





I. INTRODUCTION
Nowadays, cameras and vision sensors, particularly those in smart devices and Internet-of-Things (IoT) are pervasive. 6.64 billion people use smartphones worldwide, which is more than 83% of the world’s population, according to BankMyCell [1]. A digital camera is a versatile tool that captures meaningful moments in a photo-graph to explore various context, create values, and identify problematic challenges such as accessibility issues [2]. Many qualitative research methods, such as “photovoice” [3-4] use photos taken by participants or communities to observe and identify theme-oriented problems and solutions. Since researchers tackle different domains and specific themes, a varying set of questions or requests is given to participants to collect relevant data and elicit insights from discussions. To meet the demands and reduce the burden on researchers and end-users who use photographs in their studies and life-logging, we propose a general-purpose yet integrated digital toolkit to serve this purpose. There are many potential applications to consume these personal data if a smart device application can capture images as qualitative personal data and record quantitative personal data. Additionally, it will be easier to concentrate on only relevant data if researchers and end users are able to identify their objective or select a group of data to be collected. Our contributions on this paper are as follows.
-
We explore how a digital toolkit in a cross-device and multi-sensor environment can configure smart devices and sensors of interest for qualitative and quantitative research methods (i.e., photovoice and experience sampling methods [5]) by enriching photographs with in-situ user-provided descriptions and system-generated records.
-
We investigate the viability and possibility of cross-device and multi-device data gathering and interpretation because many people use many devices at the same time. We require a method for quickly sharing personal data in an interoperable format after it has been obtained.
-
We offer suggestions for data integrity, data sharing, and data exchange formats to accelerate interoperable data sharing between researchers and end users.
II. RELATED WORK
Digital photographs are an expressive and easy-to-produce medium for both researchers and end-users. Koch and Maaß investigated a digital diary application as a digital probes kit to document the day using various media, answer questionnaires, create content, and take pictures [6]. Several digital diary approaches used geo-tagged multimedia content [7], emotion-based life-logging [8], and participant-generated photographs [9]. Tan et al. explored using a digital crowdsourcing strategy to involve the community in clinical trials [10]. As illustrated in Fig. 1 and Fig. 2, researchers use photographs as a tool to gather qualitative data, and users use photographs to concisely capture and share their meaningful moments.


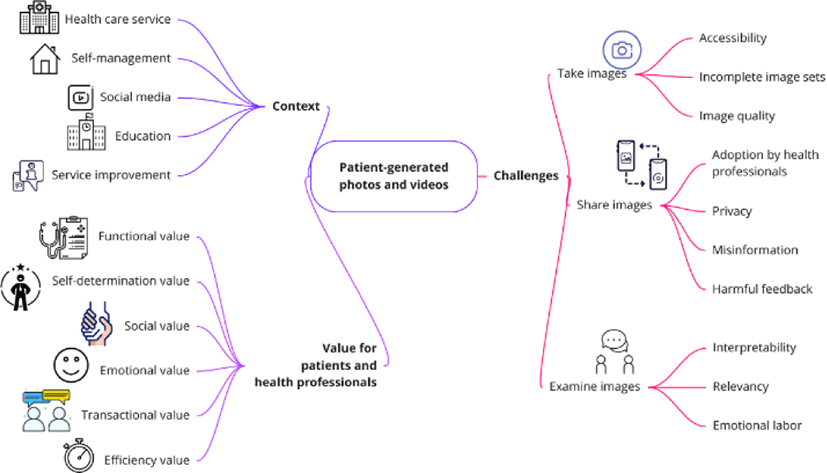
Key themes in patient-generated images and films, such as contexts employed, values attained by patients and medical personnel, and difficulties encountered, have been discovered by Ploderer et al. [11]. Fig. 3 illustrates how patient-generated photos and videos are useful in research.
