





I. INTRODUCTION
Recently, the deep learning is triggering the development of image analysis of various data types. Deep learning keeps the state of the art (SOTA) model in almost every field of image analysis by finding and learning the features, shapes and patterns of images. In the classification of ImageNet [1] and CIFAR10 [2] datasets, models such as InceptionResnet [3], and Big transfer (BiT) [4] utilizing ResNet [5] have been selected as SOTAs and many researchers are actively studying to achieve higher accuracy [18], [19], [20], [21], [22], [23], [24]. Based on these models, face expression recognition (FER), Face Recognition and Face Generation are being investigated. Most of face datasets are often taken in a laboratory or controlled in front. However, in real life, there are more pictures of different directions than the exact frontal one. There is a research [6] that present problems and analyzed only profile face data. If we can make a generation as good quality about the front one from the side view image, we can utilize it in various applications.
The main models in a field of image generation are Ganerative Adversarial Network (GAN) [8] and Variational AutoEncoder (VAE) [9]. In particular, many different GAN models focus on producing high image quality which the style is transferred. Concretely, there are some networks that generate images by extracting the characteristics of the image and synthesizing the disentangled attributes such as StarGAN [10], InterfaceGAN [7], CycleGAN [11], DiscoGAN [12], and StyleGAN [13].
Shen et al. extracted the latent space through the trained StyleGAN and proposed a methodology for various style edits [7]. As shown in Fig. 1, the more we change to the profile from frontal face, the more certain people lose their identity.

In this paper, we suggest a new method only using deep learning without image editing techniques for generating the frontal face from images of other directions. Conditional generative adversarial network (cGAN) generated an image corresponding to X according to stationary post-conditions Y as posterior X|Y [14]. Using this method, we generate a frontal face while Y is style condition, but we get style vector by our models instead of fixed value Y.
The four models that each model extracts diverse style of face are proposed. First, style-encoder model has a structure similar to discriminator, obtaining style vectors by image, and it’s called StyleEncoder.
The second model is advanced version of first model which has an attention mechanism by 1×1 convolution, defining A-StyleEncoder. Also, without training model which finds the style, use the classification model trained by another dataset to generate a frontal view. One of them is InceptionResNet trained by VGGFace2 and we compare the results each of models in experiments. A-StyleEncoder model gets the properties which are coarse feature of face like hair, beardand outline. The pre-trained Inception Resnet model extracts details of face such as eye, nose and mouth type. To combine these features together, we merge the model’s output and it could be considered not only specific area of face but also overall style. After, a style vector as input on generator, generates frontal face.
In next section, we will introduce other models and methodologies that define styles from image related to the suggested models. We propose a method for training each network’s parameters and the four types of style extraction model in approach in Section 3. In Section 4, we compare the output image of each model and PSNR result with the original image. Also, we will visualize the vector from the StyleEncoder model to check whether the style was extracted properly and specify the parametric structure of generator, discriminator and styleEncoder model. Finally, we explain limitation of the research, future work and important effect in Section 5.
II. RELATED WORK
The conditional-GAN [14] trains the model by conditioning a class label on the generator and the discriminator in order to generate an image of a given type that meets the desired conditions. The learning method is the addition of the condition y from the existing GAN structure as the following:
where D and G represent the discriminator and generator, respectively. x is a real image, z is a noise input for generating fake image. Conditional Generative Adversarial Network overcomes the limitations of the generated images with random Gaussian sample. In this paper, image-dependent vector by style network replaces class label y. The generator model is responsible for generating identically corresponding frontal face by the designed style encoder model.
A Style-Based Generator Architecture (StyleGAN) for GANs by NVIDIA, presents an advanced model which generates high-quality image [10]. The StyleGAN generates the image gradually, starting from a very low resolution to a high resolution. It modifies the central feature corresponding to each resolution for each level separately. Resolution of up to 82 affects pose, general hair style, face shape, and other levels affect more micro features. Also, the StyleGAN employed AdaIN (adaptive instance normalization) module that editing each channel by information vector w. This mechanism produces state of the art results with high resolution images, allowing for a better understanding of GAN outputs.
The InterfaceGAN proposes a novel approach, interpreting the latent space of GANs for semantic face editing [7]. Specifically, this research made latent space of image for finding semantic subspaces and using trained face synthesis model. InterfaceGAN is capable of changing several semantic elements (pose, gender, glasses, etc.) of application controllable trained StyleGAN model, but pose generation loses the meaning of determining the same identity in Figure 1. In this paper, we introduce how to produce an image without losing identity with a simple GAN structure.
As a backbone model, the residual network is widely taken into account for SOTAs. InceptionResnet [3] is Inception style networks that utilize residual connections instead of filter concatenation. One of models, Inception Resnet-v1, is a hybrid Inception version with significantly improved recognition performance. We select the InceptionResnet-v1 pre-trained by VGGFace2.
