
I. INTRODUCTION
Automatic license plate recognition (ALPR) systems are core components of intelligent transportation systems (ITS), playing an essential role in various public safety and administrative fields such as traffic surveillance, toll collection, parking management, and tracking of criminal vehicles. The rapid advancement of deep learning technologies, particularly the introduction of convolutional neural networks (CNNs), has revolutionized the performance of ALPR systems. For instance, YOLO-based object detection models have demonstrated exceptional performance in precisely detecting vehicles and license plates in real-time even in complex road environments [1], while efficiently designed End-to-End recognition models like LPRNet have succeeded in achieving high character recognition accuracy even on embedded devices with limited computational resources [2]. These technological advances have largely resolved the problem of license plate recognition in controlled environments.
However, most existing studies premise on high-resolution images where the distance to the camera is constant or lighting is favorable, showing limitations where performance degrades rapidly in unpredictable real-world scenarios. Images captured from a distance by surveillance cameras (CCTV) are inevitably in a low-resolution (LR) state lacking sufficient pixels, and contain motion blur caused by vehicle movement and various noises due to weather conditions such as rain and fog [3]. According to research results on recently released real-world datasets, these realistic degradation factors possess complex distributions fundamentally different from artificially generated Gaussian blur or simple downsampled data, becoming the primary cause of license plate recognition failures and reducing the practical reliability of ALPR systems [4].
To address this low-resolution problem, attempts have been actively made to apply super-resolution (SR) tech-nology as a preprocessing step; however, existing general-purpose SR models tend to focus excessively on mini-mizing pixel-wise reconstruction errors. Consequently, although the generated images may appear visually smooth, excessive over-smoothing occurs where the unique stroke structures or edge information of characters are blurred, which paradoxically hinders recognition performance [5].
Recently, methods explicitly utilizing character stroke information [6] or using text priors obtained from text recognizers as guides have been proposed [7], demon-strating the potential of semantic restoration. However, these methods have structural limitations, such as requiring large-scale computations or failing to support arbitrary rescaling, which is essential for the various shooting distances of CCTVs [8-9].
In this paper, to overcome these limitations, we propose stroke-aware flow for license plate recognition (SAF-LPR), a novel license plate restoration and recognition framework based on stroke-aware invertible neural networks. The proposed model adopts an Invertible Neural Network as a backbone to maximize the efficiency of original information preservation and noise separation [10-11], and integrates an adaptive degradation classifier to respond to complex degradations in real-world environments [12]. Furthermore, it is designed to inject geometric stroke information of characters into the restoration process [6] and use the lightweight recognizer LPRNet as a discriminator to generate images optimized for machine reading [4]. This ensures recognition accuracy beyond simple image quality improvement and supports arbitrary resolution transformation, maximizing usability in real-world surveillance systems.
II. RELATED WORK
Deep learning-based License Plate Recognition (LPR) systems have achieved remarkable growth over the past few years. Laroca et al. [1] proposed a robust LPR system utilizing the YOLO object detector, achieving high accuracy under various shooting conditions, while Zherzdev and Gruzdev [2] demonstrated real-time recognition capabilities on embedded devices through the lightweight architecture of LPRNet. However, a limitation of these models is their reliance on high-resolution, clear images for training and evaluation data. Recently, Nascimento et al. [3] released the UFPR-SR-Plates dataset collected from real surveillance environments, quantita-tively demonstrating that the performance of existing models degrades rapidly under real-world degradation conditions such as low resolution and blur.
This issue of low resolution is not unique to license plates but is a common challenge in intelligent surveillance, including Person Re-Identification (Re-ID). For instance, Liu et al. [13] recently proposed a framework enhancing Person Re-ID performance by integrating Super-Resolution technology, proving that restoring visual details is crucial for downstream recognition tasks in surveillance scenarios.
To address this in the LPR domain, Nascimento et al. [4] attempted a Character-Driven approach utilizing OCR model feedback as a loss function, but issues regarding computational efficiency in complex restoration processes and resolution mismatch due to varying distances remain unresolved.
In contrast to these studies, our work specifically targets the severe performance drop of standard LPR systems [1,2] under real-world conditions, as highlighted by recent benchmarks [3]. Unlike previous restoration attempts [4] that are limited by computational complexity and fixed-scale upsampling, our proposed SAF-LPR provides a unified and efficient solution capable of handling complex, compound degradations and arbitrary resolution changes inherent in varying surveillance distances.
