





I. INTRODUCTION
People’s daily lives have been dramatically changed for the COVID-19 outbreak. The epidemic remains severe, as of April 20, 2021, the number of new confirmed cases of COVID-19 has increased for eight consecutive weeks. More than 5.2 million new confirmed cases over the world in this week, and the death rate of this week also increases compared to the previous weeks [1]. The virus-containing respiratory fluid from an infected COVID-19 person can remain airborne for several hours, which is also the main transmission way of the epidemic [2]. Masks are effective at defending the virus particles, so wearing masks scientifically is a simple and effective way to prevent the spread of COVID-19.
In the context of the epidemic, how to supervise wearing masks in the public areas is a key problem that needs to be urgently solved. Unfortunately, manual testing methods are still used in many places, which means inspectors are in infection danger and the detection rates cannot be guaranteed. Compared with other technologies, vision-based computer technologies have many advantages, such as low cost and high detection rate [3]-[6] . However, traditional method-based detection systems cannot overcome the complex problems in real environments, such as tiny targets, various targets, and complex backgrounds. Compared with them, deep learning-based methods can keep high accuracy even in complex backgrounds [7]-[9].
To alleviate these difficult problems mentioned above, a deep learning-based mask wearing system is developed in this paper, sufficient experiments have shown that the proposed system can achieve promising results in the real environments. However, deep learning-based methods always need many data to train, but because of the suddenness of the epidemic, the datasets are scarce for mask detection. Hence, a mask wearing dataset is collected in this paper.
The main contributions can be summarized as follows:
-
A powerful deep learning-based mask wearing detection system is developed to reduce the burden and the infection risks of the inspectors. The system can satisfy all the three requirements: image detection, video detection and real-time detection.
-
A deep learning-based multi-object detection is adopted, and this method has achieved promising results. In particular, some other detection methods can also be used in our system, here YOLO v3 is used as an instance.
-
A mask wearing dataset is collected to alleviate the scarcity of datasets.
The rest of this paper is organized as follows: Related works are introduced in Section II. Section III introduces the developed system in detail. Experiments are shown in Section IV to confirm the effectiveness of the proposed system. Finally, conclusions and future works are discussed in Section V.
II. RELATED WORKS
In recent years, deep learning has achieved remarkable performances in different important computer vision tasks, such as classification, detection, tracking, denoising and segmentation [10]-[12]. Besides, deep learning is also widely adopted in face-related tasks and has achieved remarkable performances [13]-[16].
The target detection methods can be briefly categorized into two classes, which are regression-based one-stage and multi-class classifier-based two-stage methods. Two-stage methods are typically designed for some multi-class detection tasks. Redmon et al. [17] proposed You Only Look Once (YOLO) and Liu et al. [18] proposed Single Shot Detector (SSD). Inspired by SSD, Yang et al. [19] proposed a cascaded tiny face detection method, which can achieve a satisfactory performance. The classical two-stage methods are the family of Fast R-CNN [20]. In this paper, a powerful detector YOLOv3 [21] is adopted to detect masks. Compared with two-stage methods, the detection speeds of one-stage methods are commonly faster and YOLOv3 can also achieve a significant performance with a satisfactory detection speed.
In the real environments, the input of the monitoring system is a video rather than a simple image. Compared with images, videos are more difficult to recognize, because there are many fuzzy relationships between frames and the data size of the video is greater. Hence, a real-time tracking method is necessary for reducing the computation costs. Yuan et al. [22] proposed a scale-adaptive object-tracking with occlusion detection. Park and Kim [23] proposed an interactive system based on efficient eye detection and pupil tracking method. Bewley et al. [24] proposed a simple online and real-time tracking (SORT) method, which established the relationship between different frames, and reduced the computational time.
There are also deep learning-based mask detection methods. [25] used transfer learning with three popular baseline models: ResNet50, AlexNet and MobileNet, in order to conduct mask detection. In [26], the mask detection algorithm can be used in real-time application.
