





I. INTRODUCTION
The first step in recognizing a face is to determine if a face exists in the image captured by the camera. If there is a face in the image, the position and size of the face are searched to determine whether or not the face is recognizable. If it is recognizable, it searches for 'eye' as the first step of recognition. Common face detection methods can be classified into a knowledge-based method, a feature-based method, a template-matching method, and an appearance-based method [1].
The knowledge-based method assumes that a person's face consists of two eyes, one nose and mouth, and each face element has a certain distance and position. And it is a method to detect faces considering the relation between these elements. Feature-based methods infer face size and position using face-specific features such as facial features, color, shape, and size [2], [3].
It detects faces through inferred data, and also detects faces through distance between facial elements, position on face, and so on. The template matching method is to create a basic template for the face, and then analyze the inputted face image to create a standard template for the face. Then, the standard template and the input face are compared and detected. The appearance-based method is to detect a face using a model learned by a set of learning images. This method uses statistical numerical values to detect face parts in complex images.
The final goal of this study is to improve the recognition rate of faces at various angles. That is, the face which is even in various angle changing environments can be recognized.
As a method of realizing this technology, it is to implement an algorithm that inputs two-dimensional flat photograph, extracting a feature point, and then recognizes faces rotated in three-dimension using extracted feature point. In order to realize this technology, vector compression and expansion methods are used. That is, it recognizes the face rotated in the up, down, left, and right direction only by the feature points of the flat photograph. That is, the feature point vector of the face is classified into six vector zones, and the rotation angle is obtained by increasing or decreasing the vector zones according to the angle of rotation of the face. In this way, the recognition can be attempted by coinciding with the feature points of the face rotating in three dimensions. By doing this, it recognizes faces rotated in top, bottom, left, and right with only the feature points of a flat photograph.
II. THE SHAPE OF THE HEAD ANALYSIS
Westerners' head shape is more three-dimensional compared to the shape Oriental’s head. Of course, among Oriental people, there are long-head figures like Westerners. The long size between the forehead and the back of the head is called a long-head. On the other hand, the back of the head is flat, and the short between the forehead and the back of the head is called the short-head. The middle is called the middle-head shape. Figure 1 shows the top and side views of the long-head and short-head.
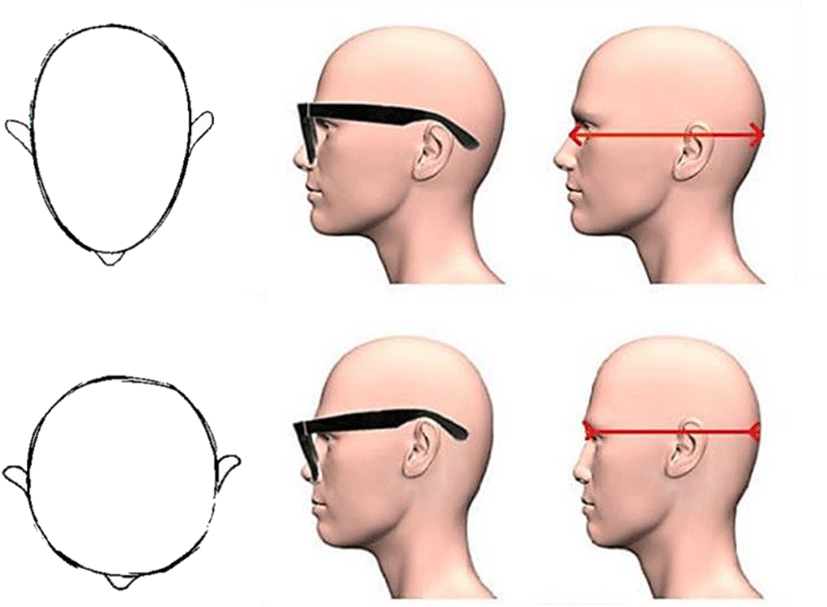
The short-head is usually eyes are higher than the ears, and the distance between the eyes and ears is so close that glasses or sunglasses are not suitable. This is the reason why glasses flow down well. The long head type has lower ears than ears, and the distance between the eyes and ears is long, so the sunglasses are well suited. If an Oriental has a nose plastic surgery, it can be recognized immediately, it because of the difference in the shape of head. In this way, when the nose is raised from the face with short forehead and back, the face harmony is broken [5][6].
