I. INTRODUCTION
The ability to recognize a person is a task that human risibly performs but one that computers to date have been unable to perform robustly. For the automatic user identification or surveillance, various researches using human face information are performed using biometric information (fingerprint, face, iris, voice, vein, etc.) [1]. In a biometric identification system, the face recognition with a non-touch style is a very challenging research area, next to the fingerprint. Many different human face recognition algorithms have been developed and motivated by the face recognition is non-touch style, for the last 30 years [1]. There are several problems that are easily influenced by lighting illuminance and encountered difficulties when the face is angled away from the camera, especially in two dimensional face recognition systems. To solve these problems, a 3D face recognition system using stereo matching, laser scanner and etc. has been developed [2-3].
Broadly speaking, two approaches have emerged to recognize the face. One type employs the facial feature based approach and the other is the area based approach [4-5]. Recently, as the 3D system is being cheaper, smaller, and faster than it used to be, the research on the 3D face image is performed more actively [2-3]. Many researchers have used differential geometry tools for computing the curvatures in 3D face [6]. Hiromi et al. [7] treated the problem of 3D shape recognition with rigid free-form surfaces. Each face in the input images and the model database are represented as an Extended Gaussian Image (EGI), constructed by mapping principal curvatures and their directions. Gordon [8] presented the study of face recognition based on depth and curvature features. To find face specific descriptors, he used the curvatures of the face. Comparison of the two faces was made based on the relationship between the spacing of the features. Lee and Milios [9] extracted the convex regions of the face by segmenting the range of the images based on the sign of the mean and Gaussian curvature at each point. For each of these convex regions, the Extended Gaussian Image (EGI) was extracted and then used to match the facial features of the two face images. One of the most successful techniques of the face recognition as statistical method is principal component analysis (PCA), specifically eigenfaces [10-11]. However, it is not ideal for classification purpose as it retains unwanted variations occurring due to diversified face shape and face poses. To overcome this problem, proposed method was an enhancement known as the Fisherface method, or Fisher’s linear discriminant (FLD), linear discriminant analysis (LDA) [12]. Especially, Zhao et al. [22] suggested multiple feature domains based on the face recognition using the FLD through the dividing (4 types) of an original image.
The single characteristics, widely used to detect pedestrians and objects, are incorporated edge [13], appearance [14], local binary pattern (LBP) [15], histogram of oriented gradients (HOG) [16], Haar-like [17] and wavelet coefficient [18]. HOG characteristics or improved HOG characteristics are widely utilized in the methods for the recognizing pedestrians by using the automobile vision. Zhu et al. [19] applied the HOG characteristics based on variable block size to improve detection speed. Further, Watanabe et al. [20] utilized co-occurrence HOG characteristics, and Wang et al. [21] utilized HOG-LBP human detection to improve detection accuracy.
In this paper, a novel face recognition method is introduced using the face curvatures and histogram of gradients oriented algorithm presented well personal characteristics and reduced the feature dimension. Moreover, the normalized facial pose images using SVD are considered to improve the recognition rate, as the preprocessing.
This paper is organized as follow. In section II, this paper explains the face pose normalization to improve the recognition rate. Section III describes the face surface curvature and HOG including personal feature information. To classify the person, linear discriminant analysis is introduced in section IV. The results of their evaluation and a detailed performance analysis are presented in section V. Section VI concludes this paper.
II. Face Pose Normalization [22]
The nose is protruded shape and located in the middle of the face. So it can be used as the reference point, firstly we tried to find the nose tip using the iterative selection method, after extraction of the face from the 3D face image [23]. Usually, face recognition systems suffer from drastic losses in performance when the face is not correctly oriented. The normalization process proposed here is a sequential procedure that aims at putting the face shapes in a standard spatial position. The processing sequence is panning, rotation and tilting.
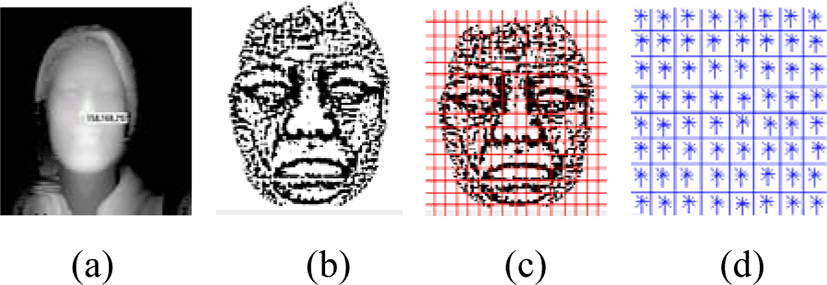
In preprocessing, a given 3D image is divided into face and background areas. Useless areas around the head and clothing parts contain too much erroneous data to process. Firstly, the nose tip is found by the iteration selection method(ISM) after using Sobel processing, as shown in Figure 1 (b).
where M and N represent the size of the image. And P stands for the depth image and B is the binary image. In the result area, the new threshold value is calculated by using an average, and the new area is extracted by using P. By the repeated processes (1), the nose tip point can be found as the highest value on the range face. The results are shown in Figure 1 (c).