To enhance the readability of low-resolution text images, research utilizing structural characteristics of characters beyond simple pixel restoration has been actively conducted. Chen et al. [6] proposed the Text Gestalt model mimicking human cognitive processes, improving recognition performance by recovering incomplete stroke information. Furthermore, Ma et al. [7] presented the TPGSR framework generating semantically valid images by utilizing the probability sequence of text recognizers as a text prior, and Guan et al. [14] enhanced text consistency by combining OCR post-processing into the document restoration pipeline. In the license plate domain, Wang et al.[5]improved the sharpness of character contours through a neural network emphasizing edge information. However, these methods suffer from slow inference speeds due to being based on large-scale Transformers or involving multi-stage processing, and they face difficulties in balancing pixel-wise fidelity and semantic recognition rates.
Distinct from these existing semantic-aware approaches [5-7,14] which often rely on heavy computational structures like Transformers or complex multi-stage pipelines, our approach integrates stroke priors and semantic feedback into a highly efficient invertible framework. This unique integration allows SAF-LPR to achieve state-of-the-art restoration quality and recognition accuracy while maintaining fast inference speeds suitable for practical applications, effectively resolving the trade-off between pixel fidelity and semantic recoverability.
Invertible neural networks (INNs) are gaining attention in image generation and restoration fields due to their ability to minimize information loss by learning bijective mappings between input and output. Foundational work by Dinh et al. [15-16] with NICE and RealNVP, and Kingma and Dhariwal [17] with Glow, established the theoretical basis for invertible flow-based generative models. Applying this to image restoration, Liu et al. [10]'s InvDN achieved both lightweight architecture and high performance by effectively separating noise in the latent space, while Jing et al. [18]'s HiNet and Xie et al. [19]'s Inv-Compress demonstrated the superior information presservation capabilities of INNs in information hiding and compression. Recently, Xiao et al. [8] and Li et al. [11] improved performance in rescaling problems by intro-ducing invertible residual connections, yet most were limited to supporting fixed scaling factors. To overcome this, Pan et al. [9] proposed IARN capable of arbitrary rescaling, but it failed to incorporate structural information specific to domains like text or license plates. Additionally, Park et al. [12] proposed adaptive filters responding to complex degradations, but this tends to increase model complexity. Based on the efficiency of INNs and arbitrary scaling technology, our SAF-LPR presents a license plate restoration solution optimized for real-world environments by integrating stroke information and recognizer feedback.
Building upon the efficiency of INNs [10] and recent advancements in arbitrary rescaling [9], the core originality of our work lies in tailoring this architecture specifically for license plate recognition. Unlike generic INN-based restoration methods that lack domain-specific guidance [9,11], we propose a novel mechanism to inject explicit stroke structure priors and semantic acknowledgment feedback directly into the invertible flow. This unique combination enables SAF-LPR to handle complex real-world degradations and arbitrary scale changes efficiently, surpassing the limitations of previous generic approaches.
III. METHODOLOGY
In this paper, to effectively handle the non-linear and complex degradations occurring in real-world CCTV environments, we propose a Deep Invertible Residual Pyramid Network based on the “Invertible Weight Transfer” strategy. As shown in Fig. 1, the proposed framework consists of a two-stage learning process.
