





I. INTRODUCTION
According to the National Statistical Office’s estimate of future population, Korea has already become an aging society, with the ratio of people aged 65 or older exceeding 7.2% in 2000 and 14% in 2017. In addition, the elderly population is expected to enter the super-aged society by 2026, accounting for 20 percent of the population. The increase in the number of elderly people living alone due to the aging population become one of the biggest social problems. The elder living alone may face serious threat of survival because it is difficult to get help from other people. One of the threats for the elder living alone is the fall situation. A fall situation threatens for elderly to survival because it is difficult to quickly communicate this situation. Several methods are presented for detecting the fall situation. The fall detection is classified into methods based on equipment device and based on video [1-5].
In this paper, we propose the fall situation method by the deep learning. The object detection method through deep learning using a neural network significantly improves accuracy compared to the existing method [6-10]. Mask R-CNN [11], which is a state-of-the-art method for object detection, are applied to human body detection [12-15].
R-CNN is a type of deep learning neural networks. Also, Fast R-CNN keeps the bounding box information found in the selective search through the CNN and extracts and pools the corresponding region from the final CNN feature map to dramatically shorten the time of the CNN. Faster R-CNN can process even faster speed because it is processed in CNN when creating bounding box. Mask R-CNN adds a network that masks whether each pixel corresponds to an object in Faster R-CNN. In this paper, we use Mask R-CNN, which is the most advanced form for the performance and speed.
The methods of classifying objects by processing the bounding box have a disadvantage of reducing accuracy for a moving model [16]. However, Mask R-CNN increases accuracy because it verifies that each pixel is an object in addition to the processing of the bounding box.
First, the points of both shoulders and knees of the body are detected by Mask R-CNN. After that, a centerline of the body is extracted from the points of shoulders and knees. The angle of the centerline is calculated and tracked. If the change of the angle exceeds a certain threshold, the current frame is considered suspected of falling. If the suspected fall condition in consecutive frames, the fall situation is detected.
II. CONVENTIONAL FALL DETECTION METHOD