A face which is narrow width and long between the forehead and the back is expressed three-dimensional at any angle. Statistically, the face shape that is classified as long -head in Korea is less than 5%, and the long-head is three-dimensional face that everyone feels difference. However, long-head shape is not always nice and it is not always bad for short-head shape [7].
In the face recognition system, the feature points are extracted slightly differently at the long-head and short-head shape. Therefore, there is a significant difference in the variable values of the face zones even in the multi-angle rotated faces of the upper, lower, left, and right sides.
The Westerner’s face has a big three-dimensional than Oriental. Thus, the nose is relatively high, and the eyes are relatively deep. As a result, eyes are dented and bigger than Oriental.
This shape of face is very suitable for extracting feature points, but the useless ratio of feature points is relatively high when the generating a side face’s feature point. The reason is that distinct feature points disappear from the side face. Therefore, it has been proven by data that it is very difficult to generate feature point from the side faces of Westerners.
As can be seen in Figure 2, the side faces of Western and Oriental people are distinctly different. The shape of the Westerner’s mouth is a clockwise depression from the nose to the mouth and then coming out of the jaw again. However, the shape of the Oriental’s mouth appears to protrude from the nose to the jaw in the counterclockwise direction [8].
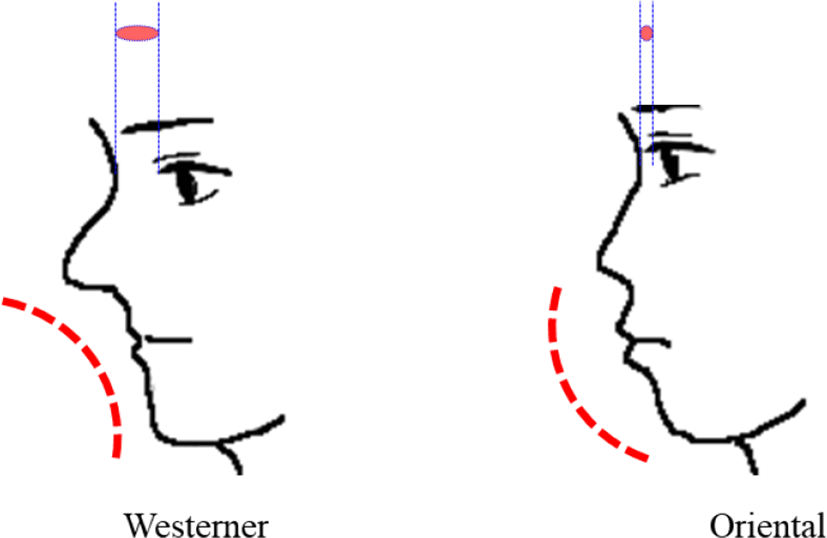
It is not a problem to recognize these faces with mouth shapes by feature points extracted from front face only. However, it can be seen that an algorithm must be differently applied to Orientals and Westerners in order to recognize side faces or slope faces. In other words, it can be seen that the feature point compression and expansion algorithm is more suitable than the feature point generation algorithm for Oriental's faces, and the feature point generation algorithm has a higher recognition rate on the faces of the Westerners.
III. FEATURE POINTS COMPRESSION & EXPANSION
The feature point compression and expansion algorithm is inventive and new algorithm developed while carrying out this study. This algorithm can provide the fastest solution for rotated face recognition. The basic feature of this algorithm is to divide the feature points extracted from the face into 6 zones as shown in Fig. 3.