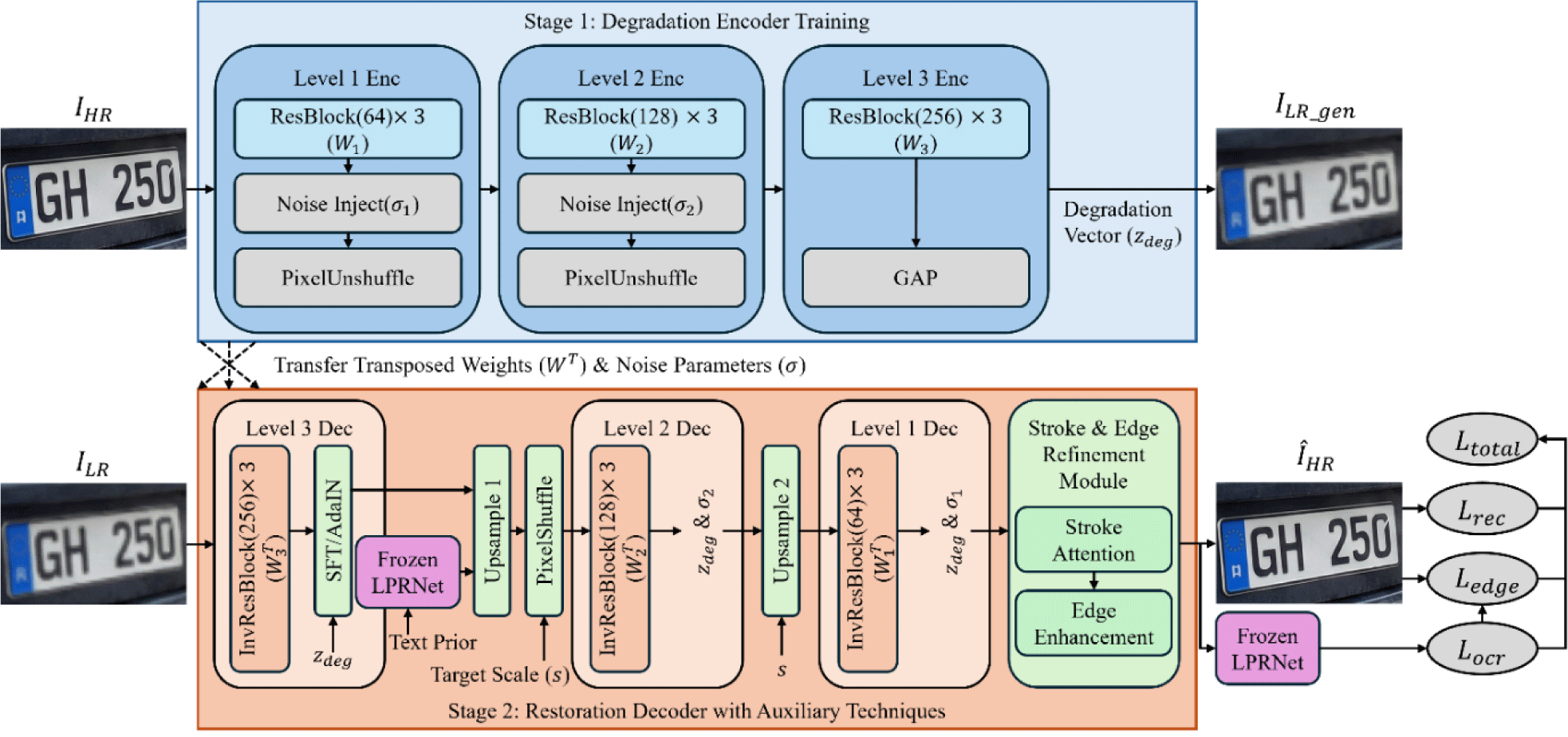
The first stage (Stage 1) is the “Degradation Learning Phase.” Here, we train an encoder (E) that transforms high-resolution (HR) images into low-resolution (LR) ones to model the physical degradation patterns (blur, noise, downsampling characteristics) of the real environment. The weights and noise parameters extracted during this process contain key clues for the inverse operation of the degradation process.
The second stage (Stage 2) is the “Invertible Restoration & Refinement Phase.” The weights of the encoder trained in Stage 1 are transposed and transferred as initial values for the restoration decoder (D). This allows the decoder to start training from a state close to the inverse process of degradation, rather than a random state, thereby drastically improving convergence speed and restoration accuracy. Subsequently, recognition rates are optimized through finetuning that combines text priors and stroke information.
The goal of Stage 1 is to train an encoder E that takes IHR as input and generates similar to the real ILR, using a real-world HR-LR image pair dataset D = {(IHR, ILR)}. Unlike simple Bicubic downsampling, this encoder learns non-linear real-world degradations through Noise injection and residual blocks (ResBlock) within the network.
The encoder has a pyramid structure consisting of L levels to capture multi-scale information. Each level l consists of N residual blocks and one downsampling layer. To minimize information loss and ensure invertibility, we use the PixelUnshuffle operation instead of traditional pooling to move spatial resolution to the channel dimension.
To simulate sensor noise specific to CCTVs, we inject learnable Gaussian noise into the output of each residual block.
Here, σ is a learnable scalar parameter that self-learns the optimal noise intensity for each layer.
