




I. INTRODUCTION
We formulate the problem of parametric adaptation of models of complex systems (CS) with a discrete form of input of observation data through the “input-output” channel. Let CS be monitored on the “input-output” channel with a constant or variable measurement frequency. The values of the input vectors and the output when it is impossible to predict the errors in the presence of disturbances can differ significantly from the model values that were adapted at the previous moments i=1,2,3,…,N-1 measurements. Therefore, it becomes necessary to determine such values of the model parameters for which the values of the output parameters differ little from the model values .
The purpose of the work is the development of algorithms for the parametric identification of models of complex systems from discrete observations.
II. THE MAIN PART
We consider this problem for the case when the CS is formalized by a linear model with additive interference :
where A(K) is the matrix of the estimated parameters of dimension (m*n), is the CS input vector, is the output vector of the CS.We will assume that the CS is defined as a “black box” and its parameters are determined according to (1). The mathematical formulation of the problem of parametric adaptation of CS on discrete observations is defined as follows:
where A(N) ∊ Ω where A*(N+1) is adaptive parameter of the model at the moment N+1; is the value of the output parameters obtained from the adaptive model at the moment N+1; is the value of the observations of the output of the object; J is the criterion of model adaptation.A block diagram of the formalization of problems (2) and (3) is presented in Fig.1. Here, for ε in (4), the adaptation sensitivity threshold is adopted, according to which the adequacy of the model is determined by the object. Obviously, the adaptation procedure is connected, if the condition
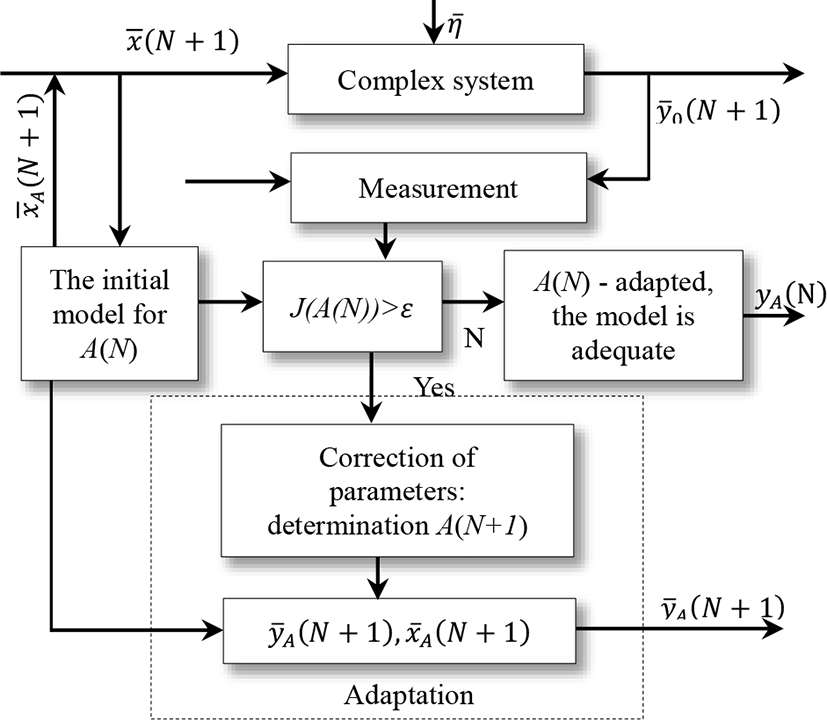
Otherwise, as an adapted model, the initial (adequate) model is adopted, the parameters of which were estimated at the previous measurement points. Algorithms and methods for solving the problem of parametric adaptation of models are divided into two groups according to their characteristics. The first group includes step-by-step algorithms, which are mostly recurrent [1,6]. Among this group, the basic Kaczmarz algorithm [2,5,6], which is developed for closed systems with perturbations, is most well studied and widely distributed.