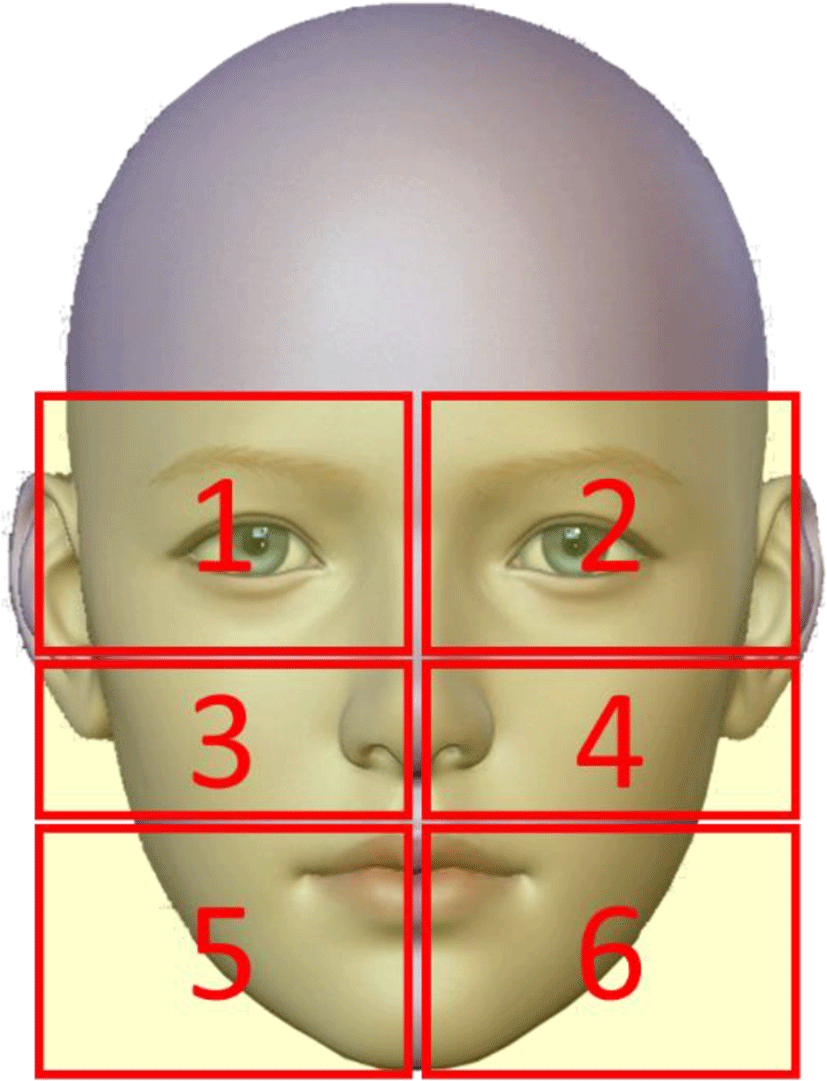
In left-right rotation, compression or expansion is divided into left and right. Thus, six zones are again grouped into two zones, one is grouped into three zones on the left, and the other zone is grouped into three zones on the right.
Therefore, in the left and right rotation, the zone number 1, 3, 5 are bound one group, and the zone number 2, 4, 6 become another group and are compressed or expanded. When rotating up and down, it should be grouped into three zones. At this time, the zone number 1, 2 are bound one group, the zone number 3, 4 are bound second group, and the zone number 5,6 are bound another group.
Each zone is interlocked or separately compressed and expanded. In each zone, extracted feature points are located, and the points are stored as vector values. Compression and expansion are not manipulations on simple position values. This is done by calculating a vector value.
Fig. 4 is an Illustration for the left-right rotation. As shown in the figure, when rotating left, the left zone is compressed and the right zone is expanded. Conversely, when rotated to the right, the right zone is compressed and the left zone is expanded.
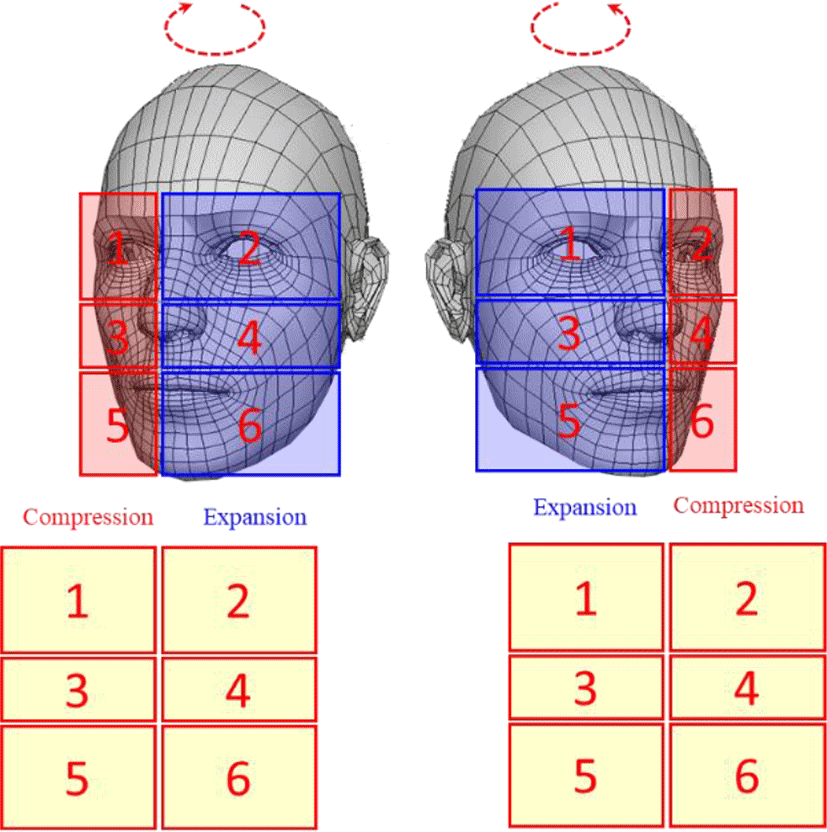
Fig. 5 is an Illustration for the case of up and down rotation. As shown in the figure, when the head is tilted down, the lower zone is compressed and the upper zone is expanded. The intermediate zone is compressed and expanded selectively.