III. SYSTEM DEVELOPMENT
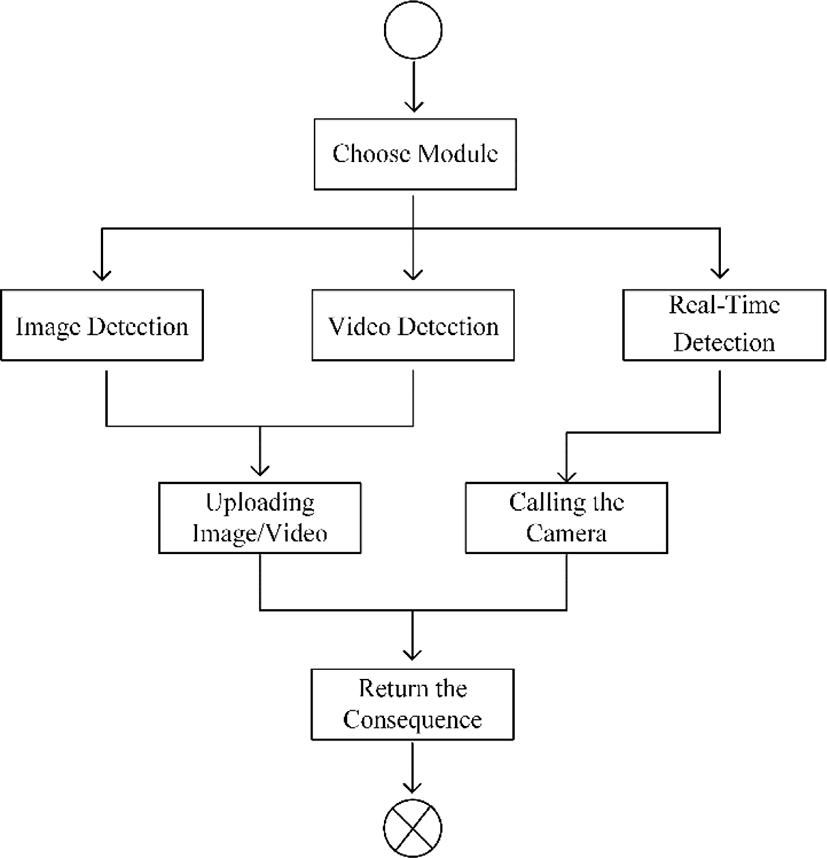
The proposed deep learning-based mask wearing detection system is developed based on Web. At first, the system calls the mask wearing detection model to detect and mark the masks on the uploaded images and videos. After that, the labeled images and videos are shown in the Web interface. The proposed system can be divided into three parts by functions, which are image detection, video detection and real-time detection. The whole framework of the proposed system is shown in Fig. 1.