A typical example of a stepping algorithm is a
where y0 (N+1) is the value of observations of the object at the moment N+1.Algorithms of the type (5) can be used both for linear models
and for nonlinear models of CSSpecifying (5), we consider the fundamental properties of the Kaczmarz algorithm, and define its modification with reference to the adaptation of linear models of the CS in the foreground (6) or (7). To do this, the CS model or its local stage will be searched in the following scalar form [2,3,7], assuming the presence of inputs and one output:
where yM (N+1) are the model values of the CS output; aj(N) - estimates of model parameters at the Nth step of adaptation. Assuming that at the Nth step the model adapted. We define the adaptation conditions in such a way that (9) is satisfied at the N+1 - M step. For this, choosing arbitrary initial values of the estimates ai(0) in (8), at each step we will refine them for (9) with respect to the following recurrence formula: where ξ is a parameter characterizing the level of random interference affecting the object.As can be seen, in the numerator of the second term of the relation (10) there is a difference between the observed and model values of the outputs, which in general is a random variable with unknown statistical characteristics [1,6]. Obviously, in the absence of interference, this difference ceases to be a random variable. In this case it is considered that the object is stationary and in (10) we can set ξ = 0.
Introducing the notation:
the adaptation algorithm (10) can be written in a more compact form:The vector form (11) is represented as follows:
where Δ(N+1) is a scalar quantity.Obviously, there are unknown values of the parameters ai (N) in the structure Δ(N+1), the limiting values of which are the adapted parameters at the N+1 step . Here is taken as the solution of the adaptation problem (2) or (3). The error vector is introduced as follows:
where .Obviously, the vectors and are orthogonal, since
