the original image before the first layer of convolution, and integrates the original image channel dimension to participate in the convolution operation. After the first layer of convolution, by inverting the feature map and using the Leaky ReLU function to activate, the negative features are retained, which makes the feature information of forward propagation more abundant, and finally improves the accuracy of image recognition. This paper verifies the recognition effect of the network on two datasets, which are significantly higher than the typical original network. Applying this network to the fur production process can realize the automatic identification of fur, avoiding the problems of high labor cost, consistency and stability of the fur enterprise’s manual visual identification, and promoting the improvement of fur processing efficiency. The disadvantage is that the feature fusion idea of this article has not been tested on large-scale networks. In the next research, we will apply the two feature fusion methods plus the Leaky ReLU function to large-scale networks to address the problem of fur recognition on large-scale networks.