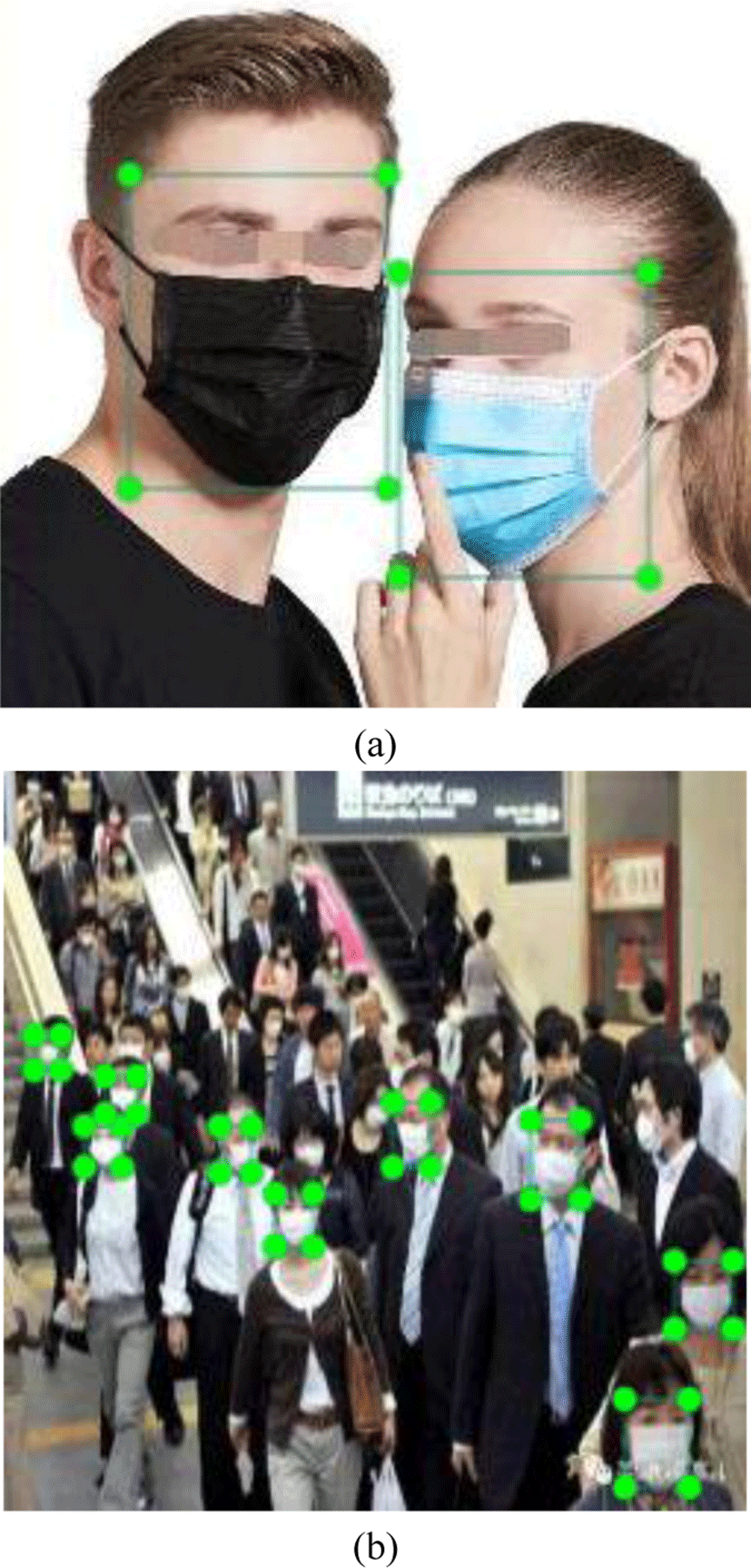
In order to alleviate the scarcity of wearing mask dataset, a dataset is collected in this paper. This dataset contains total 2370 samples, 1182 wearing mask samples and 1188 without mask samples, these images are collected. There are total 2 classes, which are “mask” and “unmask”, respectively. LabelImg is used to label these images. In order to conform the real environments, the collected images contain a variety of different scenarios. The collected and labelled images are shown in Fig. 2.
The image detection module is implemented based on a deep learning-based target detection algorithm. As introduced above, detection methods can be divided into two classes, which are one-stage-based methods and two-stage-based methods. Two-stage-based methods are suitable for a large amount of category detection, one-stage-based methods are suitable for a small amount of category detection. There are only two categories of targets in our system, face and mask. Meanwhile, one-stage-based methods are always faster, which can ensure the proposed system can achieve real-time performance. Hence, a one-stage-based method, YOLOv3 is adopted in this system to detect mask wearing, the backbone of YOLOv3 is ResNet53.
In this method, the image is divided into N×N grid cells, 3 scale boxes are predicted in each cell. The upper-left and low-right coordinates of anchors and the class are predicted. The detection task in this paper is a 2-class task, so the tensor is N×N×[3×(4+1+2)].