Existing fall detection methods can be classified into equipment mounted detection methods and color image-based detection methods [1]. Fall detection methods based on an equipment-mounted device [2-3] are accurate when the user is equipped this device. However, the user should wear the kit continuously. Video based detection methods [4-5] are to analyze the color image to determine whether the situation is falling, which can detect the fall situation without any inconvenience of having to install special equipment. However, this method has the disadvantage of not being able to detect falls because the screen cannot be determined for situations with little lighting. To solve this problem, the method presented in this paper is a detection method of fall situation in color image through deep learning neural network.
III. METHOD OF FALL SITUATION DETECTION BY NEURAL NETWORK
In this paper, the method of detecting fall situation through deep learning neural network is implemented. The flow chart of the method proposed in this paper is shown in Fig.1.
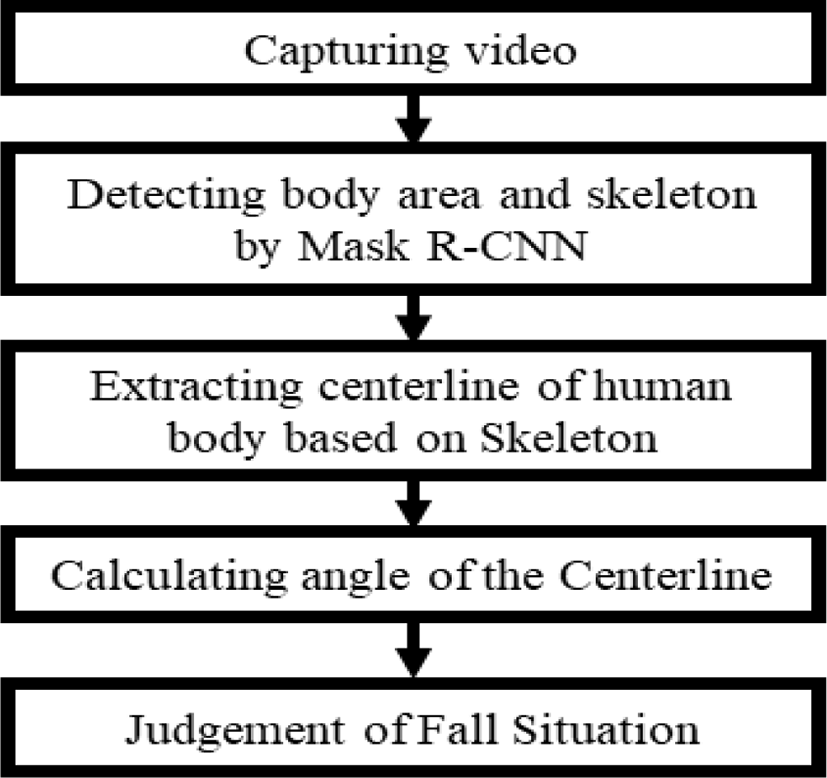
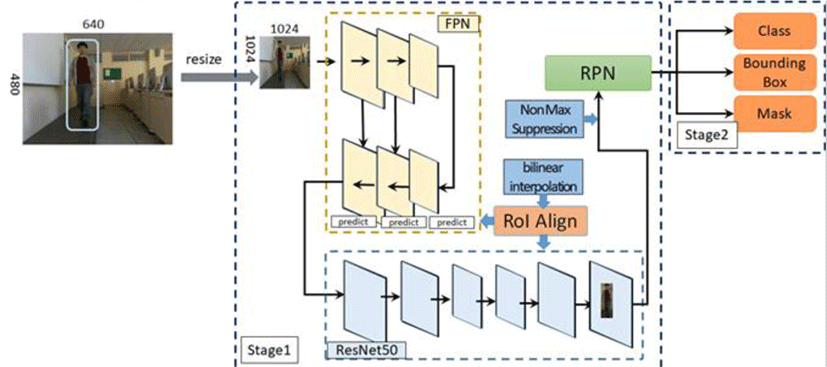
We Apply Mask R-CNN to the neural network for falls. Mask R-CNN is a neural network designed to cover areas of objects that are actually found. Mask R-CNN consists of ResNet for extracting feature maps, Feature Pyramid Network (FPN) for extracting classes and boxes from feature maps for efficient channel numbers, and Region Proposal Network (RPN) for which Mask predictions are added in RoI. Figure 2 shows the structure of Mask R-CNN for body detection and bouncing box skeleton extraction in this paper. In the FPN, the scale of the input image is reduced through the bottom-up layer, expanded through the top-down layer, and various sizes of objects can be detected through the bottom-up layer and top-down layer within the FPN. ResNet has applied a skip connection that adds the input value of the layer to the output value, and the learning efficiency increases as the size of the output value that must be learned for each layer decreases through the skip connection. The RPN detects the RoI of the object and the pixels to which the object belongs in the feature map. The RoI align is applied to the RPN of Mask R-CNN to improve the predicted accuracy of the bounding box and mask. The RoI Pool, applied to Fast R-CNN and Faster R-CNN, round up the decimal coordinates of the predicted bound box, while the RoI Align corrects the decimal coordinates through double linear interpolation, thus improving the accuracy of the RoIs prediction.
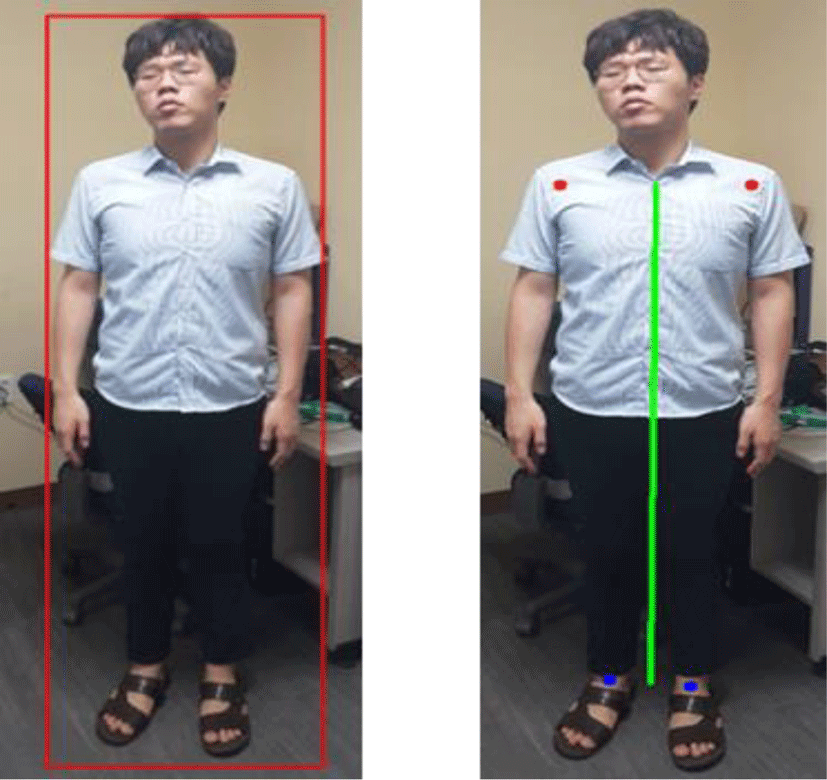
We perform the learning of the body area and the main body part in Mask R-CNN. The main body parts learned are shoulder and knee points.
