





I. INTRODUCTION
Due to the COVID-19 pandemic, economic activity is contracting, and accordingly, a considerable amount of capital is flowing into the fund market. Accordingly, interest in forecasting for fund investment is also increasing. Capital Asset Pricing Model (CAPM) [1], a representative investment prediction model, calculates the expected return of an investment company using the risk-free rate of return, expected market return, and beta. However, forecasting through CAPM requires the premise that all investors have risk aversion. In addition, CAPM has a disadvantage in that the amount of information required for investment prediction is large. Recently, several methods of making investment predictions through machine learning have been proposed. There is a method of recommending products using existing investment data by showing the ranking of the products that have made the most profit in the last three months, six months, a year, and three years, or recommending them through weekly sales or set amount increase rate. The subjective recommendation method of each platform can also be determined by the recommendation fund selection committee using quantitative and qualitative evaluation. In the case of alpha funds, different from the selection criteria for recommended funds, they are recommended according to market conditions. However, in the case of such an existing method, there is a problem that it is difficult for general investors to use [2].
Most of the existing fund recommendation systems are formula-based. The formula is designed with the fund to be recommended and the degree of usefulness and user information as parameters. The fund is recommended through the optimization of the estimation result through the formula by a specific performance problem. The formula used in the formula-based system is often customized based on the experience of a recommender. Therefore, the fund recommendation through the formula-based system is highly likely to be biased towards the recommender.
In this paper, we propose a method for predicting fund prices through a machine learning method which predicts time series data. The fund price is predicted by Prophet model, which is an algorithm for predicting time series data [3]. The daily fund prices for 380 funds are learned by Prophet. The future fund prices are predicted based on given previous prices. The prediction results are visualized on the web page as graphs.
II. RELATED WORKS
Existing methods for predicting financial products such as stocks and funds include Bollinger band, Dow theory, and Kostolani egg [4]. Bollinger band is an index that combines the average trend and volatility of stocks and was invented by an investment expert named J. Bollinger in the early 1980s. Bollinger band provides a standard for evaluating whether the current stock price is overvalued or undervalued. Bollinger band generates the bands of upper, lower, and center lines according to the movement of stock prices. The stocks are sold or bought as the stock depending on the type of band the stock price approaches.
Dow theory was devised by C. Dow, who created Dow Jones Industrial Average in 1882. Dow theory analyzes the movement of stock prices and the trend between stocks. Dow theory assumes that stock price movements are trending rather than random. If the stock price continues to rise, predict the stock price under the assumption that the trend will continue. In the Dow Theory, trends are divided into accumulation, boom, overheat, dispersion, panic, and recession.
Kostolany egg is a theory proposed by A. Kostolany, who worked as an investment analyst in the U.K., and divides the market into a boom and a recession depending on the interest rate situation. It is a theory that recommends taking a portfolio. When interest rates peak and interest rates fall, they invest in bonds, when interest rates approach a trough, invest in real estate, when interest rates rise after a trough, invest in stocks, and when interest rates rise near a peak, they invest in cash.
Time series data means data recorded sequentially according to the passage of time. The prediction problems through time series data are used in various fields ranging from forecasting major economic indicators to predicting the demand for a certain product.
Studies for predicting time series data by neural network have been conducted due to the success of recognition and prediction in various fields through the neural networks. However, the previous structure of neural network, DNN (Deep Neural Network) [5], does not suitable for predicting time series data because it is a structure that does not consider the order of data input time. RNN (Recurrent Neural Network) [6] is introduced to predict the time series data. RNN has the characteristic of sending the result value obtained through the activation function at the node of the hidden layer to the output layer as well as the input of the next calculation of the node of the hidden layer. The RNN has the characteristic of outputting the result data processed at the node and inputting the corresponding output value to itself node along with the next input data. Therefore, the previous input data is also considered in calculating output data. However, the performance of RNN drops sharply for long time series data because of the gradient vanishing problem of RNN. It causes the problem of long-term dependencies that the data from the distant past rarely reflect.
LSTM [7] overcomes the shortcomings of RNN by introducing long-term and short-term data. The input and output of the short-term data is the same as RNN. The long-term data reflects current inputs through the corresponding weight for each step. In this way, important data from the distant past can also be reflected in the forecast.