The activation function used is Leaky ReLU, the function is shown as follows:
where x is the input of this function, α is a predefined parameter in the range of (0,1).
Video is composed of many frames, so the video detection problem can be treated as the image target detection. However, it is unacceptable that each frame is detected based on the image detection method, which definitely causes numerous computational costs, and the real-time performance cannot be guaranteed. It is important to extract the implicit relationships between different frames to reduce the computational cost. In this paper, the simple online and real-time tracking (SORT) is adopted to achieve multi object tracking. In SORT, the inter-frame displacements of each target with a linear constant velocity model are approximated. The state of each target is modelled as:
where u and v represent the horizontal and vertical locations of the center of the target, respectively. s and r present the scale and the aspect ratio of the bounding box of the target, respectively. u′, v′ and s′ are the predicted state values by Kalman filter framework [27].
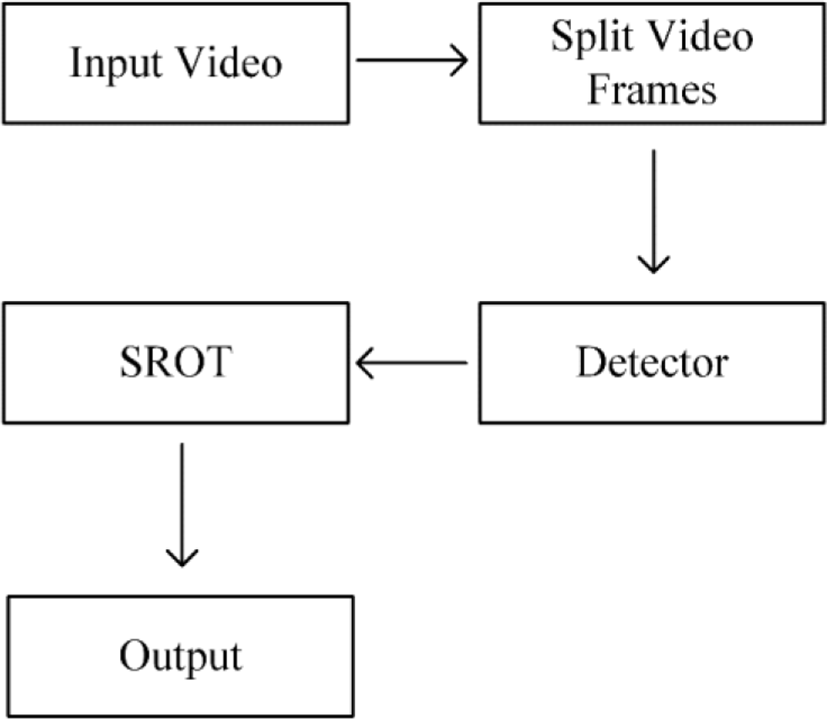
The video detection module is composed of detector and tracker, which can achieve high accuracy and satisfactory real-time performance. The framework of video detection is shown in Fig. 3, the input video is divided into video frames, and then these images are detected by the detector, and then the detected targets are tracked by SROT, and finally the labeled targets are passed to a Web interface as the output.
In order to achieve real-time monitoring function, an OpenCV based module is implemented. If the user chooses to real-time monitor, the module calls the camera to real-time detect mask wearing.
IV. EXPERIMENTS
In this section, experiments and implementation environments are introduced in detail. At the beginning of this section, we would introduce the experiment environments, including the versions of the equipment and the versions of the packages. The experiments are tested with Google Colab, the related environments are shown in Table 1.
| Environment | Version |
|---|---|
| GPU | Tesla P100 (16G) |
| CUDA Version | 10.1 |
| Operation System | Ubuntu 16.04 |
As introduced above, deep learning needs a large amount of data, but mask wearing dataset is scarcity. To alleviate this problem, a dataset is collected in this paper. This dataset contains total 2370 samples, 1182 wearing mask samples and 1188 without mask samples, these images are collected from Internet, 80% data is random selected as the training data, and the rest is selected as the testing data.