where are the scalar products of the vectors .It follows that if even the total error (13) or (14) in the absence of an external perturbation ξ decreases, the errors of the individual parameters {Hi (N+1)} can take arbitrary values. Therefore, the model values of the adapted parameters at the N+1-st step according to the algorithm (11) can significantly differ from the true values. This fact for the two-dimensional case is illustrated in Fig. 2.
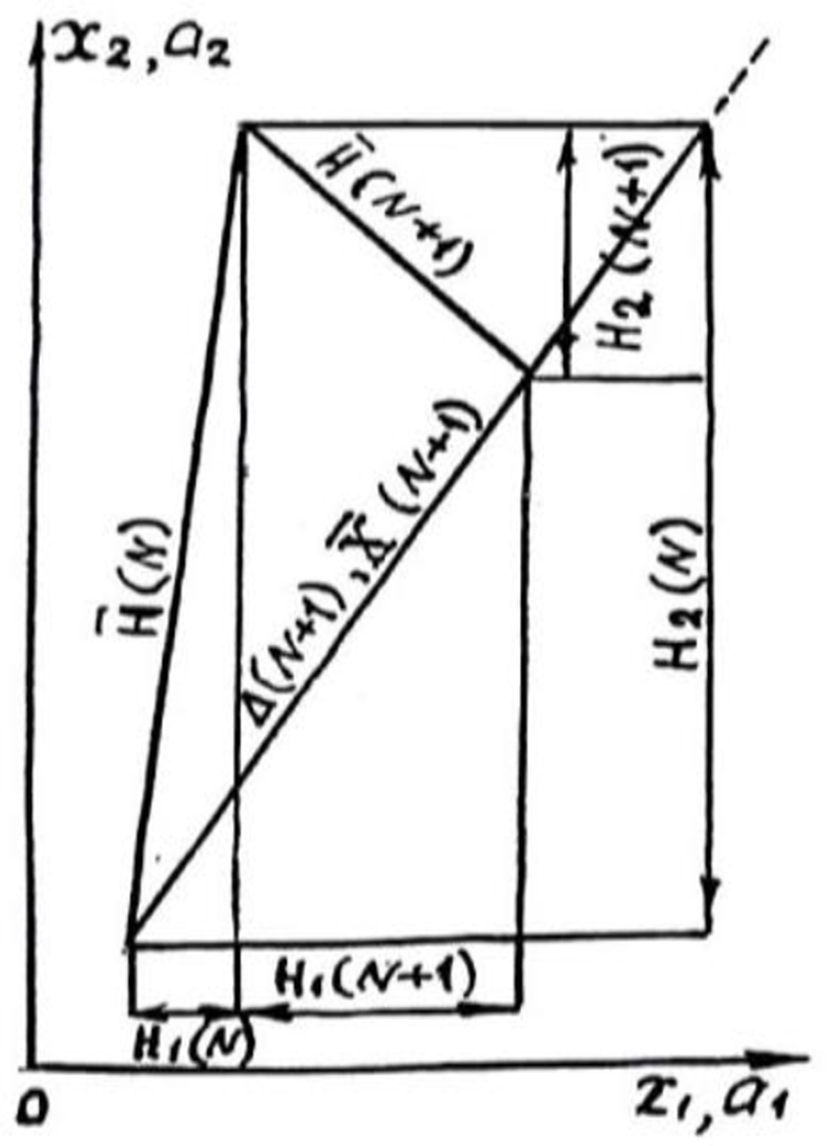
To analyze the convergence of the adaptation algorithm (10), we use the square of the error vector H(N+1)
It's obvious that
By virtue of (16), it can be assumed that the maximum convergence of the algorithm is ensured when the vectors and x(N+1) are orthogonal. Here the convergence rate is the smaller, the less differ the directions of the and vectors in the neighboring measurement cycle. The rate of convergence has a second order, i.e. [4,7]. This regularity for a two-dimensional object is shown in Fig.3. If α is the angle between adjacent directions, then the adaptation error after N+1 cycles is easily determined depending on the initial state:
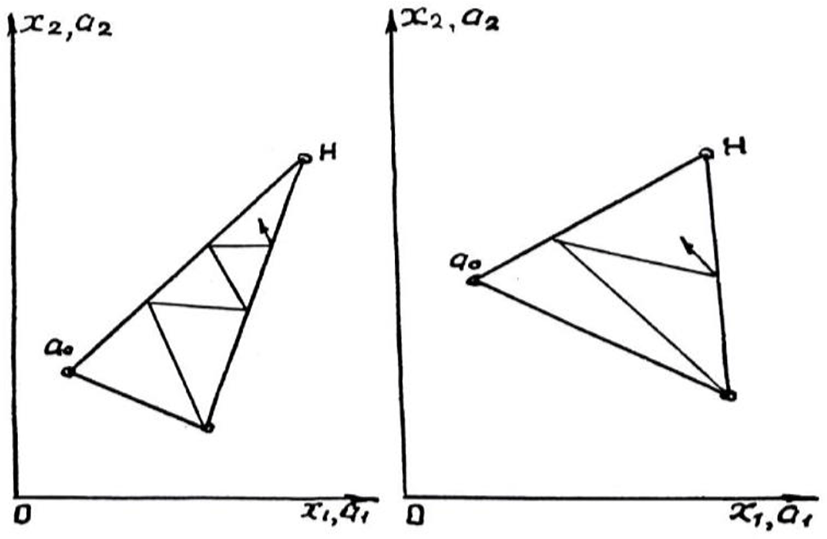
With zero mathematical expectations and the same variances for the components of the error vectors (13), one can calculate the mathematical expectation of the error after N+1 cycles of adaptation [1]
where n is the dimension of the vector of input parameters x.III. CONCLUSION
Specifying (5), the principal properties of the Kaczmazh algorithm are considered, and its modification is proposed with reference to the adaptation of the linear and nonlinear models of the CS
For this, the CS model or its local stage is sought in the next scalar form, assuming that there are multiple inputs and one output.
By virtue of (16), it can be assumed that the maximum convergence of the algorithm is ensured when the vectors and x(N+1) are orthogonal. Here the convergence rate decreases, the less the directions of the vectors and differ in the neighboring measurement cycles. The rate of convergence has a second order, i.e. .