III. FUND RECOMMENDATION BASED ON INVESTMENT PROPENSITY
The investment propensity of users is classified through the investment propensity diagnosis list [8] distributed by the Korea Council for Investor Education to diagnose the investment propensity. The investment propensity diagnosis list consists of questions about an age, investment experience, knowledge level of financial products, the amount of tolerable loss, an investment period, the ratio of investment funds to total assets, and the trend of increase or decrease in income as shown in Table 1. The answers of the user are scored and are classified into the following six types according to the score: an aggressive investment type, an active investment type, a risk neutral type, a stability-seeking type, and a stability type.
The funds are classified into six ratings based on the level of risk. The criteria of the fund risk classification refer to that of the established banks [9]. We recommend the fund with a risk rating that is appropriate for the investment propensity. The funds with low risk are recommended to the users with a safety-oriented investment propensity and the funds with high risk are to the user with offensive investment propensity. Table 2 shows the types of the recommended funds based on the user propensity.
| User propensity | Fund |
|---|---|
| Offensive-investment | Grade 1 |
| Grade 2 | |
| Active-investment | Grade 3 |
| Risk-neutral | Grade 4 |
| Stability-seeking | Grade 5 |
| Stable | Grade 6 |
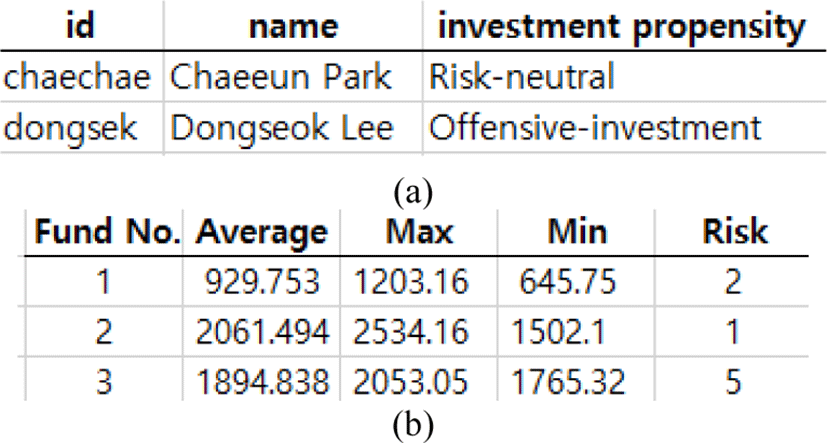
The investment propensity is identified through the questions in Table 1. The result of the investment propensity identification is represented to the users and is stored with user personal information into a database. The fund information is also stored in the database. The fund information is composed of a name, a risk level, and average, lowest, and maximum prices. Fig. 1 shows the user and fund information that are stored in the database. The user is matched based on the user and fund information in the database. First, the investment propensity is determined by scoring the responses of the user derived from the propensity diagnosis list. After that, the proposed system finds the suitable funds in the database based on the investment propensity. The system shows the found funds to the user. Fig. 2 shows the flow of the proposed fund recommendation method.
IV. FUND PRICE PREDICTION BY MACHINE LEARNING
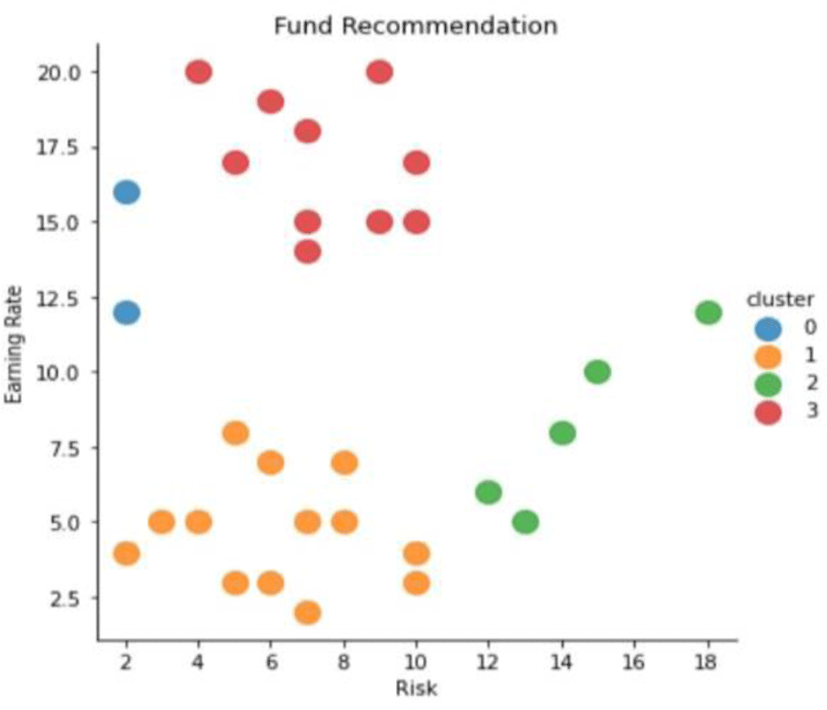
For the funds, the K-Means algorithm can be applied to classify funds according to the relationship between risk and return. In K-Means, the elbow method is applied to determine K which is the number of the fund clusters. As the number of the clusters increases, the average distance between centroids, which is the center point of each classified cluster, decreases. The decrease in the average distance is significantly reduced when the number of clusters is greater than or equal to a specific number. The specific number is determined as K. Fig. 3 shows that the results are divided into four groups, meaning low risk + low return, low risk + high return, high risk + low return, and high risk + high return. Although the K-Means algorithm can cluster fund propensity, it is difficult to clearly determine the variables that affect the fund price.