The proposed system is coded by PyTorch [28] and OpenCV, the main related versions of the used packages are shown in Table 2.
| Package | Version |
|---|---|
| PyTorch | ≥1.5.1 |
| numpy | 1.17 |
| Python | 3.6.0 |
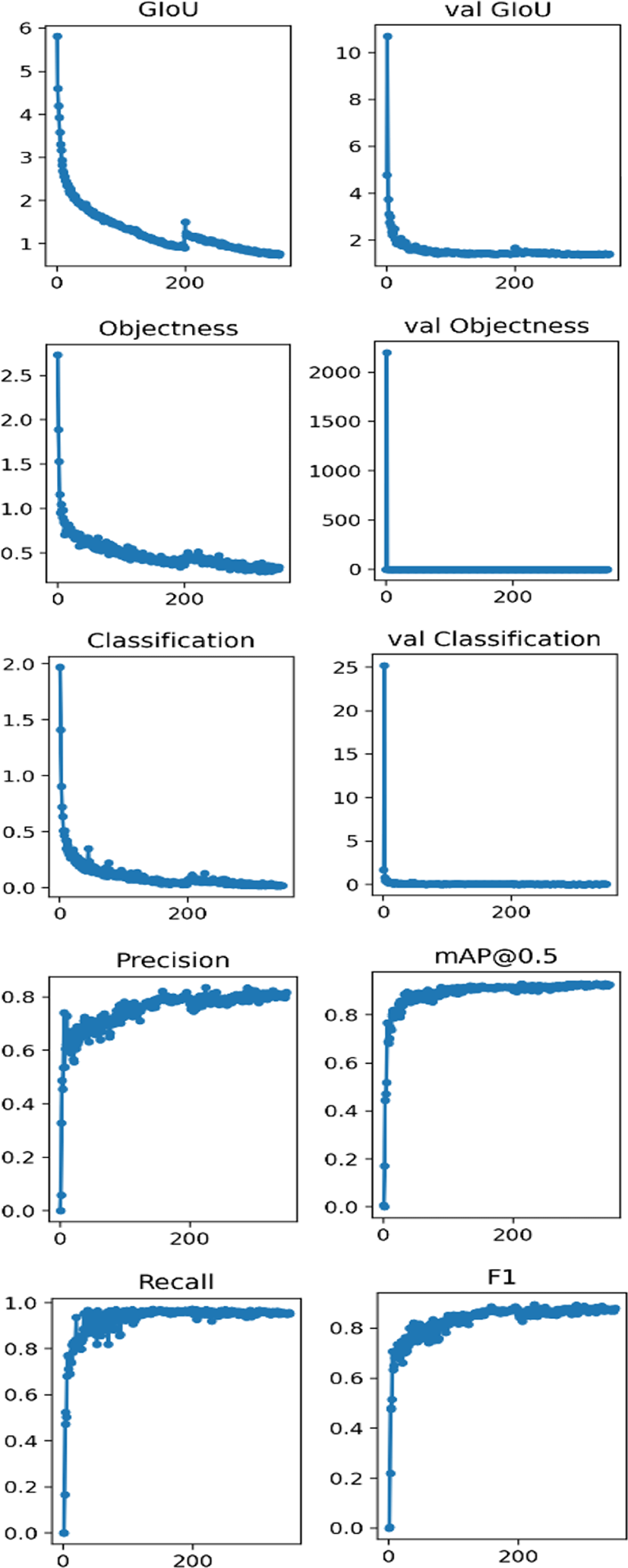
At first, we tested the image detection module of the proposed system. As the results shown in Table 3, the image detection module can achieve satisfactory performance in image detection. Meanwhile, the training process is shown in Fig. 4, the proposed system can converge quickly and the detect performance is promising.