In feature recognition of 3D faces, one has to take into consideration the obtained frontal posture. Face recognition systems suffer from drastic losses in performance when the face is not correctly oriented [24]. The normalization process proposed here is a sequential procedure that aims at putting the face shapes in a standard spatial position. Obtained face poses consist of front, right rotation, left rotation, right panning, left panning, up tilt, and down tilt.
If the pose transform matrix is AP (P = RL, RR, PL, PR, TU, TD), AP can be calculated with equation (2).
where CPF is transformed front pose for each pose, CP means left rotation (RL), right rotation (RR), left panning (PL), right panning (PR), up tilt (TU), and down tilt (TD), which has PCA coefficient matrix for all the training sets. C+ is the pseudo inverse matrix using Singular Value Decomposition (SVD) for the matrix . The reason why we have to use is that it is difficult to get the reverse matrix from the matrix which has no square matrix. The equation (3) explains the brief algorithm for the pose transform.
III. Surface Curvature and HOG
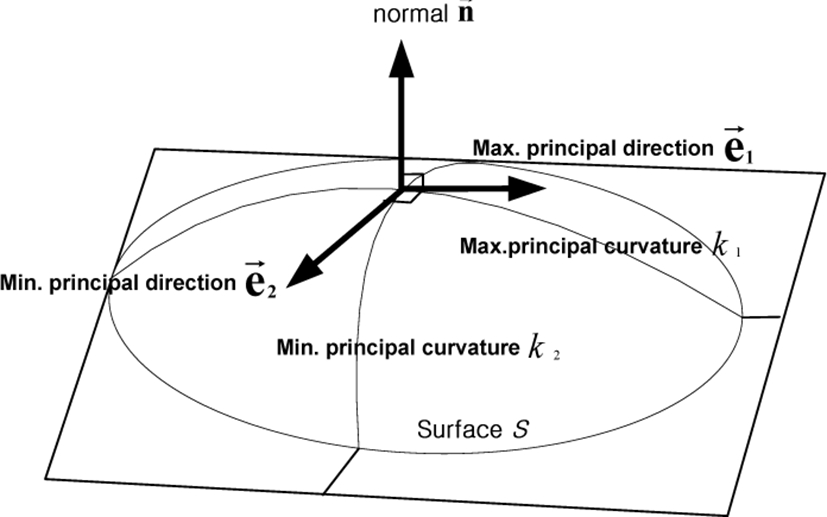
For each data point on the facial surface, the principal, Gaussian and mean curvatures are calculated and the signs of those (positive, negative and zero) are used to determine the surface type at every point. The z(x, y) image represents a surface where the individual Z-values are surface depth information. The curvatures and related variables are computed for the pixel at location . Each pixel has an intensity value, a gray ton value or a depth value z(x, y). These intensity values define a surface in a three dimensional space as shown in Figure 2.
Here, x and y are the two spatial coordinates. We now closely follow the formalism introduced by Peet and Sahota [25], and specify any point on the surface by its position vector:
The first fundamental form of the surface is the expression for the element of arc length of curves on the surface which pass through the point under consideration. It is given by:
where
The second fundamental form arises from the curvature of these curves at the point of interest and in the given direction:
where
and
Casting the above expression into matrix form with;
the two fundamental forms become:
Then the curvature of the surface in the direction defined by V is given by:
Extreme values of k are given by the solution to the eigenvalue problem:
or
which gives the following expressions for k1 and k2, the minimum and maximum curvatures, respectively:
Here we have ignored the directional information related to k1 and k2, and chosen k2 to be the larger of the two. For the present work, however, this has not been done. The two quantities, k1 and k2, are invariant under rigid motions of the surface. This is a desirable property for us since the cell nuclei have no predefined orientation on the slide (the x – y plane).
The Gaussian curvature K and the mean curvature M are defined by
which gives k1 and k2, the minimum and maximum curvatures, respectively. It turns out that the principal curvatures, k1 and k2, and Gaussian are best suited to the detailed characterization for the facial surface, as illustrated in Fig. 1. For the simple facet model of the second order polynomial of the form, i.e. a 3 by 3 window implementation in our range images, the local region around the surface is approximated by a quadric
and the practical calculation of principal and Gaussian curvatures is extremely simple.