The Prophet model is applied to more accurately predict the future fund price through the relationship between the fund price and the fund’s variables. Prophet model is a time series prediction library developed by Facebook and can be used in the form of a Python package. A prediction by Prophet model is made through the following equation.
where y(t), g(t), s(t), and h(t), and ei are a predicted result at time t, a growth function, a seasonality function, a holidays function, and the error assumed to be normally distributed, respectively. The growth function represents a change trend, that is a continuous change of measurement target. Parameters in the function indicate whether the value is continuously increasing or decreasing. The parameters may change when checkpoint is reached because the trend of change can change at a specific point. It is probabilistically determined whether a particular point is the checkpoint. The seasonality function means periodic changes within the overall change trend. The periodic changes are represented by Fourier series function. The holidays function means the effect of an event occurring at a specific point. For example, sales of products increase significantly with each holiday. Prophet model treats the prediction as a curve fitting problem so it can avoid temporal dependence. Therefore, the prediction equation of Prophet model consists only of the sum of several linear or nonlinear functions. This characteristic of Prophet model makes the prediction learning easy and fast. The parameters of component functions in Equation (1) are determined by training through the past data. Prophet model predicts not only the future values but also the prediction value ranges.
The Prophet model requires the data information and numerical values as input. If the price of a commodity over a period of time is known, the future price of the fund can be predicted. The change points are automatically detected to predict growth, and patterns that appear periodically as user behavior patterns can be applied. Cross-validation is used to measure prediction accuracy. Cross-validation is a variety of similar model validation techniques for evaluating how statistical analysis results generalize to independent data sets. The cross-validation procedure is performed automatically for historical cutoff ranges using the cross-validation function. Specify the prediction period and then optionally the size of the initial training period and the interval between the cutoff date. The output of cross-validation is a data frame with actual and predicted values for each simulated predicted date and each cutoff date.
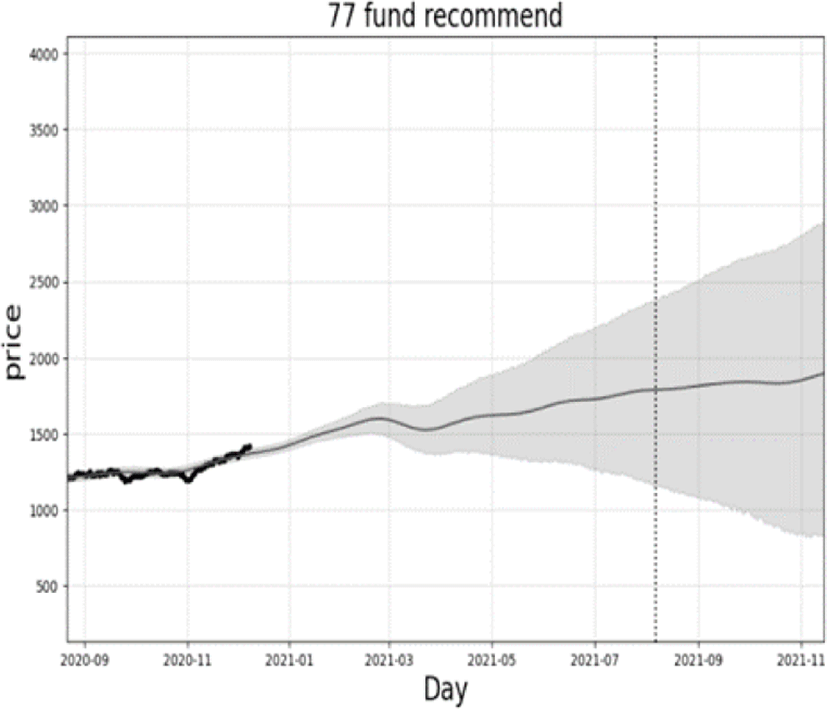
In the proposed system, the prediction model is trained from the fund prices over the past 4 months and predicts the future prices. The predicted results are presented as graphs on the web page as shown in Fig. 4. In Fig. 4, a black line and a gray line are the measured past prices and the predicted prices, respectively, and a gray plane is the range of prediction error.