Digital technologies were investigated by Bruckermann et al. for citizen science during the stages of data collection and analysis [12]. Sharples et al. developed a sensor toolkit, the Senseit app, to access embedded sensors on Android smartphones [13]. Our approach is similar to digital diary studies, where we use user-taken photos as the qualitative data source. However, we further encode and enrich these photos with sensors, as explored by [13], and third-party APIs for participatory research and civic participation tools [14]. Comparative summaries of previous studies are provided in Table 1.
| Studies | Brief description |
|---|---|
| [6] | Digital probes kit using questionnaires and pictures |
| [7] | Digital diary using geo-tagged multimedia |
| [8] | Digital diary exploring the life-logging concept |
| [9] | Mobile app for visual research using photographs |
| [10] | Digital crowdsourcing in the clinical trials context |
| [11] | Key themes and challenges in patient-generated images |
| [12] | Exploration in citizen science for data collection/analysis |
| [13] | Using embedded smartphone sensors for data collection |
| [14] | Outlining requirements for local civic participation tools |
III. DESIGN OF MULTI-SENSOR AND CROSS-DEVICE TOOLKIT
To gather data across several smart devices, both qualitative and quantitative, we created an integrated digital toolkit. Fig. 4 depicts the digital toolkit we propose. Smartphones, smartwatches, and smart glasses are just a few examples of smart devices that can run the proposed digital toolkit as an application.
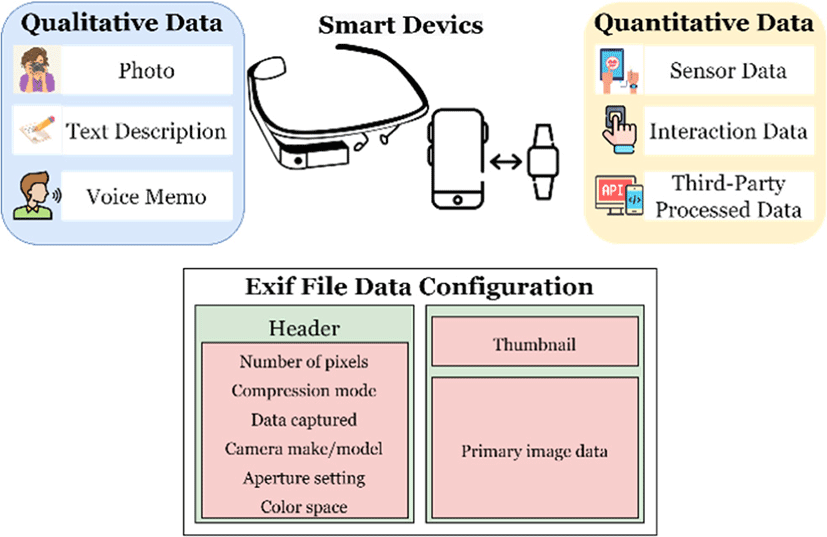
When a user of this digital toolkit takes a picture, the user can leave text or voice messages on the picture. This produces qualitative data such as photo, text description, and voice memo. Qualitative data is categorized by how they are expressed, usually in descriptive language rather than numerical data. For example, photos can be labeled or described (i.e., a man is wearing a hat), and text and voice memos can be written and expressed in English.
For quantitative data, we collect multimodal data from embedded sensors [15], user interaction data, and third-party processed data. Data that can be measured and expressed as a numerical value is referred to as quantitative data, as opposed to qualitative data. An ambient light sensor, for instance, monitors ambient light in Lux units. In an application, the total number of user clicks can be counted. Image size is expressed as a number. Additionally, further interpretation of raw data is possible by using third-party APIs such as Google Vision AI (https://cloud.google.com/vision/) and Kakao Vision API (https://vision-api.kakao.com/). With the aid of these multimodal data [15], designers and service providers may better understand their target demographic and create systems that cater to their demands.
This concept is already used in Exif (Exchangeable image file) where digital camera-related information (including geolocation) is stored. Our goal is to expand this concept so that it can be applied to smart devices and third-party APIs like vision APIs. The targeted embedded sensors include motion, environmental, positional, ambient light, proximity, accelerometer, gyroscope, barometer, and micro-phone data.
It is important to consider cross-device and multi-device environments [16], as shown in Fig. 5 since many people carry more than one connected device with different levels of sensor accuracy, resolution, and sensing interval [17]. Our proposed digital toolkit supports Android-based smart devices (i.e., Google Glass Enterprise Edition 2, Samsung Galaxy Smartphone, and Samsung Galaxy Watch 4).