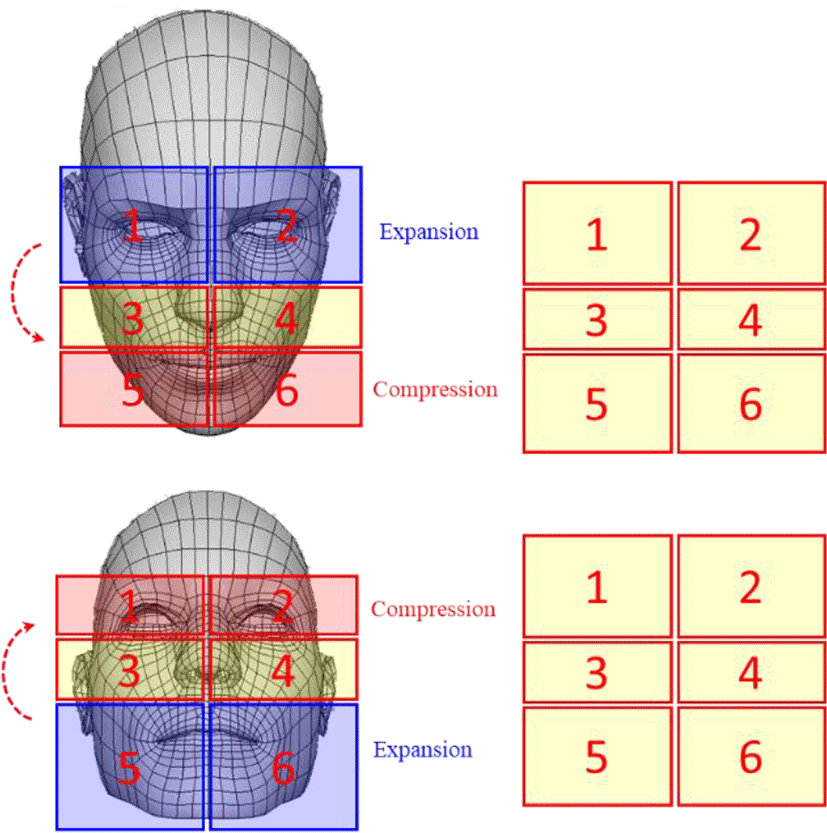
Conversely, when the head is lifted up, the upper zone is compressed and the lower zone is expanded. The intermediate zone is compressed and extended selectively.
Since the compression and expansion of vectors are the basic framework of the algorithm, the basic algorithm, the linear operator, has been developed as follows.
When k is a non-negative scalar,
The liner operator
is said to be a scaling operator with factor k.
The reason, T (x, y) = (kx, ky) is a linear operator because it is a linear equation with kx, ky.
Here, if 0≤k<1,
the operator T is called contraction.
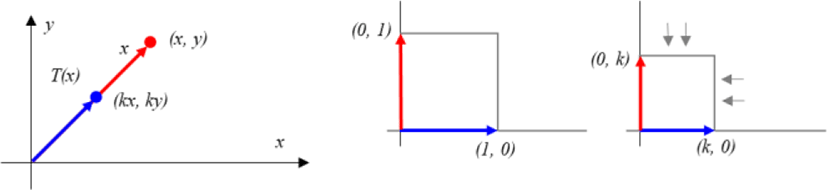
If k>1,
the operator T is called dilation.
