





I. INTRODUCTION
Hidden Markov Model or HMM is a stochastic modeling tool for sequential signals [1]. Real world signals are constantly being generated and streaming in for us to capture and make sense of. There are no explicit starting points and there are no explicit end points as well. For modeling convenience, however, we assume they start at a certain point in time and space. Similarly they are assumed to end their manifestations in due time completing one pattern. This is particularly true when we consider segmental patterns that occur in sequential context; one is followed by another as well as it is preceded by still another, which will be called the context for the target pattern. Then there is a problem of boundary detection for practical analysis of sequential patterns in context.
The study on improving the HMM has been around the two processes in the model, Markov chain and observation process. The majority of the study in the literature has been around the improving the observation. The most notable among the greatest inventions would be the continuous density modeling using Gaussian mixtures and semi-continuous HMM [2]. On the other hand ideas for improving the Markov chain have been relatively rare. There are a few variations of semi-Markov models in this category. They introduce additional parameters that explicitly model the state duration of the Markov chain [3].
This paper proposes adding a new set of HMM parameters augmenting the underlying Markov chain that control the end of Markov processes. They help the model terminate the random process at the right time. Experimental results in online Hangul handwriting recognition have shown highly intuitive letter boundaries as well as higher recognition performance, upward of 90%.
The rest of the paper consists as follows: Section 2 presents a formal definition of the model based on a modeling assumption. Section 3 provides the theory for model inference and then a set of formulae for estimating the model parameters using the expectation-maximization algorithm. Section 4 describes experimental results based on a network of HMMs for online handwriting recognition.
II. MODELING ASSUMPTION
Many real world signals are dynamic and change over time. But we often catch common patterns recurring often making them look familiar. Thus it is natural to view such a signal as a sequence of local noisy patterns out of finite set of patterns. Hence an input signal is modeled as a concatenation of random segmental patterns which themselves are highly variable. In real world signals the boundaries of the segments are not clear. But each pattern has distinctive characteristics, starts and ends giving some clues to the locations of boundaries. Each segmental sequence concludes its characteristic pattern at a certain point in time.
The classical HMM is defined by a parameter triple λ = (π, A, B) where π = (π1, π2, … , πN) is the initial state distribution describing how a process (here, a typical target pattern) starts probabilistically[2] while satisfying the constraints πi ≥ 0 and . A and B are state transition and state output distributions respectively.
This paper proposes a new probabilistic parameter et = P(|xt, y) for describing how a typical pattern y ends in state xt = i at time t followed by nothing. It also satisfies the stochastic constraints:
Alternative definition based on a different modeling assumption would be an exit from state i to an external sink. In this case the final transition in each is assigned a probability that satisfies . This extension is similar to the model with constraint in (1), but is more likely to lead to less discriminative model particularly when Viterbi algorithm that computes the most likely state sequence is used for classification.
Historically Markov chains have been studied a lot with a view to improving the accuracy of HMM modeling [3]. But this feature of ending behavior has never been studied. This paper sets the framework for the theory and presents an efficient inference and a training algorithms based on dynamic programming and expectation-maximization. In order to justify the proposed model augmentation, a set of experiments are conducted and analyses are made. The proposed model is also applied to Hangul characters in which two or three alphabets are written sequence.
III. MODEL INFERENCE
Given an observation sequence O = o1o2…oT, the likelihood of model λ is computed as follows:
where X = x1x2…xT is a Markov chain. Note that there is a probability factor exT at the end of the chain of transitions. The latter factor explicitly concludes the process inside the model.
Now let us consider a set of HMMs concatenated into a sequence where a model k is concatenated to a preceding model k-1 and a trailing model k+1. Refer to Fig. 1 where HMMs are connected via dummy nodes as shown in big circles. Dummy nodes take the role of a sink for the preceding HMM and the environment for the ensuing HMMs. Either way they do not belong to any model and do not generate any symbol. They are introduced just for computational convenience.