Wearable smart glasses such as Google Glass feature always-on, always-accessible, and always-connected characteristics. Various sensors and cameras in these wearable computers enable many engaging scenarios [17-20] including medication information provision [21] to provide essential information. For example, Apiratwarakul et al. explored using smart glasses as a tool for assessing people in masscasualty incidents [22]. We propose integrating third-party API, such as text recognition API, to automatically translate the acquired photo in order to support and develop a prospective killer application for wearable smart glasses in participatory research.
Once these user-generated photographs with additional contextual information are collected, we must provide efficient and effective data-sharing and exporting methods. For example, we store integrity-checked photographs (i.e., MD5 checksum) in interoperable file formats such as JSON and XML. JSON and XML allow user-defined custom tags and values to be easily expanded to include user-annotated comments, ratings, and voice memos. These file formats can also be easily exported and refined by setting different conditions, such as filtering by dates and sensor value thresholds. These data are kept in a cloud database, a local SQLite database, or an internal program directory on an Android platform.
IV. PROTOTYPE DESIGN AND IMPLEMENTATION
We implemented a prototype to demonstrate our digital toolkit. The prototype can take pictures, add tags to the pictures, and export them as JSON files. Fig. 6 shows a user taking a photo of a ceiling fan and adding user-specified tags using an Android smartphone application. We developed our application using Java with the Android Studio (https://developer.android.com/studio) Bumblebee 2021.1. 1 version. We have tested on android virtual device (AVD) as well as on two Android smartphones (Samsung Galaxy Note 9 running Android 10 OS and Samsung Galaxy Note 10 running Android 11 OS).
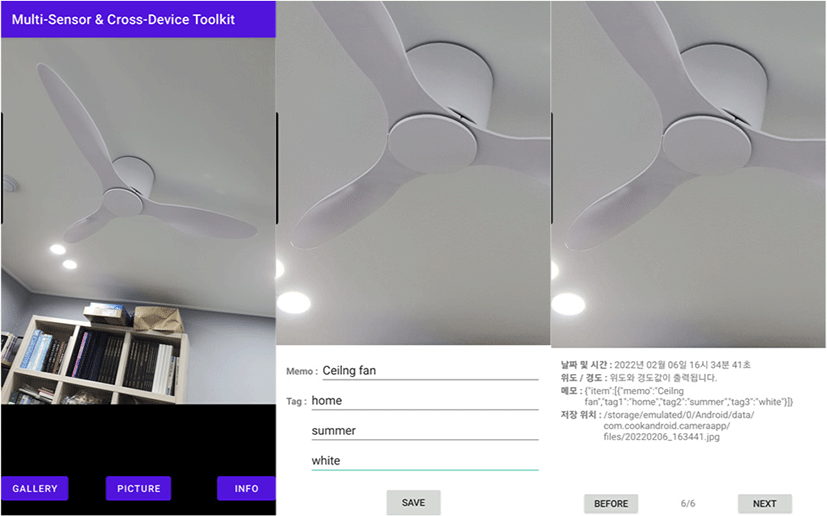
Fig. 7 and Fig. 8 shows a Google Glass application for automatically interpreting texts on a user’s view by taking a photo and running through a text recognition API. This photo is then analyzed by text recognition API (Application Programming Interface) and outputs a series of recognized texts. To implement and simulate this application, we designed a database to contain pre-registered textual information that can be matched and retrieved by text recognition results. Then automatically recognized information is concisely delivered using text-to-speech (TTS) or a comprehensible form of intuitive instruction layout.