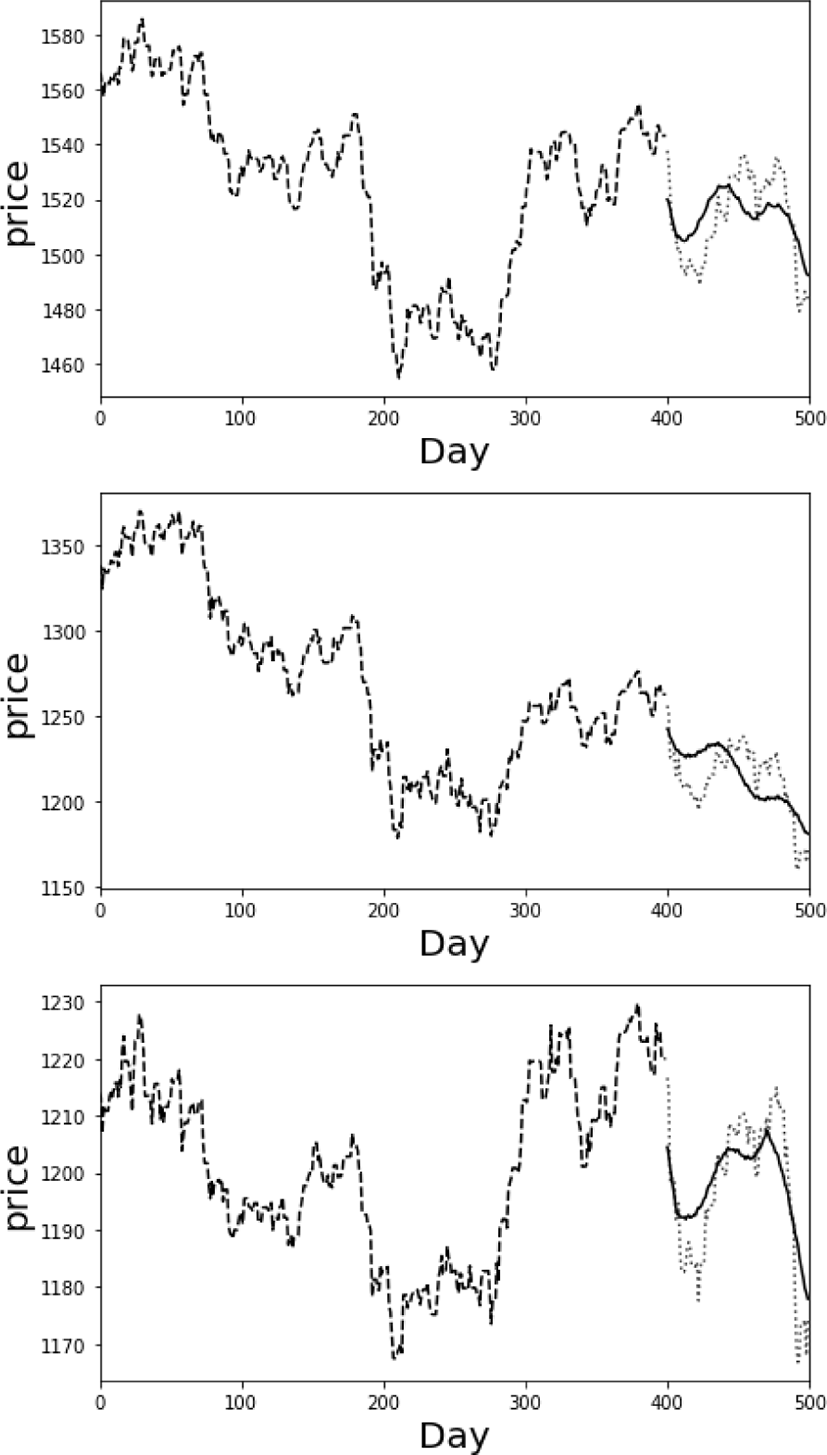
We measure the prediction accuracy of the proposed method through 380 fund data. In the fund data, the fund price for 981 days is stored. The prediction model is learned by the first 400 days and the fund prices after 100 days are predicted. Fig. 5 shows the results of the prediction results for various funds. In Fig. 5, black dash lines, black solid lines, and gray dash lines are the input fund prices which are used to learn the prediction model, predicted fund prices, and actual fund prices, respectively. The results show that the proposed method is insensitive to the actual price change, but accurately predicts an up- or down-trend in price.