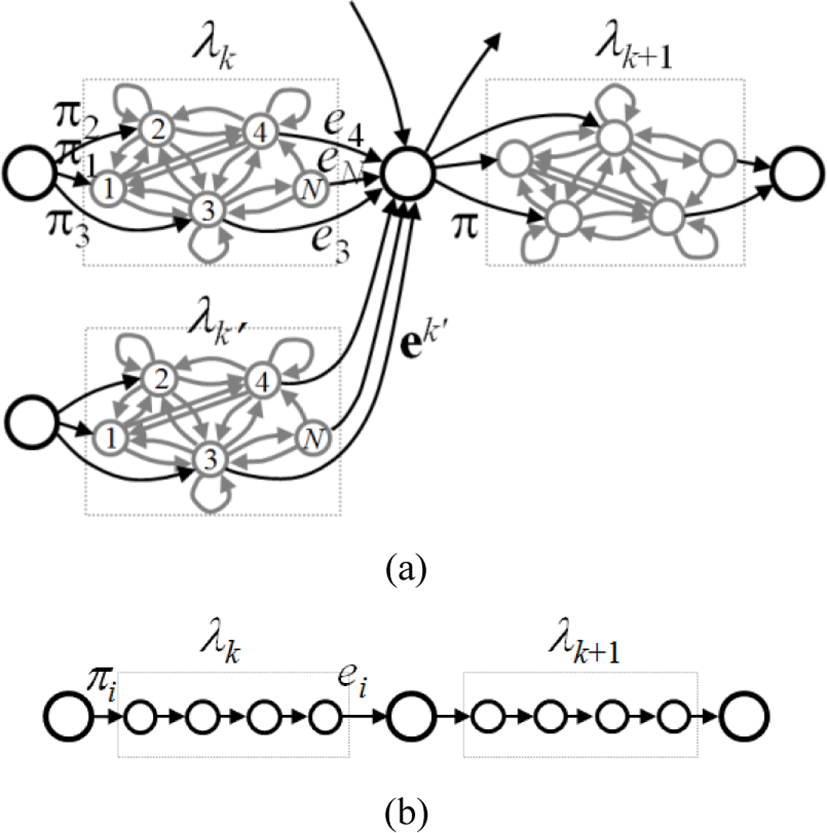
Then we can compute the forward and backward probabilities of Baum et al.’s [1] as follows:
where the first factors in the right hand side are the standard forward and backward probabilities: and . They are the well-known forward and backward variables introduced for efficient computation free of repeated calculation [2].
The EM algorithm for the model is based on the following posterior estimators with regard to the latent state variables:
where ‘$’ denotes the sink or the outside of the model. Following the logic of parameter transformation[2], we can easily derive the resulting formulae. Here only the formula for the new parameter will be explicitly presented:
where Tk is the time after which a Markov chain exits the model k.
[Theorem] The algorithm presented through Equations (3) ~ (7) is guaranteed to converge.
Proof. Following the reasoning of Baum et al. and using Jensen’s inequality, it is straightforward to show that P(O|λ(n+1))≥ P(O|λ(n) with equality when λ(n+1) = λ(n).
When multiple samples are used for training, the maximum likelihood estimate is simply given by the following relation:
IV. EXPERIMENTS AND DISCUSSION
On-line handwriting is often the right tool for data entry using a stylus on a digitizer tablet [4], [5]. The design of the proposed model for Hangul syllable handwriting has been borrowed from the earlier work [6]. But all the component HMMs have been redeveloped and all the inference algorithms have been modified to include the proposed augmentation.
The training set consists of 2886 samples for about 260 character classes. Each character consists of two or three alphabets: initial consonant(C), vowel (J), and with or without a final consonant (Z). Notationwise, a character is organized as either C-J or C-J-Z. But handwriting often involves ligatures that link between strokes. Explicit modeling of them with separate HMMs provides us a great advantage in designing a model for cursive scripts. There are over 100 HMMs including 20 ligature types each with different context. See Fig. 2(b). They were trained with whole character samples. Although the HMMs in the network were designed, they were first trained together in a network and learned the component boundaries simultaneously. With a small training set, this, however, didn’t turn out well [7]. So the model has been primed by prior samples, about 10% of the training set selected at random from the training set. See Fig. 2(c). Their letter boundaries were manually added.