We apply Global Average Pooling (GAP) to the output FL of the last level of the encoder to extract a Degradation Vector zdeg that summarizes the degradation characterristics of the entire image (e.g., degree of blur, lighting conditions).
This zdeg is used as a condition for Adaptive Modulation in the Stage 2 restoration process. Once Stage 1 training is complete, all weights WE and noise parameters σ of the encoder are frozen and transferred to Stage 2.
Stage 2 is the process of restoring the low-resolution input ILR to high-resolution IHR based on the degradation information learned in Stage 1. This stage consists of decoder initialization via Weight Transfer and an Active Refinement process.
Instead of randomly initializing the restoration decoder D, we configure it as a ‘mirror image’ of the Stage 1 encoder E. The weights of the convolution filters at the l-th level of the encoder are transposed to set the initial weights of the corresponding level in the decoder.
Furthermore, the noise parameters σ learned in Stage 1 are also transferred to the decoder, serving as thresholds or regularization parameters for denoising during the restor-ation process. This transfer strategy enables the decoder to start training from a state close to the inverse operation of physical degradation, accelerating convergence.
The decoder progressively restores resolution through PixelShuffle operations. To accommodate various CCTV shooting distances, we apply Arbitrary Scale Rescaling techniques. The target scale and relative coordinate grid Crel are injected as conditions to interpolate the image at continuous scales rather than fixed factors (e.g., x 4) [9].
Simultaneously, the degradation vector zdeg extracted in Stage 1 modulates each residual block of the decoder via spatial feature transform (SFT) layers. This adaptively alters the filter characteristics according to the degradation state (rain, blur, etc.) of the input image [12].
Physical restoration alone is often insufficient to perfectly recover severely damaged characters. Therefore, we add semantic guidance. The intermediately restored feature maps are fed into LPRNet to generate a character probability sequence Pocr, which is then fed back into the decoder's bottleneck to assist contextual restoration [7]. Finally, the Stroke Attention Module calculates the correlation between the restored features and predefined stroke templates Tstroke to sharpen the character contours [6].
In Stage 2 training, only the decoder parameters are updated (while the encoder and LPRNet are frozen), minimizing the weighted sum of the following three loss functions.
To reduce pixel-level differences between the restored image ĨHR and the ground truth IHR, we use the Charbonnier Loss, which is robust to outliers.
To enhance high-frequency components that determine character readability, we calculate the L1 distance between edge maps extracted using filters such as Sobel [5].
To directly optimize recognition performance, we use the frozen LPRNet as a discriminator. This comprises Perceptual Loss, which measures the distance between feature maps, and connectionist temporal classification (CTC). Loss, which improves the accuracy of the predicted text sequence [2,4].
IV. EXPERIMENTS
Since the core objective of this study is to improve license plate recognition performance in real-world environments, we used the recently released UFPR-SR-Plates [3] as our benchmark dataset. This dataset consists of images collected from real surveillance camera environ-ments and includes realistic degradation factors such as resolution reduction due to distance, motion blur, and various lighting conditions. For the experiment, we classified the dataset into three groups (Easy, Medium, and Hard) according to difficulty. Additionally, to enhance the generalization performance of degradation patterns in the initial training phase (Stage 1), we utilized synthetic data created by adding artificial noise and blur to the high-resolution license plate dataset, CCPD, as an auxiliary resource [1].
The proposed SAF-LPR model was implemented using the PyTorch framework and trained on two NVIDIA A100 GPUs. For the Stage 1 (degradation encoder) training, the learning rate was set to 1 x 10−4 for 200 epochs. In Stage 2 (Restoration Decoder), fine-tuning was performed with a lower learning rate of 5 x 10−5 after weight transfer. We used the AdamW optimizer with a batch size of 32. For evaluation metrics, we used peak signal-to-noise ratio (PSNR) and structural similarity index map (SSIM) to measure image quality, and adopted recognition accuracy (RA) using a pre-trained LPRNet [2] as the primary metric to verify actual recognition performance.
