




I. INTRODUCTION
Due to the limitation of the camera’s dynamic range, we cannot acquire dark and bright area information at the same time. This problem can be solved by shooting several times with different exposure values. There has been widely discussed that methods of combining various images with different exposures into a single HDR image [1-6].
One of these is the Laplacian pyramid decomposition and is useful in many applications. However, image fusion based on the image pyramid method has a smaller image size as the number of pyramid layer increases. Decreasing the total number of pixels in the image reduces the way you can control the brightness of the pixels. When you reach the topmost layer of the pyramid, you cannot control the brightness component. In other words, the overall brightness of the image can be highly dependent on the brightness of the pixels around each area.
As a result, unwanted areas become lighter or darker. In this paper, we propose a method of extracting reflection components from images and applying them to image fusion based on Retinex theory [7] which has the same effect as existing MSF algorithm and does not reduce image size.
II. FORMULATION OF THE PROBLEM
A fusion of Laplacian pyramid decomposition produces a weight map through some intuitive measure the exposure of different images. The generated weight map and images with different exposure are appropriately mixed to create a single image. The formula of the image fusion using the generated weight map is as follows:
In equation (1), parameter M represents the number of multi-exposure images with different exposure and N represents the number of layers of the image pyramid
The MSF method determines the number of layers in the image pyramid based on the image size, so it takes a lot of time. In [6], the computation is simplified by approximating the MSF equation. The simplified formula is as follows:
In equation (2), the detail of the Laplacian image is reflected in the weight map by the edge emphasis α value.
Retinex theory of human visual effects is compound of retina and cortex. When the human eye detects an object, it is affected by the surrounding light as well as the reflection of the object. At this time, the human eye has an action to remove the illumination component. This is Retinex theory. This can be expressed as follows.
Parameter I mean the finally obtained image, and R and L mean the illumination component and the reflection component, respectively.
The MSR is an algorithm that complements the disadvantages of the SSR algorithm. The MSR estimates the illumination with multiple illumination estimation functions. SSR cannot improve enough contrast depending on the characteristics of the image [9]. The MSR algorithm solves the SSR problem by adding weights to the various lighting estimation functions.
In the above equation (4), n denotes the number of illumination estimation functions of different sizes.
III. PROPOSED METHOD
