





I. INTRODUCTION
With the increasing progress of computer technology, my country’s 3D animation technology industry has also ushered in the spring of development. Its application range is very wide, involving architectural planning, product design, advertising animation, film and television special effects, virtual world and many other fields. Among them, 3D animation technology has made rapid progress in film and television special effects. Although my country’s 3D animation technology is developing gradually, there is still a big gap compared with the same industry in other parts of the world. Therefore, we must correctly understand the restrictive factors in the development of 3D animation technology in the art of film and television special effects, and make full use of the existing production methods of film and television special effects. By combining 3D animation technology with film and television production, it will continue to promote the development of China’s film and television industry.
3D human body animation modeling is an important branch of 3D animation modeling, which can promote more realistic film and television animation works [1-2]. Nowadays, machine learning and computer vision are widely used in human animation and other fields, including image/video-based human motion data acquisition technology, digital character and scene modeling, interactive character animation control and motion generation, etc. Computer vision techniques are widely used. Besides, machine learning theory is also widely used in the field of intelligent 3D human animation research. Three-dimensional human body animation technology can be generally regarded as two categories: one is model animation developed on the basis of traditional computer animation technology, especially traditional two-dimensional computer animation technology. The second is the production technology of human body animation based on captured data with the popularization of motion capture system. The simple academic definition of motion capture is: Motion capture is a comprehensive use of computer graphics, electronics, machinery, optics, computer animation and other technologies to capture the movements or expressions of the subject of the performance. Through the captured data of these actions or expressions, the direct drive to the animation image model is realized. Motion capture is divided into different categories such as mechanical motion capture, acoustic motion capture, electromagnetic motion capture, and optical motion capture.
Traditional animation utilizes mathematical models to produce animation results that meet user needs. Such methods can be classified as model-based animation methods, including key frame animation technology, joint animation technology based on kinematics knowledge, and physics/dynamics methods. Another type of animation production technology uses real collected 3D motion data to generate animation models. Generate 3D human animation by adopting a data-driven approach. In essence, it is a data-driven animation production method, including editing, compositing, and reusing technologies based on motion capture data. The popularization of commercial human motion capture systems makes obtaining realistic 3D human motion data no longer a limitation for making realistic 3D human animation. 3D human motion databases that can be reused have also appeared, which makes the data-driven approach an important means of making realistic 3D human animation.
This paper focuses on the data-driven 3D human animation modeling research program. Specifically, it uses real 3D human motion data and uses machine learning methods to realize 3D human body modeling to meet the needs of 3D human body modeling in film and television animation. Human motion has strong randomness and continuity. In order to improve the accuracy of motion recognition, time series information is needed to describe the characteristics of the motion process. Long short-term memory network (LSTM) is a variant of recurrent neural network (RNN), which has been widely used in many fields. LSTM can realize the modeling of variable-length time series information, and has certain feature extraction capabilities [2]. Therefore, this paper proposes a 3D human animation modeling method based on LSTM cyclic neural network to realize automatic recognition of human motion. The real sensing data used in this paper is obtained through inertial sensors. In this paper, based on the WISDM dataset [3], a two-layer LSTM neural network is used to extract time series features. By modeling the three-axis acceleration time series information of the front pocket of the right leg of the human body, real-time recognition of six human action modes: walking, jogging, going upstairs and downstairs, sitting, and standing. This paper verifies its effectiveness through comparative experiments. The experimental results show that the method in this paper can provide a feasible solution for the research of human motion recognition and modeling based on motion capture data, and provide a new solution for film and television animation production.
II. RELATED WORK
Conde and Thalmann [4] used reinforcement learning theory to learn the virtual environment where the virtual character is located and analyze the hierarchical structure of the virtual scene. Noser et al. [5] and Kuffner and Latombe 0 established a multi-channel, high-level behavioral decision-making and driving model for virtual characters based on synthetic vision, memory and high-level reasoning and learning mechanisms, and realized autonomous roaming of virtual characters in obstacle scenes. Behavior animation generation. In the work of Ref [7] and Ref [8], machine learning techniques are used to provide a memory model for virtual characters, so that they can remember the information provided by the user and the instructions issued earlier. Ref [9] proposed a self-organizing structure for learning the virtual scene structure and the behavior of reaching a certain target point in the scene, etc., to realize autonomous animation generation. Ref [10] proposed the concept of virtual human imitation learning, that is, using machine learning theory to endow virtual characters with a certain autonomous learning ability, and enable them to simulate the physical behavior demonstrated by the user through training.