HOG [23] converts the distribution directions of brightness for a local region into a histogram to express them in feature vectors, which is utilized to express the shape characteristics of an object. And it is influenced a little from an effect of illumination by converting the distribution of near pixels for a local region into a histogram, and has a strong feature for a geometric change of local regions. The following is a detailed explanation on how HOG description is calculated.
Value of gradient at every image pixel is calculated by derivatives fx and fy in x and y direction by convolving the filter mask [-1 0 1] and [-1 0 1]T. Refer equation (19) and (20).
where I is an example gray scale image and ⊗ is the convolution operation. The gradient magnitudes m(x, y) and orientation direction θ(x, y) for each pixel are calculated by
This stage defines production of an encoding that is sensitive to local image content. The image windows are divided into 8x8 rectangular small spatial regions call cells, as shown in figure 1 (c). Similar to [20], we used unsigned gradients in conjunction with nine bins for every cell (a bin corresponds to 20°). The 8×8 cell magnitude pixels are accumulated in one of the nine bins according to their orientation direction. Figure 1 (c) depicts a graphical representation on how the gradient angle range is binned in its respective cell
Directional histograms for brightness prepared in each of the cells were normalized as a block of 3×3 cells. This is performed by grouping cells in larger spatial regions called blocks. Characteristic quantities (9 dimensions) of row i, column j, Cell (i, j) are expressed as Fi,j=[F1, F1, … ,F9]. The characteristic quantities of k’th block (81 dimensions) may be expressed as:
Normalization processes are summarized in figure 1 (d), where a movement of block is based on the fact that it is moved to the right side and to the lower side by one each cell. And the feature vectors are saved by concatenation method. The overlapping process is done to ensure the important features of each cell. And the normalized characteristic vectors are given by
For example, the dimension numbers for the height and width of an input image are 128x64 pixels, the dimension number of the histogram is 9, the size of cell is 8, and the size of block is 3, then the calculated number of HOG feature vectors with 6804 dimension is obtained.
IV. Linear Discriminant Analysis
LDA[12] searches for the projection axes on which the face images of different are far from each other (similar to PCA), and at the same time where the images of the same class are close from each other. It is class specific method in the scene that it can represent data in form which is more useful for classification. Given a set of N images {x1,x2,…,xN}, assuming each image belongs to one of the c classes {X1,X2,…,Xc}, and LDA selects a linear transformation matrix W in such a way that the ratio of the between-class scatter and the within-class scatter is maximized. Mathematically, the between-class scatter matrix and the within-class scatter matrix are defined as
respectively, where μi denotes the mean image of class Xi and Ni denotes the number of images in the class Xi. If SW is nonsingular, LDA will find an orthonormal matrix Wopt maximizing the ratio of the determinant of the between-class scatter matrix to the determinant of the within-class scatter matrix. That is, the LDA projection matrix is represented by
The set of the solution {wi|i=1,2,…m} is that of the generalized eigenvectors of SB and SW corresponding to the m largest eigenvalues {λi|i=1,2,…m}, i.e.,
In order to overcome the singularity of SW, PCA reduces the vector dimension before applying LDA. Each LDA feature vector is represented by the vector projections