| Class | Precision | Recall | mAP@0.5 | F1 |
|---|---|---|---|---|
| all | 0.866 | 0.967 | 0.962 | 0.914 |
| mask | 0.846 | 0.971 | 0.952 | 0.906 |
| unmask | 0.884 | 0.963 | 0.972 | 0.922 |
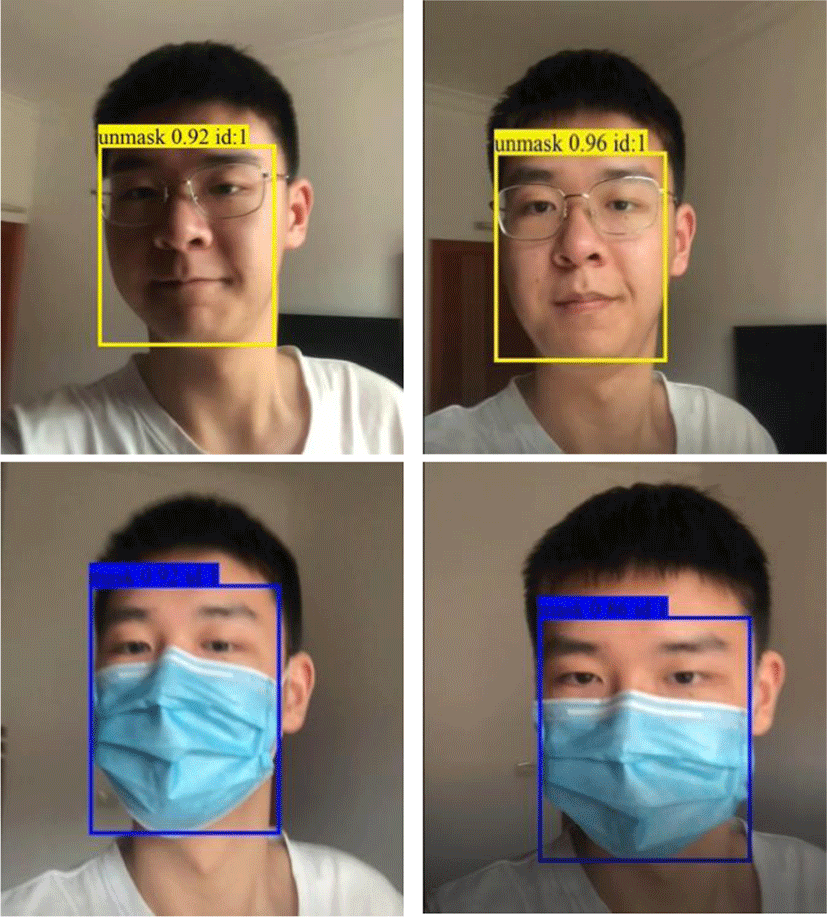
The detected samples are shown in Fig. 5. It can be seen that the proposed system can detect targets accurately in multi-objectiveness and complex environments, and the detection speed is 12.7 ms per image, about 80.65 frame per second (FPS), which can achieve the real-time requirement.

Meanwhile, we test the real-time monitoring and video detection modules, the results are shown in Fig. 6. The proposed system can achieve real-time detection and monitoring. Furthermore, the outpour of the system can be displayed in the Web interface accurately.
V. CONCLUSION
In this paper, a deep learning-based mask wearing system is implemented, which can work on personal computer without any high equipment requirement. Meanwhile, a mask wearing dataset, is collected to alleviate the scarcity of the similar datasets. The proposed system can achieve remarkable mask detection performance, and mAP is 96.2%, which is promising. Besides, the proposed system can achieve real-time detection based on low equipment. In the future works, we will increase the expansibility of the system, such as adding crowd-counting module and dangerous action recognition module. In addition, we will try to modify the model to improve the performance.