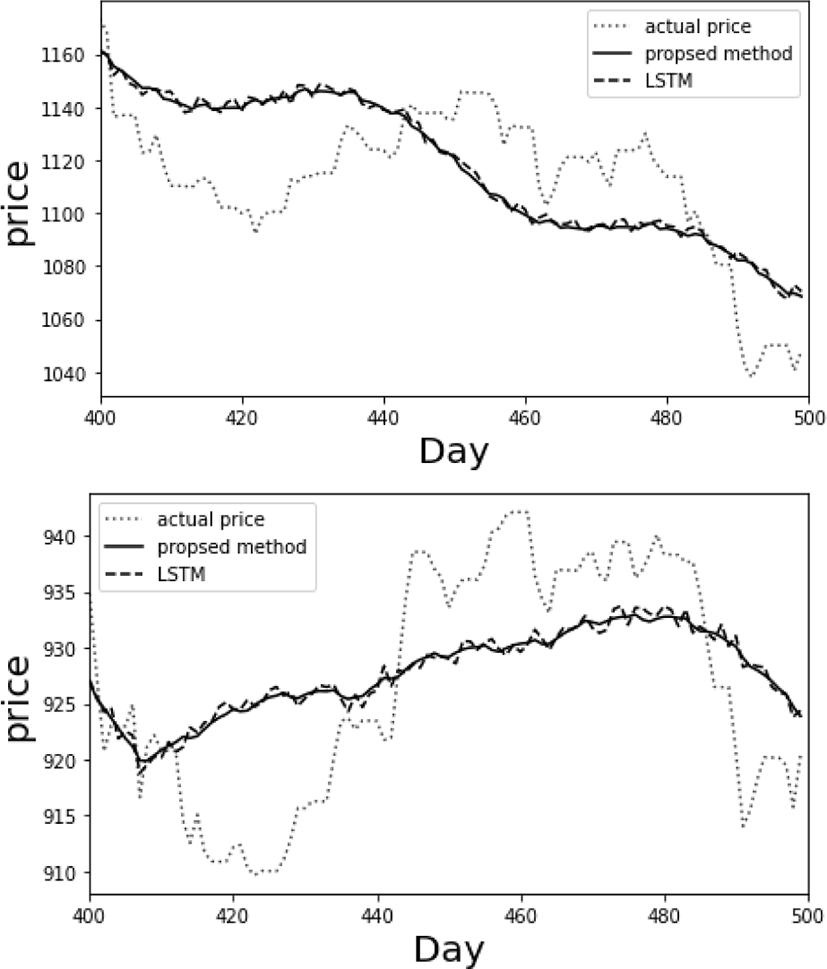
The proposed method is compared with the prediction method with LSTM. LSTM can be also used in predicting the future fund price [10-11]. Fig. 6 and table 3 show the comparison between the proposed method and LSTM. The error of the fund prediction is calculated through the RMSE calculated as follow.
| Prediction | RMSE | Prediction time (s) |
|---|---|---|
| Proposed method | 45.181 | 1.4 |
| LSTM | 44.918 | 2.1 |
where yi and ŷi mean the actual fund price and the predicted fund price on the i-th day, respectively. LSTM also predicts the future fund price well. However, LSTM requires a high-performance processor and a GPU, and requires a lot of data and time to learn. The proposed method is faster than the prediction method by LSTM.