III. PROPOSED APPROACH
We point to the fact that the cGAN has fatal drawback property that class label y should be a fixed vector, passing on generator. If we want to produce an image explained by more complex style which unable to express in simple class, we cannot generate the desired image. On the other hand, a style-encoder alternates particular label, representing a different style of every image. Therefore, the formulation for training network as the following:
Each of θG, θD, θS, defines parameters of the generator, discriminator, style-encoder network and θ* is the optimal parameters. Model process is termed function f, then the optimal parameters of G and D are computed by:
Finally, we get f on x ∈ RC×W×H (C: channel,W, H: image of width and height.) in that xfrontal is the front face of x and xprofile is side one. Therefore, we can express as:
By this formulation, we can get the frontal face image by multi-view images.
The overall structure of the designed model is shown in Figure 2. If we insert the side face as the input, we extract the style vector through the style network. Extracted style vector is used in both generator and discriminator. The generator generates the front real image with the entered style vector. Discriminator receives the actual front or predicted front and side profile style vectors as inputs and finally learns whether the frontal face of the person is real or fake.
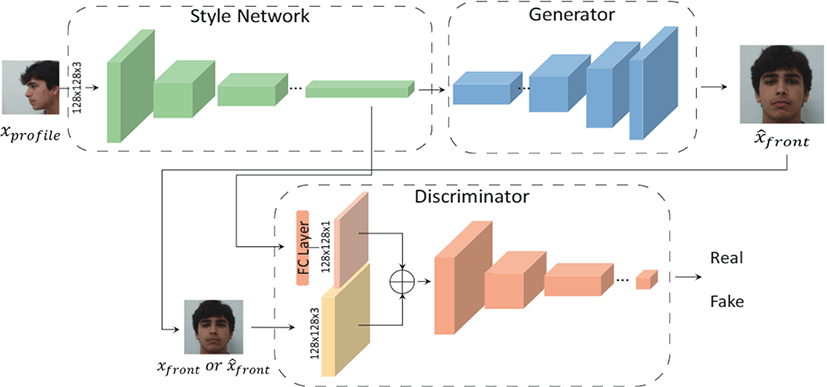
To give the generator using various style vectors, we design four types of models that can extract styles.
The StyleEncoder model consists of architecture similar to discriminator in that encodes an image. For an image, the image features are represented through a simple Convolutional Neural Network (CNN) structure of five layers. The activation function uses LeakyRelu and proceeds Batch Normalization (BN). The final size of the Style Vector is 1×1×512. If there is no attention module in Figure 3 of (a), it is a simple style-encoder model.
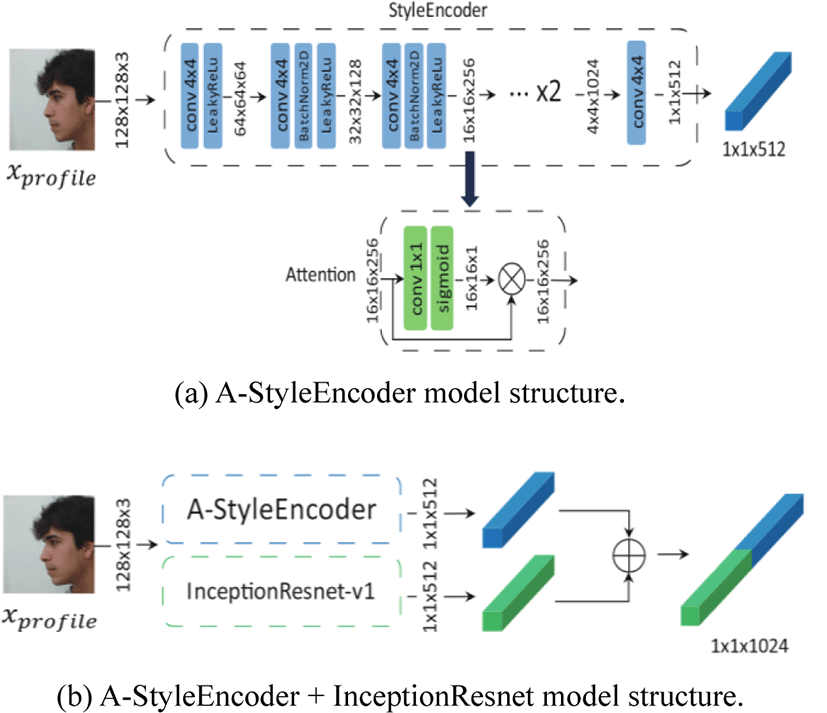
A-StyleEncoder is an advanced model of style-encoder as adding attention module to enhance features. The structure is Fig. 3 (a) and the feature selected in the middle stage of the style-encoder passes through a 1x1 convolution, sigmoid function and again multiplies itself. The output xl of middle layer can be given as:
where ⊗ denote element-wise multiplication, C(·) is point-wise convolution operation by 1×1 filter, and l is the output layer of attention module.
InceptionResnet [3] outperforms in area of classification and is widely used as a backbone network. We consider a pre-trained InceptionResnet-v1 by vggface2 dataset. This method recognizes our dataset image as 100 percent accuracy. As with other style-encoder models, the face style is drawn in size 1×1×512 with the input image.