The essence of 3D human animation creation using motion capture technology is a data-driven animation creation method, which has the advantages of easy data acquisition, high precision, strong realism and high production efficiency. Motion synthesis is the focus and key technology of motion data reuse. It is also the most difficult part of the motion reuse process. Motion capture data has high dimensionality, large amount of information, complex structure, spatiotemporal continuity and Riemannian manifold structure, all of which bring challenges to motion synthesis. Motion hybrid [12-15] is a simple and efficient motion synthesis model. Such methods first preprocess motion segments of the same type, including using the DTW algorithm to align them in time sequence, and then make each motion frame have similar spatial coordinates through linear transformation, that is, coordinate alignment. The motions after time sequence alignment and coordinate alignment are unified in structure. By performing weighted interpolation on these unified motions, and then constrained reconstruction of the interpolated motion, a very realistic new motion can be obtained. However, the data organization method of such methods is too simple to mine the inherent laws in the data, and users cannot interact with the system in real time, making it difficult to control the results of motion synthesis to meet the needs of users. Another class of methods is parametric motion synthesis. Parametric motion models [16-18] can effectively solve the problems of motion graphs by exploiting some physical properties of motion. Kwon and Shin [18] introduced the type of motion, speed, acceleration and foothold into the synthetic model in the form of parameters, and controlled during the synthesis process, which can solve some problems such as foot sliding and orientation shaking. Heck and Gleicher [19] constructed the nodes of the motion graph as a continuous parameter space, which brought fine-grained control to the originally very limited splicing and combination methods. For example, this method can synthesize richer and more delicate output by adjusting parameters Boxing sport. These methods greatly improve the controllability of the motion synthesis process, but the semantic level of these physical parameters is too low, and the content needs to be manually specified in advance, which cannot automatically adapt to changes in motion types.
To address the above challenges, researchers apply deep learning methods to motion synthesis. Nowadays, the emergence of various deep learning models has greatly promoted the development of related fields. One of the important advantages of the deep learning model is that it can automatically learn the characteristics of the data from the data set, which provides a new research direction for data editing and processing. Gatys et al. [20] used the deep network model to extract the style features and content features of the image in the hidden layer respectively, and then through the editing process in the hidden layer, a new image that maintained the content of the original image but had a different style could finally be obtained. In the field of motion data reuse, Taylor and Hinton [21] constructed a model of a restricted Boltzmann machine, and performed motion mixing by extracting motion-related parameters to generate new motions. Holden et al. [22] proposed a motion synthesis method based on a deep learning framework. This method has relatively broad requirements on the format of the training data and does not require the above-mentioned various operations. Any type and length of motion capture data can be exploited to train the model. The motion manifold learned by the deep model framework can be expressed by a hidden unit of a autoencoder, which can synthesize various types of complex motions based on the parameters given by the user. In addition, problems such as footstep sliding and orientation shaking can be solved by constraining the hidden unit space.
III. SYSTEM DESIGN
The 3D dynamic image modeling of the human body based on the data-driven method can be regarded as the synthesis and modeling of human motion using the motion data reuse technology. In recent years, various machine learning techniques such as subspace analysis, statistical learning, and manifold learning have been widely used to analyze and learn the existing 3D human motion data and guide the generation of new motion data. This paper proposes the use of deep learning models to achieve 3D human motion modeling. The data is acquired through the motion capture device and preprocessed by the information processing module. Then, a two-layer LSTM neural network is used to extract time series features and model the motion of human legs. The specific process of the method proposed in this paper is as follows.
The optical motion capture system is the most commonly used. Its working principle is to wear photosensitive nodes on each limb of the athlete, so that the movement of the athlete can be restored by the three-dimensional information of these nodes captured by the cameras installed around the capture field. This type of system can capture human movements very accurately, and the device itself does not impose too much constraints on the movement of the athlete.