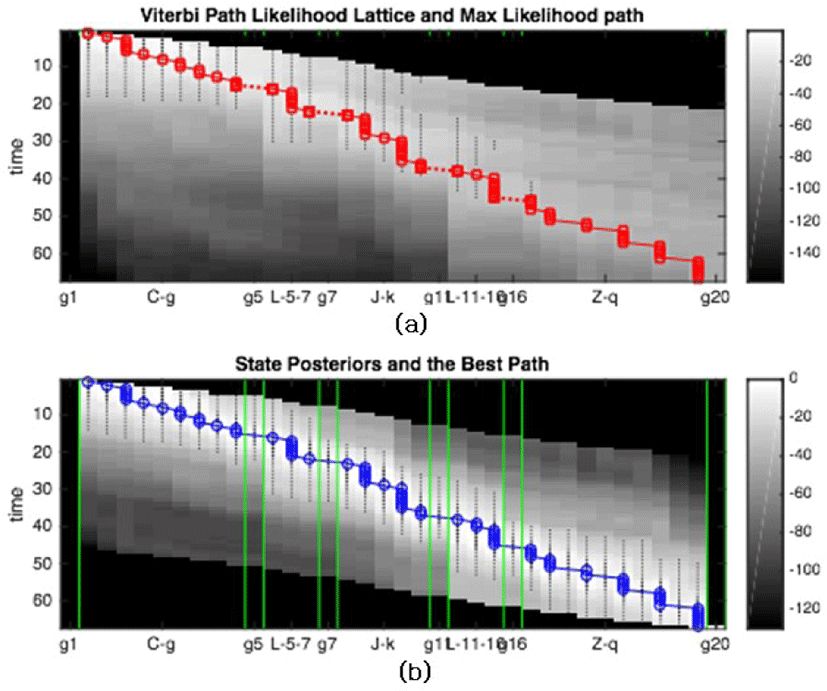
The first set of tests is about the behavior of dynamic programming-based inference algorithms. Fig. 3(a) shows the Viterbi pass probabilities for the character ‘합’(C-g, Ligature, J-k, another Ligature, and Z-q). The component models are aligned left-to-right (space), and the time sequence proceeds from top to bottom (time). The initial states are at the top-left corner and are brightest implying a high probability, where the intensity is rendered in the log scale. It also shows the most likely state sequence in knotted curves given an input handwriting. On the other hand Fig. 3(b) presents the ‘best’ posterior path for reference. It is based on the posterior probabilities γt (i) in Eq. (5) that takes both the left and right context into account. Note that the Viterbi path in Fig. 3(a), although computed using only the left (or past) context, is very close to and indistinguishable from the best one. This is often the case in practice, thus providing a justification for the use of Viterbi algorithm for path-based recognition.
Handwriting recognition performance has been measured over a set of 3,292 characters and recorded 90.2% with a single best hypothesis at twenty training iterations. When up to five best candidates are considered, the figure rose to 98.7%. Refer to Table 1. Considering a limited number and unbalanced distribution of samples, the performance is deemed promising. But it is a bit disappointing in that the character samples were based on simple math-related texts and the number of character classes is small. In the current experiments, only grapheme-level bigram language model was used. But we expect that the performance will make a big jump once we employ character-level statistics and dictionaries.
Fig. 4(a) shows a score of character samples tested on the recognizer developed above. The small circles mark the component boundaries proposed by the system. Some cursive samples (numbered 8, 9, 11, and 20) show two or more strokes connected into one making boundary detection trickier. However, all were correctly recognized except for the 31st sample.