The traditional MSF algorithm uses a weight map to generate a Gaussian pyramid for image fusion. As the pyramid layer increases, the image size decreases. The higher the layer, the greater the effect of the surrounding area on the pixel intensity. That is, certain unwanted areas can be darkened by the surrounding area, and vice versa. Therefore, in this paper, we propose a method to maintain the image size with similar effect to the existing MSF method. Figure 1 shows the processing flow of the proposed method. We use the input image to obtain the weight map and the reflection component. Creates a new weight map by summing the weight and reflective elements. This applies to multiple exposure images to fuse HDR images.
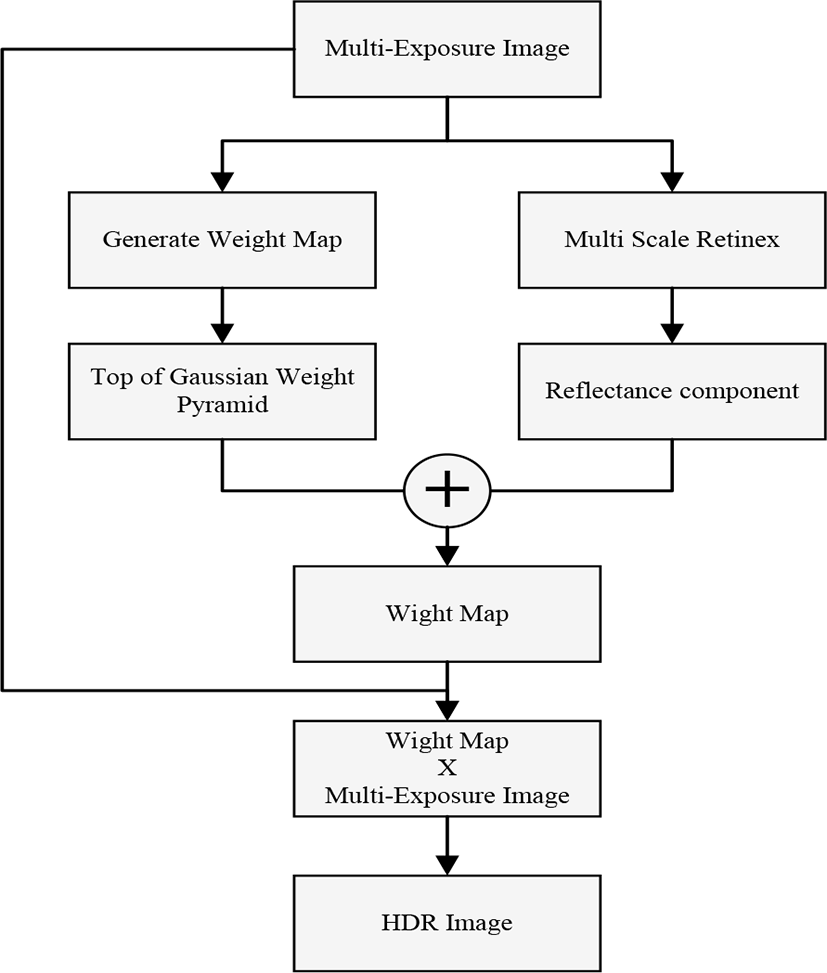
The way of obtaining the reflection component and the illumination component in the image can be obtained by using the formula (5) which is the basis of the Retinex theory.
Weber-Fechner, and there is a log relationship between what is actually applies law [8] exists in the human visual perception system and the sensation sensed by humans. Based on this, equation (5) can be transformed into the (6).
As shown in equation (6), it estimates the illumination component of the surrounding area to obtain the reflection. In this paper, we use a Gaussian filter to estimate the illumination. We used a total of three Gaussian filters to evaluate multiple lights. Weber-Fechner's law was used to combine three reflective components into one image. This rule means that changes in low-light areas are more sensitive than changes in high-brightness areas. In other words, the image quality is better as a result of emphasizing contrast in low light areas. The expression for extracting low-light areas from an image is:
The low-light areas of the image obtained in equation (6) are combined into one image as shown below.
Various methods of generating a weight map are discussed [5], [6], [10]. In this paper, we have used three contrast, saturation and well-exposed indicators proposed by Merten et al. [5] was used to extract the preferred pixels from multiple exposure images. Based on this, it creates the top Layer of Gaussian pyramid.
This paper simplifies the Gaussian pyramid generation process. For Gaussian filtering, the sigma value is proportional to the number of pyramid layer. This filter has the same effect as the top layer of Gaussian pyramid. The formula for deriving the sigma value by calculating the number of pyramid layers is as follows:
Using large sigma values in Gaussian filtering requires a lot of computation time. Thus, the calculation is performed in the frequency domain when performing filtering.
IV. EXPERIMENTAL RESULTS
The results of the proposed method and the MSF method are compared with each other through an evaluation index. The images used in the experiment were two images with different impressions. Experimental results show that the proposed method has similar performance to MSF algorithm and it is confirmed by using SSIM and AMBE evaluation index. Comparing with the SSF algorithm [6], which approximates the MSF algorithm, we compare and analyze how similar the proposed algorithm is to the MSF results.
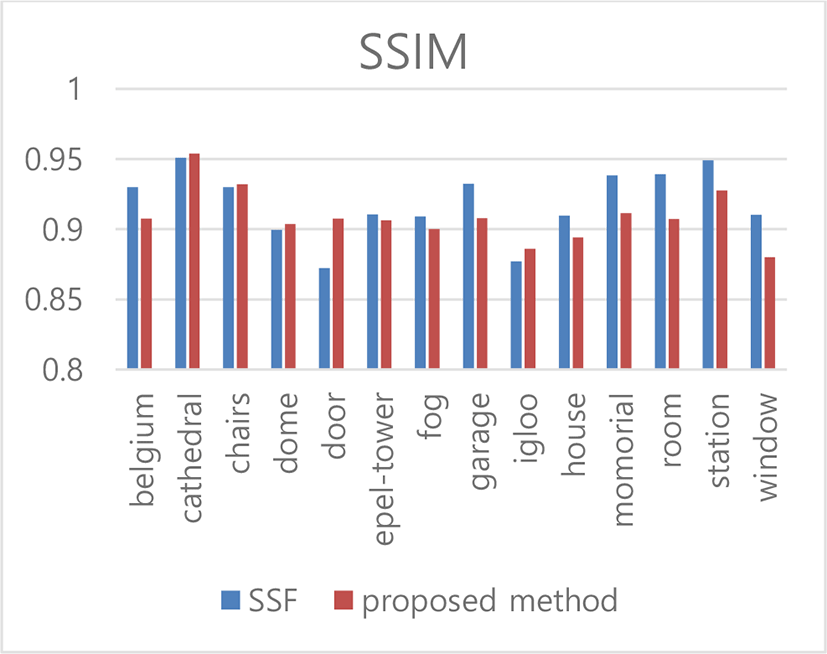
Structural Similarity Index (SSIM) represents the visual and structural similarity between the original image and the resulting image, and is composed of complex indicators based on contrast, structure and luminosity. SSIM has a value of 1 when it is the same as the original, and has a value close to 0 if it is not similar.