First, we install the camera at a point where you can take a picture of a person’s body. At this point, the camera is installed parallel to the ground. In the captured image, the body area and the body’s shoulder points psl≡(xsl, ysl), psr and knee points pnl and pnr are detected through Mask R-CNN. Then we locate the centerline of the body following the psc≡((xsl+xsr)/2(ysl+ysr)/2), and the pnc. An angle of the centerline is then calculated as the following:
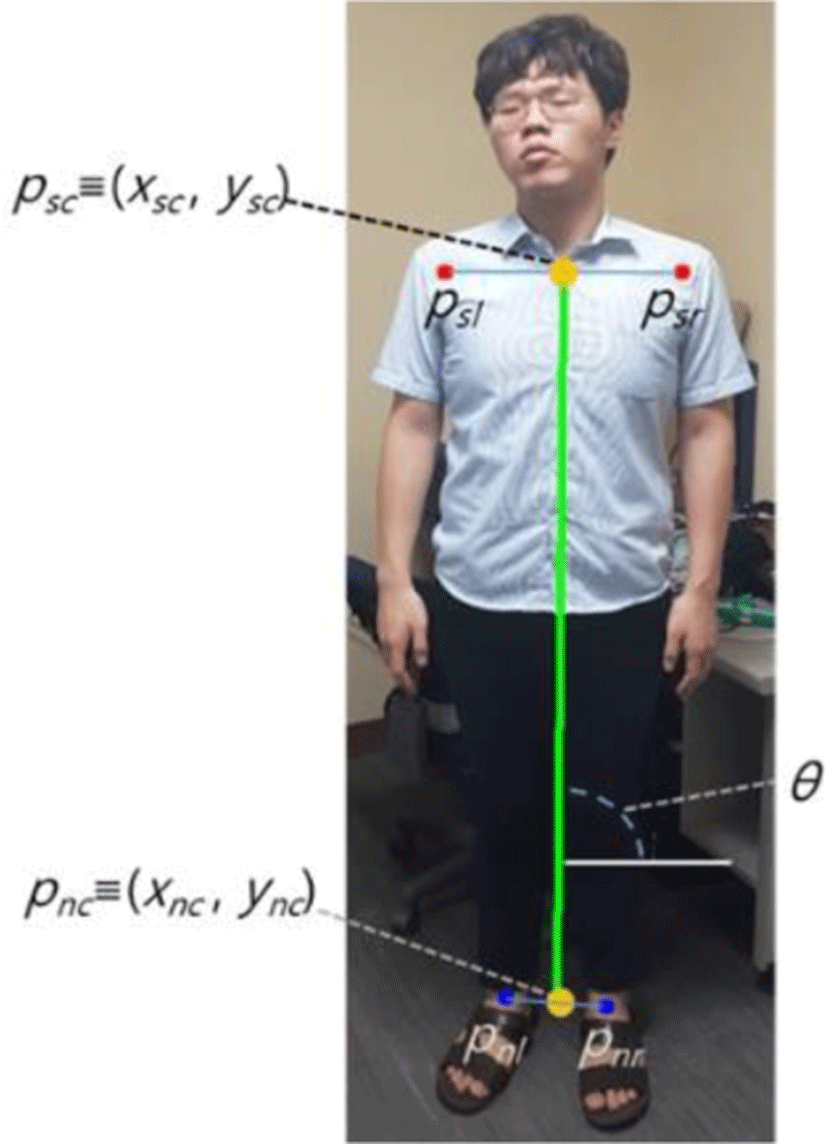
Also, we track θ of the centerline in the image. If the body is collapsing, then θ will get smaller. If θ falls below a certain value, then it can be judged that a person has collapsed. However, even in normal situations, such as falling sharply and lying on one’s stomach to sleep, the situation becomes smaller. Instead of using θ to distinguish these cases, we use θ’s amount of change. In the case of a sudden fall, the change in θ per frame will be dramatically reduced. The variation of θ in the n-th frame is calculated as the following:
If w(n) is less than Tθ, then it is determined that the frame is suspected as body falling. A sudden change in body posture or a sudden misdetection of a major part of the body can cause a sudden change in the amount of θ even if it is not in a fall situation. For this purpose, if the suspected fall condition persists for the duration of N frames, it shall be detected as a fall situation.
IV. SIMULATION RESULTS
The R50-FPN model is applied as a backbone of Mask R-CNN. COCO Dataset [17] is used for training set. 200,000 images are trained. 250,000 persons are included in the training images. The average precisions are 55.4 for detecting the boundary box and 65.5 for detecting the key points, respectively.
To measure the accuracy of the fall situation detection implemented in this paper, the experiment is conducted through images containing five scenarios shown in Fig. 5. At this point, the resolution of the images is 852x480. Fig. 5 (a)-(b) must be detected in the fall situation, and the remaining images must not be detected in the fall situation. In the experiment, Tθ and N are set at 76 and 6, respectively.