To make classification of new face image x′, we calculate the Euclidean distance between a given image x′ and training set x that is
V. Experimental Results
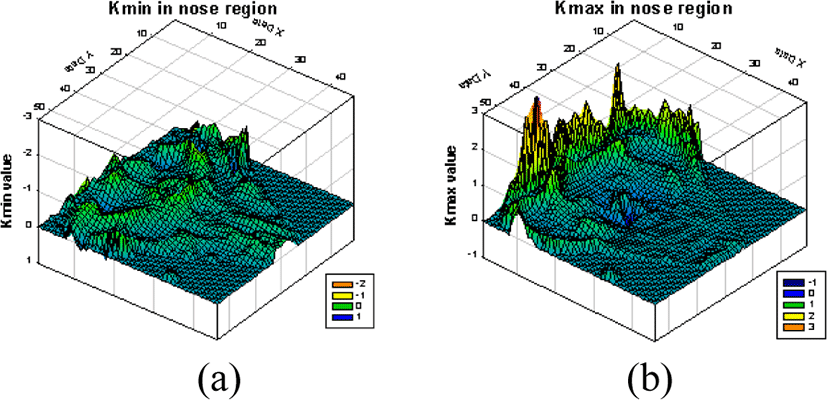
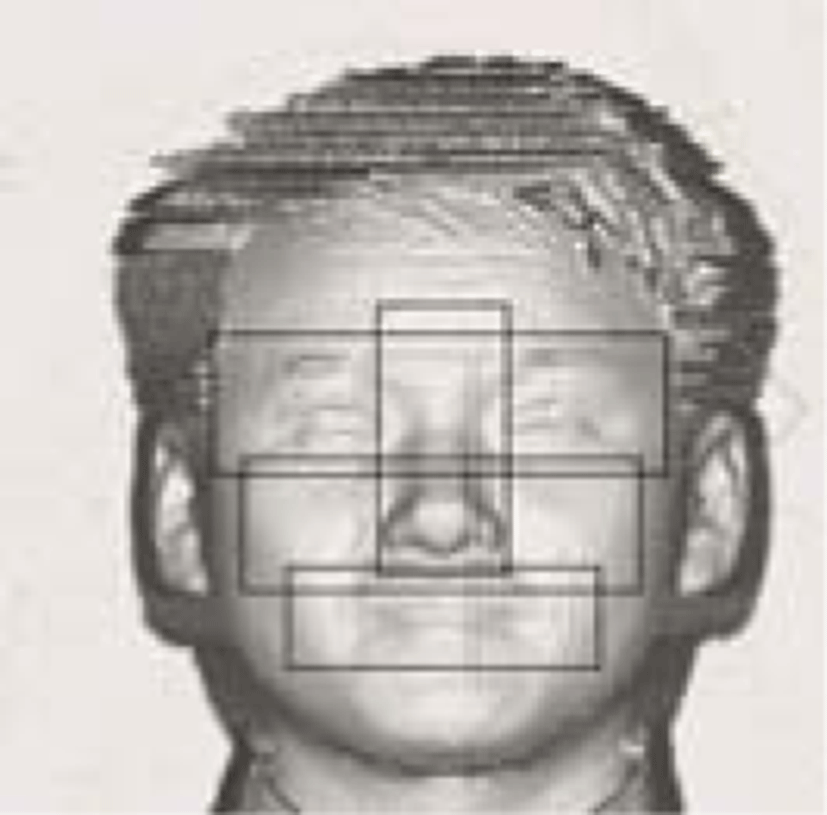
In this study, we used a 3D laser scanner made by a 4D culture to obtain a 3D face image [2]. A database composed of 592 images is used to compare the different strategies: used training and test set consist of 296 images, 7 poses (training: first front, right rotation, right panning, and up tilt, and test: second front left rotation, left panning, and down tilt) per person. With these 3D face images, the nose tip point is found by using contour line threshold values (for which the fiducial point is the nose tip). Images around the nose area are then extracted. To perform recognition experiments for the extracted face area, we firstly need to create two sets of images, as shown in Figure 4. After finding the nose tip, we processed the face pose normalization using the SVD. And then, the face surface curvature which is well presented for personal features was obtained. For the minimum and maximum curvature distributions are shown in Figure 5. To make face components, four face area were divided according to the areas, as shown in Figure 6: eye area (E), cheek area (C), nose area (N), and mouth area (M). From each component, LDA and Norm2 recognition results are showed in Table 1.

| Method | C | E | M | N | Avg. | |
|---|---|---|---|---|---|---|
| k1 | Norm2 | 92.2 | 90.5 | 83.9 | 83.9 | 88.5 |
| LDA | 90.8 | 89.9 | 90.2 | 88.7 | 89.9 | |
| k2 | Norm2 | 89.2 | 89.9 | 83.5 | 84.1 | 86.7 |
| LDA | 90.8 | 90.8 | 90.2 | 90.5 | 90.6 |
Generate the membership grade based on the LDA distance (di) information between the test image and the training set produced in the previous section. Using this distance, we follow the method introduced in [26].
where i=1,2,3,4, j=1,2,…, 296, i is the number of classifier and j is the index of the training set. And Nk is the number of samples in kth class Ck.
The data sets have been extracted with the aid of LDA. The cheek part among the face components represented the highest recognition rate, 92.2% for norm2 and LDA. It shows that cheek area has outstanding curvature features, because of including the nose tip area and both sides of cheek. And also it means that it has very different shapes or surface feature for each person. In average analysis, the recognition of adapted curvature and HOG method showed 90.6% - k2, increased more than norm2 methods. Additionally, in the curvature feature, k2 showed higher recognition rate than k1.
VI. CONCLUSION
We have introduced, in this paper, a new practical implementation of a person verification system using curvature-HOG based on the component face images. The underlying motivations of our approach originate from the observation that the surface curvature of the face has different shape based on the face components. And Ordinary HOG has two kinds of spatial region: small (cells) and large (blocks). And it is based on overlapping and dens encoding of image regions. To classify the faces, LDA and norm2 were used. It has been experimentally demonstrated that the aggregation of classifiers operating on four component face image sets generated by area based led to better classification results than norm2 method. Furthermore, we also confirmed that the curvature k2 has higher recognition rate than the k1.
From the experimental results, we proved that the process of the face recognition may use lower dimension, less parameters, and less calculation than earlier suggestion. We consider that there are many future experiments that could be done to extend this study.