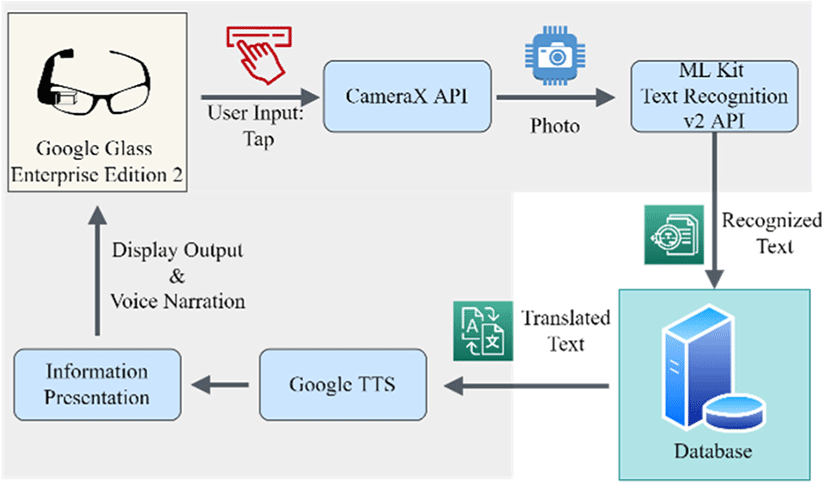

Our wearable prototype was designed and implemented on Glass Enterprise Edition 2 (GEE2) by Google (https://www.google.com/glass/techspecs/). The GEE2 runs on the Android Oreo operating system (system image version of OPM1.210425.001) and has Wi-Fi, Bluetooth, inertial sensors, a multi-touch gesture touchpad, a 640 by 360 display, and an 8-megapixel camera. We used a tap gesture on the touchpad to take a picture with the CameraX API (https://developer.android.com/training/camerax). For the text recognition API, we used the ML Kit Text Recognition V2 API (https://developers.google.com/ml-kit/vision/text-rec-ognition/v2). When a region of interest (ROI) is identified in the taken picture, the image is analyzed by the ML Kit Text Recognition V2 API. The ML Kit supports text recognition in images or videos in various languages, including English, Korean, Chinese, and Japanese. The recognized text is out-put as a block of text. The recognized text is used to retrieve relevant data from a pre-registered database. For the data-base, we used Firebase real-time database (https://fire-base.google.com/docs/database). Using this database allows a cloud-hosted database to store JSON-based data.
V. CONCLUSION
In this paper, we proposed a design of a multi-sensor, third-party API, and cross-device integrated toolkit. The proposed integrated toolkit enhances applications for HCI researchers, self-tracking, and photo-based participatory research. We envision the proposed toolkit to support easy and efficient personal data acquisition and sharing for qualitative research methods such as ethnographic research, focus groups, record keeping, case study research, and interviews. We have yet to test our envisioned application with actual users and in actual scenarios. Research is still needed to examine the usability, satisfaction, and presentation layout [23] of the deployed input and output modalities on various smart devices. We plan to investigate systematic methods for compiling and analyzing personal multimodal data including physiological signals [15] collected from cross-device interaction.
 received his B.S. degree in Computer Science from Soongsil University in 2005. He received his M.S. and Ph.D. degrees in Information and Communication (Computer Science and Engineering) from the Gwangju Institute of Science and Technology (GIST), in 2007 and 2012, respectively. He was a researcher at the GIST Culture Technology Institute from 2012 to 2013 and was a research associate at the Korea Advanced Institute of Science and Technology, Culture Technology Research Institute in 2014. He was a senior researcher at Korea Electronics Technology Institute from 2014 to 2019. In September 2019, he joined the Division of Computer Engineering, Hanshin University where he is currently an assistant professor. His research interests include ubiquitous computing (context-awareness, wearable computing) and Human-Computer Interaction (mobile and wearable UI/UX, MR/AR/VR interaction).
received his B.S. degree in Computer Science from Soongsil University in 2005. He received his M.S. and Ph.D. degrees in Information and Communication (Computer Science and Engineering) from the Gwangju Institute of Science and Technology (GIST), in 2007 and 2012, respectively. He was a researcher at the GIST Culture Technology Institute from 2012 to 2013 and was a research associate at the Korea Advanced Institute of Science and Technology, Culture Technology Research Institute in 2014. He was a senior researcher at Korea Electronics Technology Institute from 2014 to 2019. In September 2019, he joined the Division of Computer Engineering, Hanshin University where he is currently an assistant professor. His research interests include ubiquitous computing (context-awareness, wearable computing) and Human-Computer Interaction (mobile and wearable UI/UX, MR/AR/VR interaction).