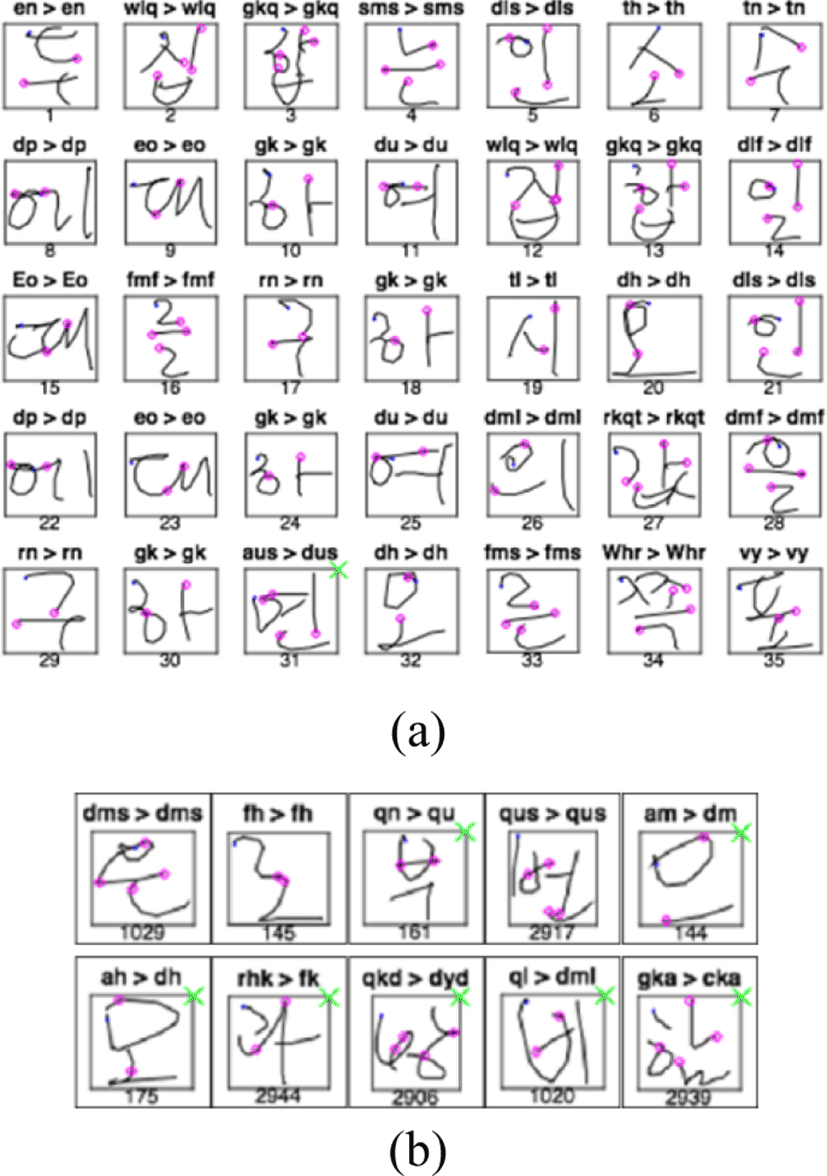
Fig. 4(b) show a selection of noteworthy samples returned by the recognizer based on the proposed HMMs. Upper row shows samples recognized correctly while the lower row represents failures on tough cases. Some are ambiguous while others imply simple mistakes possibly due to insufficient training. Nevertheless, the segmentation points look highly intuitive regardless of misrecognition.
V. CONCLUSION
This paper presents an idea of enhancing the HMM behaviors in networked HMMs for modeling concatenated sequence of patterns with ambiguous boundaries. The concept of sinks as distinct from states is not new. But it is formally modeled in a different way rendering the HMMs more discriminative. Just like the initial distribution, the explicit modeling of exiting arcs is conceptually viable. Experiment has confirmed that the proposed model (1) enables the detection of highly intuitive pattern boundaries and (2) leads to a significant error reduction of 13.22%.