To verify the performance of the proposed method, we conducted comparative experiments with representative image super-resolution models (Bicubic, SwinIR) and text/license plate-specific restoration models (Text Gestalt [6], TPGSR [7], EENN [5]). Table 1 presents the quantitative evaluation results for the ‘Hard’ difficulty level of the UFPR-SR-Plates dataset. The general-purpose SR model, SwinIR, recorded high PSNR but showed low recognition accuracy (RA). This implies that pixel-level restoration does not guarantee the structural shape of characters. On the other hand, text-specific models like Text Gestalt and TPGSR showed improvements in recognition rates, but the proposed SAF-LPR outperformed them by over 4.6% in recognition accuracy. In particular, we confirmed that the combination of stroke information and the information preservation capability of the invertible neural network enabled the restoration of clear contours even in severely blurred characters.
| Methods | Category | PSNR(dB)↑ | SSIM↑ | Recognition accuracy (RA, %) |
|---|---|---|---|---|
| Bicubic | Interpolation | 22.45 | 0.612 | 45.3 |
| SwinIR | General SR | 26.80 | 0.785 | 62.1 |
| Text Gestalt [6] | Scene text SR | 25.12 | 0.741 | 75.8 |
| TPGSR [7] | Scene text SR | 25.95 | 0.766 | 81.2 |
| EENN [5] | License plate SR | 26.10 | 0.772 | 83.5 |
| SAF-LPR (Ours) | License plate SR | 26.11 | 0.780 | 88.1 |
Qualitative evaluation also reveals the superiority of SAF-LPR. As shown in the comparison results in Fig. 2, SAF-LPR effectively suppressed noise based on the degradation information learned in Stage 1 and clearly distinguished fine stroke differences in easily confused characters such as ‘3’ and ‘8’. This demonstrates that the LPRNet-based semantic feedback successfully balanced visual quality and machine readability.

We conducted an ablation study to analyze the impact of each component of the proposed framework on performance.
First, we verified the validity of the Stage 1 degradation learning and weight transfer strategy. Compared to training with a randomly initialized decoder (Random Init), applying Weight Transfer resulted in approximately 2.5 times faster convergence speed and a 0.8 dB improvement in final PSNR. This implies that the physical patterns of degradation learned by the encoder were transferred to the decoder in a transposed form, acting as a strong prior for solving the inverse problem.
Next, we evaluated the contribution of the Stroke Attention module and OCR loss (Locr). As summarized in Table 2, when using only Lrec on the base invertible neural network (Base INN), character shapes were restored blurrily, resulting in a low recognition rate (78.2%). Adding Stroke Attention sharpened character contours, increasing the recognition rate to 85.4%, and finally, when combined with LPRNet feedback (Locr), the recognition rate reached 88.1%. This demonstrates that adding semantic guidance on top of physical restoration is essential for maximizing LPR performance.
V. CONCLUSION
In this paper, we proposed SAF-LPR, a novel stroke-aware invertible neural network framework, to overcome the performance degradation of automatic license plate recognition (ALPR) systems caused by low resolution and complex degradations in real-world CCTV environments. To explicitly reflect the physical characteristics of the actual degradation process often overlooked by existing superresolution techniques, we introduced an “Invertible Weight Transfer” strategy combining deep residual pyramid structures with noise injection.
The proposed two-stage learning methodology provided strong physical prior knowledge for solving the inverse problem by transposing the filters of the degradation encoder trained in Stage 1 and utilizing them as initial values for the Stage 2 restoration decoder. Upon this robust baseline, we integrated arbitrary scale rescaling and adaptive degradation modulation technologies to flexibly respond to varying shooting distances and weather conditions. Finally, by applying a semantic feedback loop based on stroke attention and text priors, we generated optimal images that are best readable by recognizers, going beyond simple image quality improvement.
Extensive experimental results on the real-world UFPR-SR-Plates dataset demonstrated that SAF-LPR achieves superior performance compared to existing general-purpose and specialized SOTA models, not only in quantitative image quality metrics such as PSNR and SSIM but also in the most crucial Recognition Accuracy. Qualitative evaluations also confirmed that unlike competing models that generate artifacts or blur characters, the proposed model achieves an ideal balance between visual quality and machine readability by restoring clear stroke structures even in severely damaged characters.
For future work, we plan to extend the Stage 1 encoder training method to unsupervised or GAN-based approaches to effectively learn degradation characteristics even from unpaired real data. Furthermore, we aim to verify real-time inference capabilities on edge devices with limited resources through model lightening and computational optimization, and explore generalization possibilities beyond vehicle license plates to various scene text restoration fields.