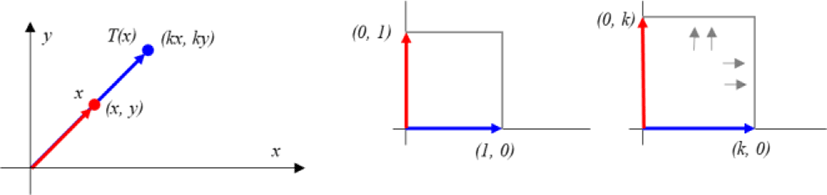
A common geometric feature of contraction and expansion is preserving the direction of the vector. The difference is to reduce the size of the vector in the case of contraction, but to increase the size of the vector in the case of dilation.
For a linear operator T (x, y) = (kx, y),
when k is scalar, not a negative,
If 0≤k <1,
the geometry on R2 is compressed in the x-axis direction.
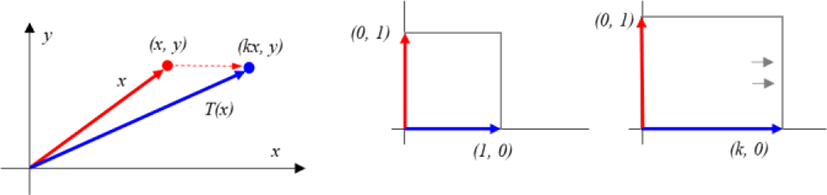
If k> 1,
the geometry on R2 extends in the x-axis direction.
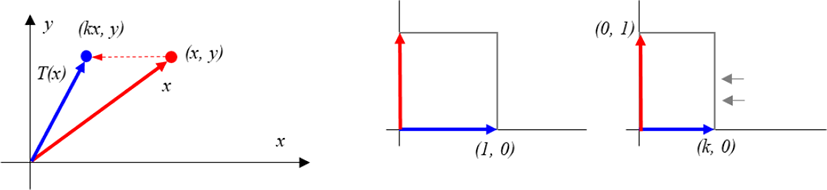
Therefore, for the linear operator
If 0≤k<1, the operator T is referred to as compression in the x-direction by k,
If k> 1,
the operator T is expanded by k in the x direction (expansion in the x-direction with factor k).
Similarly, when k is scalar, not a negative,
For the linear operator
If 0≤k<1,
the geometry on R2 has the geometric characteristic of being compressed in the y-axis direction,
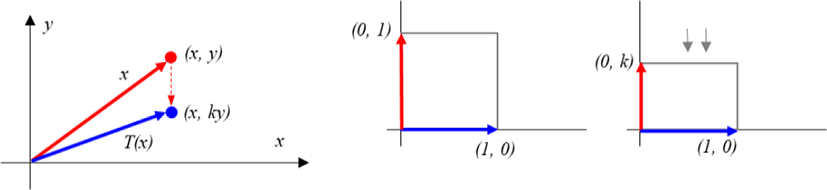
If k> 1,
the geometry of the figure on R2 extends in the y-axis direction.
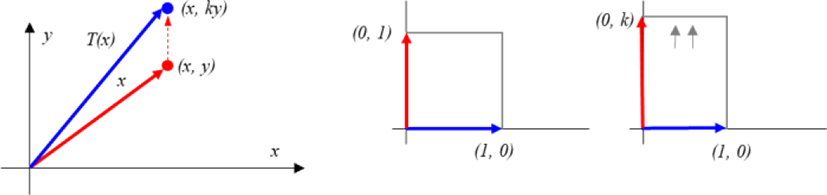
Therefore, for the linear operator
If 0≤k<1,
the operator T is referred to as compression in the y direction by k,
If k> 1,
the operator T is said to expand in the y direction by k.
IV. EXPERIMENT
One hundred Korean faces were photographed for the experiment of vector compression and expansion algorithm, which is for multi-angle face recognition.
The feature points were extracted based on the captured front face in the photograph, and based on them, the compression and expansion rates, number of useless feature points, and useless feature points rate for the up & down rotation angles of 15° and the left & right rotation angles of 15° and 30° respectively were obtained.
As a result, representative face models were selected, which was the closest to the average of the ratio of each feature point and the useless feature point.
Therefore, the feature points of the representative face model are extracted, and the compression and expansion rates of each angle of up, down, left, and right, the number of feature points that are useless, and the useless ratio are analyzed. The reason for analyzing useless feature points is that they are closely related to the threshold of recognition rate.