Figure 2 compares the results of the proposed method with the results of the existing method through SSIM. The SSIM average difference between the two algorithms was about 1%. This means that it is structurally very similar to the resulting image of the MSF algorithm.
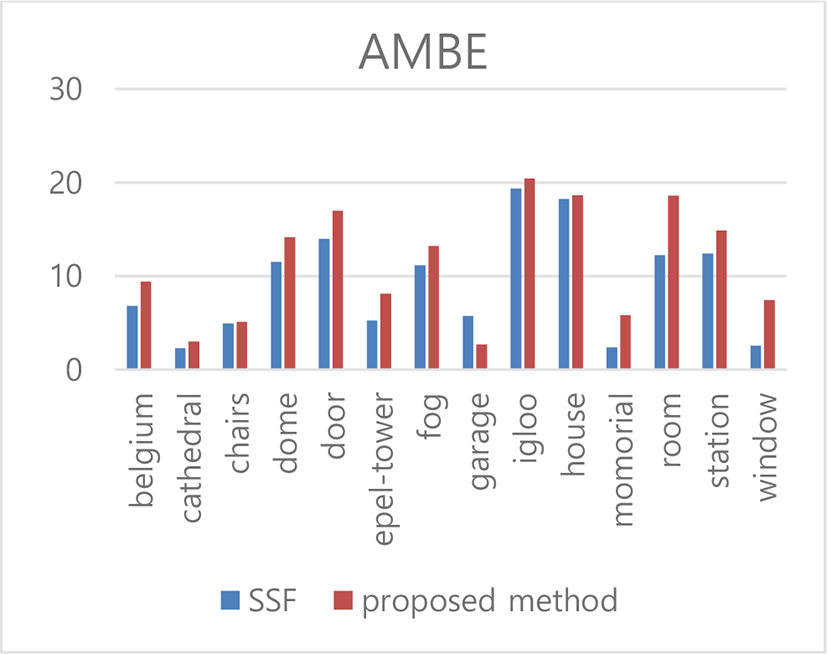
The AMBE (Absolute Mean Brightness Error) indicator measures the difference between the average brightness value of the resulting image and the average brightness value of the original image. This allows you to see how well the image contrast of the MSF algorithm is maintained.
If the brightness average of the image is small, the AMBE value is 0, and the larger the brightness difference, the larger the value.
Figure 3 compares the results of the proposed method with those of the existing method through AMBE. The AMBE mean difference between the two algorithms is about 0.8%. This means that the average brightness of the MSF algorithm is similar.
V. CONCLUSION
In this paper, we propose a method to solve the brightness component control problem of the existing MSF algorithm by adding the reflection component of the image to the weight map generation. In the conventional MSF method, the brightness component of the image depends on the surrounding pixels because of the size of the reduced image in the process of generating the pyramid of the weight map. This means that depending on the characteristics of the image, the contrast ratio can be improved, but certain areas can become too dark or too dark. However, the proposed method has an effect similar to the existing MSF method by estimating the reflection component and fusing the image with a plurality of illumination functions, and has an opportunity to solve the MSF problem by maintaining the number of pixels of the image. The presently proposed method may result in bad images in some images because the size of the light evaluation function is a fixed value. This can be solved by setting the size of the illumination estimation function adaptively according to the characteristics of the image in future studies.