Finally, we concatenate the outputs of A-StyleEncoder and InceptionResnet to make use of each property which determines type of style. A-StyleEncoder defines a style of around face (hair, beard, face shape) and InceptionResnet decides a feature to recognize people as eye, nose and mouth. Thus, to generate image of all types, we concatenate features together as Eq (8):
By concatenating these outputs as shown in Fig. 3(b), it is feasible to generate the frontal face by profile face.
IV. EXPERIMENTS
We used the FEI Face dataset [15] with 11 directions (1 front and 10 sides) for each of 200 individuals. We preprocess an image with Multi-task Cascaded Convolutional Networks (MTCNN) [16] to detect face and crop. The size of final cropped image is 3×128×128 (C×W×H). The input is ten profiles turned 18 degrees from -90 to 90 degrees. Both generator and discriminator were trained alternately, and the style model was trained with the generator. We set 100 epochs and took 20 hours with Geforce GTX1080Ti. We used the Adam optimizer and learning rate 0.0002.
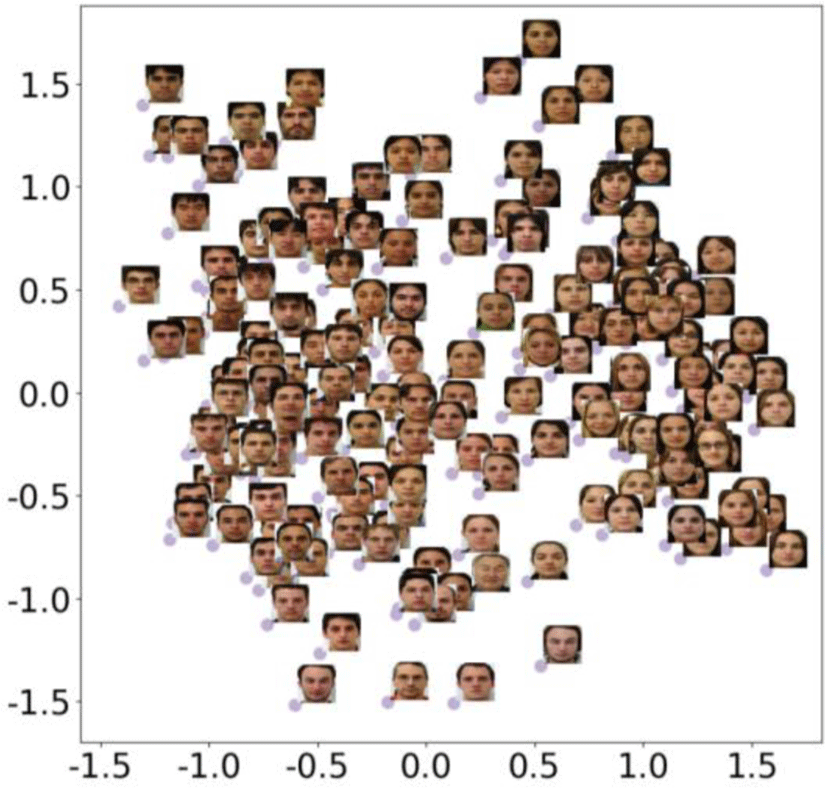
Before entering the generator and discriminator, we visualize the output features of A-StyleEncoder and InceptionResnet by concatenating them. The size of the total output feature was 1×1×1024. We used the principal component analysis (PCA) technique to project it in two dimension. The output of each model for visualization was aggregated as follows:
where α is set to 2, and the result of visualizing in two dimension through the principal component analysis (PCA) function as shown in Fig. 4. It can be seen that people of similar styles are grouped together. This means that the ‘A-SE + IR’ is effective.
Specific architectures of the generator and discriminator are shown in Table 1 and Table 2. Each model was referred to the architecture of DCGAN [17]. The generator produces images with a style vector, and the discriminator concatenates the input image and style to find out the real or false image.
The result of generating a frontal view from each person’s profile compares with the models of Style Network Architecture and the InterfaceGAN using the pre-trained StyleGAN on Flickr-Faces-HQ Dataset (FF-HQ). As we can see in Fig. 5, the merged version (A-SE + IR) of A-StyleEncoder and InceptionResnet outperforms than other style networks. As mentioned, A-StyleEncoder (A-SE) can extract type of hair, face shape (around of face) and select features such as eyes, nose and mouth better than other models on InceptionResnet (IR). The results of the ‘A-SE + IR’ model for others are shown in Fig. 6. It can be seen that hair styles and facial features are applied independently compared to other generator models. Hence, we consider the characteristics of A-Style Encoder and InceptionResnet at the same time and get the style of the whole face. Finally, we compared a Peak Signal-to-noise ratio (PSNR) of output results in Table 3. The proposed ‘A-SE +IR’ model obtained the highest PSNR value.


V. CONCLUSION
We have investigated some style extraction models and proposed a style extraction model called ‘A-SE + IR’ by concatenating the results of the attention style encoder model and the InceptionResnet for giving the condition of the generator and discriminator to generate the front face from the side. Also, we developed a frontal face generation module that would extract complex features by applying a conditional generator. This model not only extracts styles around the face such ascertain people’s hair styles, but also confirms that the facial features are well drawn. We verified the possibility of generating a frontal face with reliable quality, from side view images.