Fig. 6 shows the change in θ for each experimental image. For the images of Figure 5 (a)-(b) which are falling, the variation of θ in the fall situation is continuously significant. Conversely, in Figure 5 (c)-(e), which is not a fall situation, the change in θ is not significant, and is temporarily limited, if large.
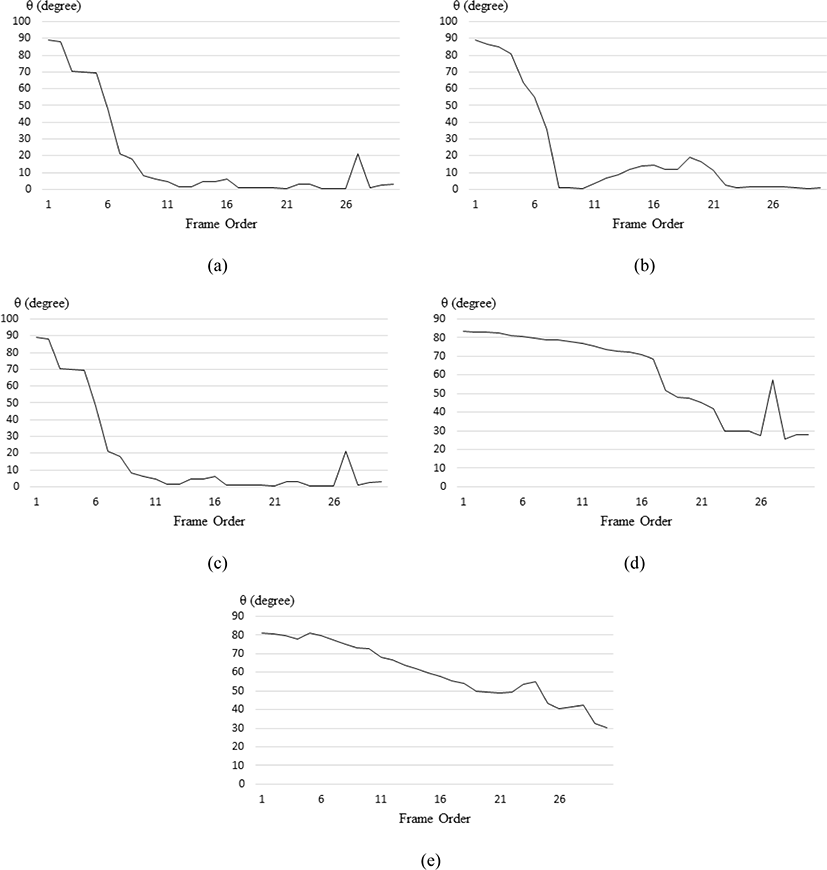
Table 1 shows the number of frames identified by the suspected fall situation in accordance with Tθ. At this point, the larger the Tθ, the smaller the number of frames mis-detected to the suspected fall situation in the scenario of Fig. 5 (c)-(e).
| Images | Tθ | |||||
|---|---|---|---|---|---|---|
| 5 | 10 | 15 | 20 | 25 | 30 | |
| Falling while walking | 15 | 6 | 6 | 5 | 2 | 2 |
| Standing fall | 16 | 7 | 5 | 5 | 3 | 2 |
| Head down | 0 | 0 | 0 | 0 | 0 | 0 |
| Lying down | 13 | 7 | 3 | 3 | 2 | 1 |
| Sit down | 10 | 4 | 4 | 3 | 2 | 2 |
Table 2 shows whether a fall situation is detected in accordance with N, the basis for the fall situation. If N is less than 3, it may be detected as a fall even if it is not a fall situation. On the other hand, when N is greater than 7, no normal fall situation was detected. This situation means that if a fall situation occurs in a moment and N is too large, it is rather impossible to determine the fall situation accurately.
| Images | N | |||||
|---|---|---|---|---|---|---|
| 3 | 4 | 5 | 6 | 7 | 8 | |
| Falling while walking | O | O | O | O | X | X |
| Standing fall | O | O | O | O | O | X |
| Head down | X | X | X | X | X | X |
| Lying down | O | X | X | X | X | X |
| Sit down | X | X | X | X | X | X |
Through the results, the proposed method accurately calculates the angle of the centerline for detecting falls, and the accuracy of the fall detection is extremely high. However, in the case of a person lying down (d), an inaccurate result occurs. In the future research direction, additional conditions should be studied, not just the amount of angular change in the centerline, in situations in which a person lies down.
V. CONCLUSION
In this paper, the method of detecting the area and major parts of the body accurately using Mask R-CNN and detecting the fall situation by detecting the center line was implemented. Through the proposed method, the fall situation could be detected more accurately through CCTVs installed indoors, and it would be possible to cope with an emergency. This will enable the detection of emergency situations of the elderly accurately, which will prevent human and property damage by informing them of the danger situation more quickly and acting against them.