In addition, commercial industry motion capture and analysis systems can also be used to track, capture and calibrate the face and body movements of the collector in real time. The EvaRT motion capture software can save the change data of the marker points on the actor and read it directly by the software, and then transfer data such as actions and models in the 3D modeling software. This paper uses public datasets for experimental evaluation.
Due to the influence of capture conditions and errors, or to meet specific application requirements, the captured 3D human motion data may require specific preprocessing before being applied to 3D human animation creation. Motion data preprocessing includes reconstruction of missing feature points in data, natural/realistic 3D human motion data evaluation, motion data compression, key frame extraction, and motion sequence segmentation and recognition. Common dataset preprocessing operations include data smoothing and data windowing. The motion capture technology captures the movement of the performer, and through pre-processing and post-processing, the original data is converted into model motion data in a standard format, which is used for driving various 3D models.
Recurrent Neural Networks (RNNs) can process sequence data and can model and describe human motion processes. However, ordinary RNNs have long-term dependence problems, and are prone to gradient disappearance and gradient explosion during network training [23]. Therefore, this paper proposes to select LSTM which is a variant of RNN, to build a human action recognition model.
Like ordinary RNN, the input of the LSTM network at the current moment is still the output of the hidden state at the previous moment and the input feature at the current moment, and the network structure is also a chained neural network structure composed of a series of repeated neural network units. Different from the traditional RNN, LSTM introduces a “gate” mechanism and a memory unit described by the cell state inside each loop body neuron, which can control the memory and forgetting degree of the previous information and the current moment information, thus solving the traditional RNN. The long-term dependency problem is widely used. The internal structure of LSTM neurons is shown in Fig. 1.
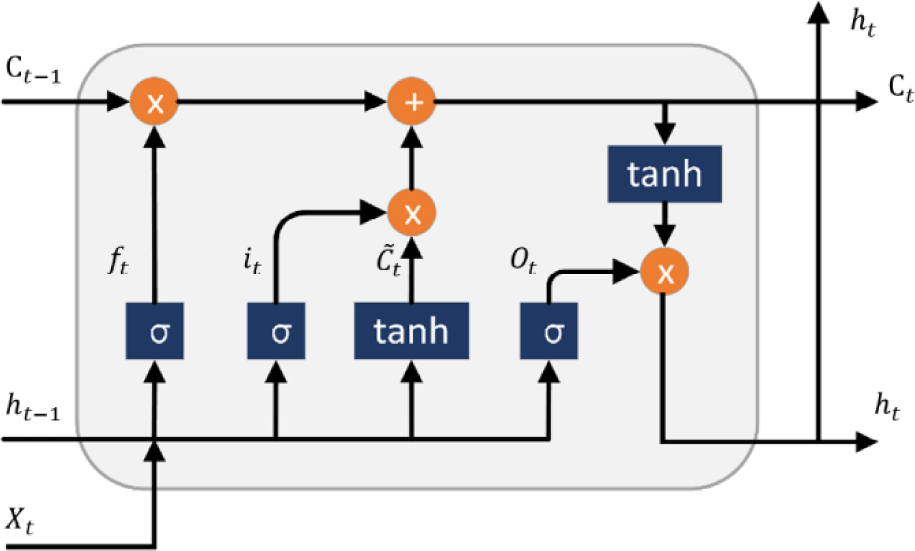
LSTM neurons are composed of cell states and “gate” mechanisms (forgetting gate, input gate, output gate). In the figure, Ct represents the cell state, representing long-term memory. By adding or deleting state information on Ct through the “gate” structure, the modified state information can be controlled to be transmitted to the next moment. σ represents the sigmoid activation function, which can output 0 to 1 the number between is mainly used to describe what information is passed after sigmoid, a value of 0 means that no information passes through sigmoid, and a value of 1 means that all information at this time passes through sigmoid. ht−1 and ht represent the hidden state of the previous moment and the current moment, respectively, ⊕ represents vector addition, and ⊗ represents vector multiplication.