The past fund price learning can be adjusted by changing p, which is a parameter of g(t) in Equation (1). The update cycle of g(t) is faster as the parameter p is larger, so the prediction adapts more quickly to the latest changing trends. However, too large p causes the overfitting problem that the prediction is too dependent on the past fund prices, so the prediction accuracy is rather drop. Therefore, finding an optimal p is important for the prediction accuracy. Table 4 shows the prediction accuracy according to p. The prediction is most accurate when p is 0.3.
| p | RMSE |
|---|---|
| 0.1 | 48.140 |
| 0.3 | 45.181 |
| 0.5 | 46.413 |
| 0.8 | 47.692 |
| 1.0 | 47.824 |
V. FUND RECOMMENDATION AND PREDICTION SYSTEM
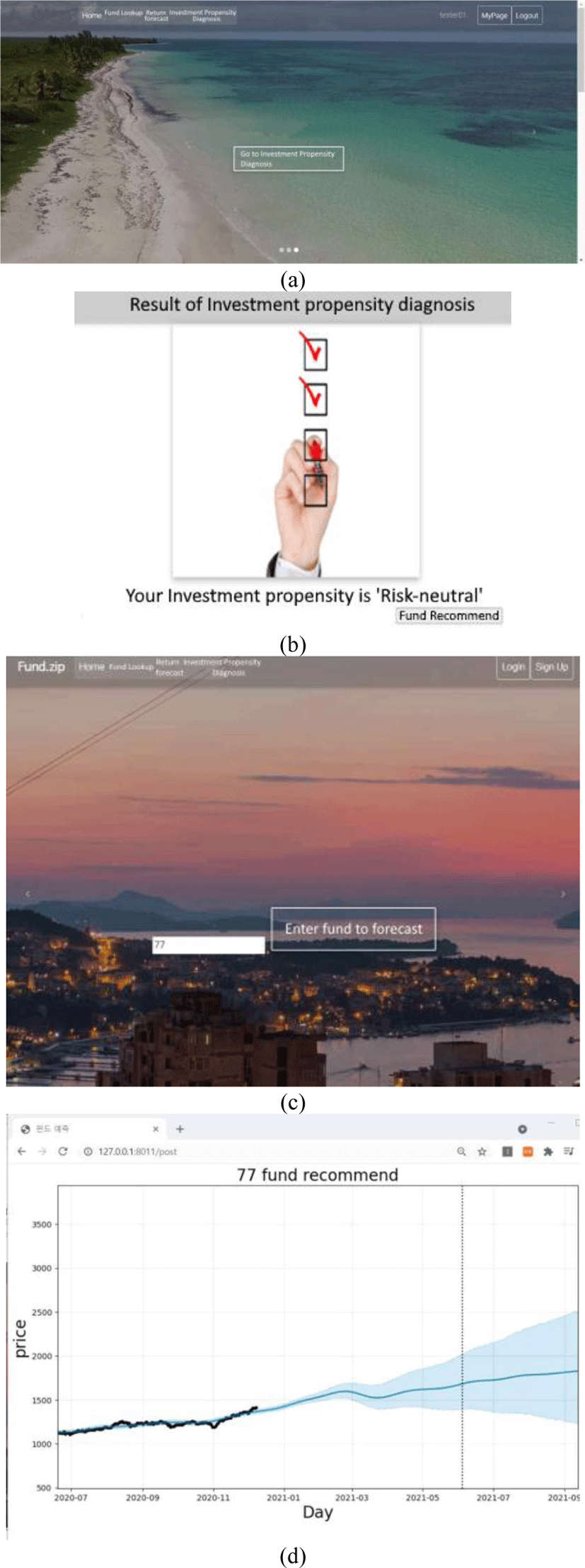
We implement a web page for the fund recommendation and the future fund price prediction. First, the user input his personal information. The user can understand his investment propensity by answering the questions in Table 1. The user can be recommended to the suitable funds based on his investment propensity. The user can see the price prediction of the fund he wants. Fig. 7 shows the implementation of web pages for the fund prediction through the proposed method.
VI. CONCLUSION
In this paper, fund information was collected through crawling, followed by analysis, and funds were visually classified through the K-Means algorithm by recruitment method, investment target, and management strategy. Based on the results, a price prediction program using Prophet was built after that. If you use this technology, you can check the future return of the entered fund. It provides economic feasibility that saves time and money by allowing you to understand your investment propensity without spending extra time and recommends a suitable fund. In addition, in the existing fund-related website, only fund information inquiry was possible, but this paper has originality by storing the inspection product. The website was built in consideration of UI/UX so that users can intuitively view and use it with high satisfaction. In the case of price prediction, since the learning result is not the same every time, a highly reliable recommendation is made through multiple learning and shows different results for each person. This will help hyper-personalization in the era of digital transformation [12].