Fig. 6 shows the representative face model and extracted feature points. Although the face selected as the representative model is slightly different from the traditional Korean face type, and according to the distribution of the feature points, it shows the future Korean female characteristics face type.
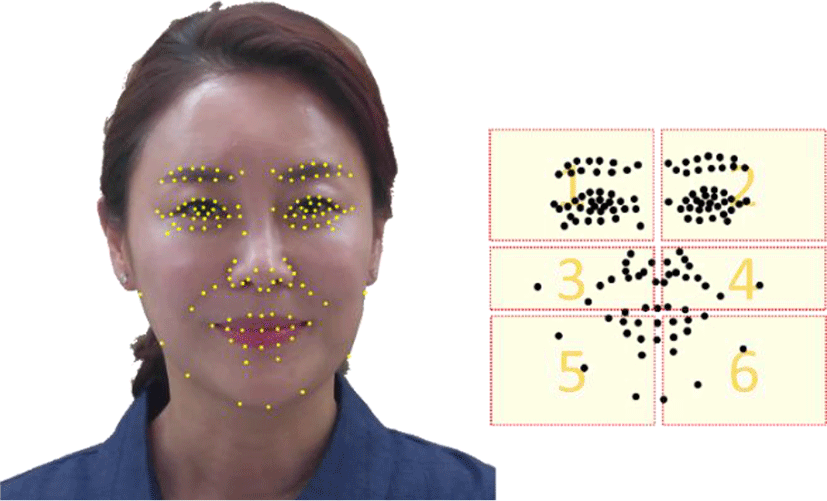
In addition, the analysis of facial recognition feature point data has distinctive features from Western female and can be positioned as a unique Korean beauty figure.
The total number of feature points of the representative model face is 128, and the number of feature points for each zone and the size of each zone by feature points are shown in Table 1.
| Zone | Horizontal width | Vertical width | Feature points |
|---|---|---|---|
| 1 | 4.6 | 3.48 | 40 |
| 2 | 4.19 | 3.48 | 39 |
| 3 | 6.26 | 2.60 | 12 |
| 4 | 5.09 | 2.41 | 12 |
| 5 | 5.26 | 4.68 | 14 |
| 6 | 4.26 | 4.89 | 11 |
| Total | 128 |
A total of 128 feature points are somewhat larger than the average feature points of Koreans. The reason seems to be that the outline of the face is futuristic, and it possesses a clear aspect ratio. The reason why the number of feature points is evenly distributed in the right and left sections is the data proving that the face is symmetrical. The reason why the feature points are distributed widely in the zone 1, 2 is analyzed because it is a distinctive shape.
Fig. 7 shows the representative model’s multi-angle. Fig. 8 shows extracted feature point that is replaced with the face angle of the representative model in Fig. 7. Therefore, in Fig. 8, the two left feature points show rotation angles of 30 ° and 15 °, the right feature points show the rotation angles of 15 ° and 30 °, and the up & down rotation angles are 15 °. Fig. 8 shows the state of compression and expansion in the direction of rotation from the original extracted feature point which located in the center.


Yellow is the feature point within the threshold, and red is a useless feature point. If the total number of feature point does not exceed 35% of useless feature points, there is no problem recognizing the face.
Table 2 and Fig. 9 shows the number of useless feature points for each zone. Table 3 and Fig. 10 shows the distribution of compression and expansion rates by zone.
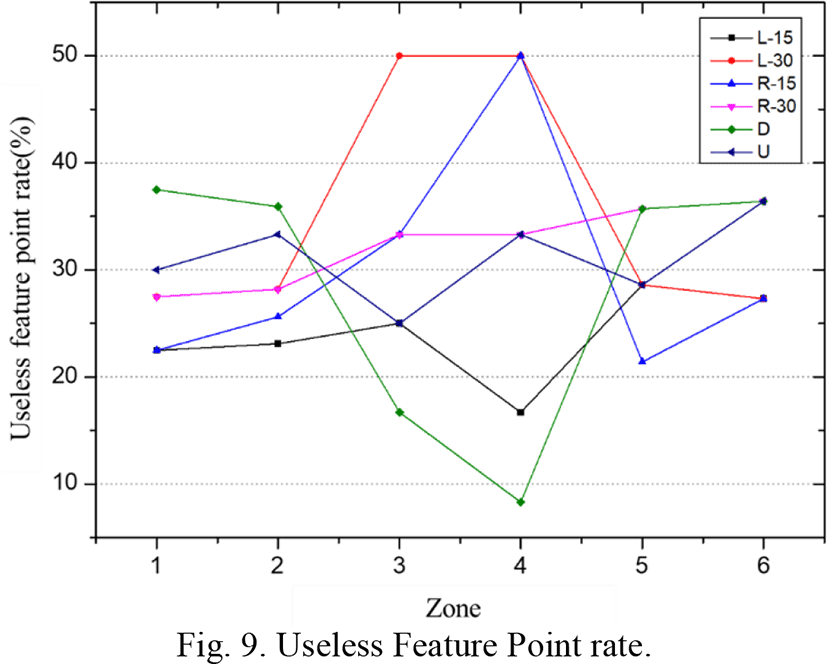
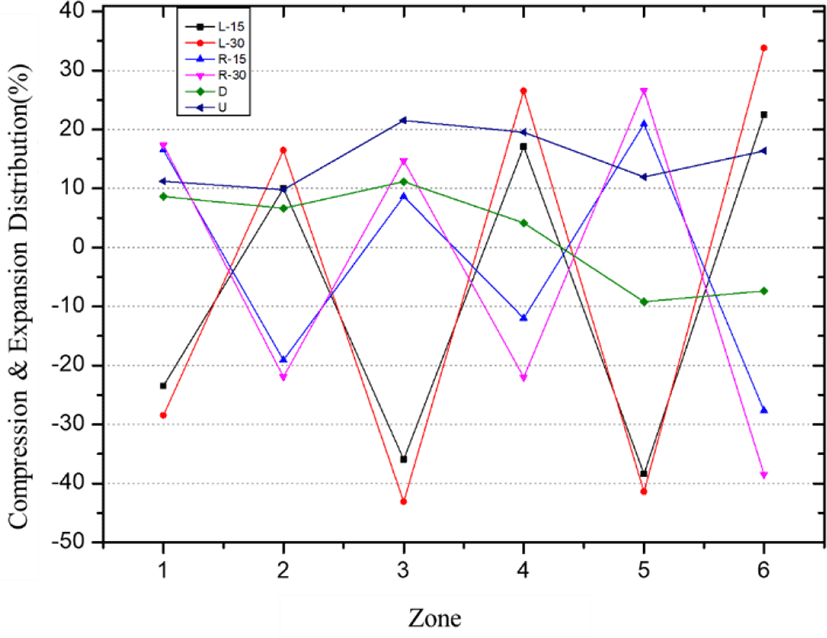
In this study, it was tried to find the compression and expansion mean values according to the face rotation angle. Therefore, the average value of 100 persons face was investigated in order to obtain the average compression and expansion rate in up, down, left and right rotation.
It was found that the compression and expansion rates vary widely depending on the width and length of the face. The average value showed a large deviation according to the size of the face, and it was not a meaningful value.
However, the result obtained incidentally was that the expansion rate on the opposite side of the zone to be compressed was 10 to 15% smaller on average than the compression rate.
That is, if the compression rate of the zone 1 is 30%, the expansion rate of the zone 2 is 25 ~ 27% on average. That is, the compression ratio and the expansion rate are not proportional.
Based on these results, further study is needed to recognize the multi-angle rotation faces by this vector compression and expansion algorithms. It is needed to find the average parameter for the compression and expansion rate according to face width and length.
V. CONCLUSION
Recognizing faces rotated by multiple angles using only feature points extracted from a flat photo is one of the most difficult assignments. Various algorithms have been devised and attempted to solve this assignment.
Especially, in this study, it was tried to estimate and convert the three-dimensional shape by adjusting the interval of the feature points by the rotation angle of the face.
Since the feature points can’t be adjusted one by one, they are grouped and the feature point intervals are adjusted via group adjustment.
The compression and expansion rates determined by the face rotation angle. However, this value was found to vary widely depending on the width and length of the face. Therefore, it is considered that the average value obtained from 100 face data is not enough to be used as the average parameter of this algorithm.
In order to realize effective three-dimensional face recognition using this algorithm, more face feature point data should be analyzed and established.
Through this study, it was obtained a basic algorithm that can recognize three-dimensional faces through vector compression and expansion. Further studies should continue to attempt to obtain an average parameter. If the average parameter is obtained, the face is considered to be recognized at a rotation angle larger than the current maximum recognizable face rotation angle.