Equations (1) to (6) describe how LSTM updates the state of the neural network unit according to the “gate” mechanism at any time step. The input is fed into each “gate” unit of the LSTM unit. The first step is to control which previously recorded information should be retained by the forget gate. It can be seen from Fig. 1 that the input of the forget gate at the current moment is the hidden state ht−1 at the previous moment and the input information xt at the current moment, as shown in equation (1). The second step is to update Ct by the input gate. First, pass xt into the sigmoid function and tanh function respectively to obtain the it vector and the new candidate value vector C~t. Afterwards, it is multiplied by the two-part vector of C~t and it to determine whether the input information of the network at the current moment is saved in Ct to update the cell value. The cell update formula is shown in equation (2)−(4). Finally, the final output value of the LSTM neuron at a time step is determined by the output gate. First, xt is calculated by the sigmoid function to obtain the vector Ot. Then multiply the Ct and Ct vectors processed by the tanh function to determine the final output information of the LSTM neuron at the current moment. The output gate formula is shown in equation (5) and equation (6).
In the formula: Wf, Wi, Wc, and Wo represent the weight matrix. bf, bi, bc, and bo represent the bias vector; [,] represent the splicing of two vectors.
In order to identify which kind of motion the person acts in real time, the structure of the LSTM network designed in this paper consists of an input layer and a hidden layer: including two LSTM layers, a fully connected layer and an output layer.
-
(1) Input layer: The input is the preprocessed data. The input dimension of RNN for the data is [number of samples, number of time steps, number of input features], namely: [54906, 90, 3].
-
(2) The first layer of LSTM layer: the time step is n=90, and the number of neurons in each time step of LSTM is 32. Since the input is the data of the accelerometer x, y, and z axes, the number of input features is 3. In addition, the hidden state output of each time step is used as the input of the next LSTM layer. The selection of the time step n and the number of neurons needs to be set experimentally, which will be explained later.
-
(3) Second LSTM layer: The number of neurons inside the LSTM unit at each time step is 32. Since the sample set and its corresponding category need to be used as input in the process of action pattern recognition, LSTM only needs to output at the last time step as the input of the fully connected layer.
-
(4) Fully connected layer: There are 32 neurons. The Relu function is adopted in our model as the activation function.
-
(5) Output layer: Since the network recognizes six human action patterns of standing, jogging, going upstairs, walking, and sitting, the softmax classifier is used as the output of the six action patterns, that is, the output layer will output the probability values of six categories. The calculation formula is shown in equation (7):
In the formula: i represents the action mode category, yt and yi represent the probability distribution of the human action category. Finally, according to the maximum likelihood estimation method, the attribute of the action mode is judged as the category with the highest probability.
Besides, a Dropout layer is added after the first LSTM layer, the second LSTM layer, and the fully connected layer. The Dropout layer will discard neurons with a certain probability at random when the model is trained each time. Since the neurons ignored each time are different, the trained networks are also different. Finally, the trained model is integrated to predict the average probability.
The collected data is input into the LSTM neural network as the motion pattern feature, and the six human motion pattern categories of standing, jogging, going upstairs, going downstairs, walking, and sitting are used as outputs. The training is realized by minimizing the loss function, and the loss function adopts the cross entropy. Loss function, the calculation formula is shown in equation (8).
In the formula: y~i represents the true value of the i-th category, and yi represents the predicted value of the ith category of the model. The Adam optimization algorithm [24] is used to adaptively optimize the learning rate, which has the advantages of efficient computation and less memory. The parameters of the model are initialized with random values of truncated normal distribution. In the process of backpropagation, different from the BP algorithm of other neural networks, the backpropagation along time (BPTT) algorithm is used to update the parameters. In order to prevent the model from overfitting, the method of early stopping is used in the iterative process. If the accuracy of the model on the test set does not improve by 0.001 within 10 iterations, the model stops training. After the model training is over, save the optimal parameters, and then use the saved optimal parameters to identify the human actions in the test set.
IV. EXPERIMENTAL EVALUATIONS
The experiment in this paper is based on the Windows 10 system, the CPU model is Intel Core i5-9300H, and the memory is 8 GB. The GPU is a notebook computer with NVIDIA GTX1650 graphics processor and 4 GB video memory. The algorithm is implemented using python language based on Google’s open-source deep learning framework Tensorflow2.0, and the experimental integrated development environment is Pycharm.
In this paper, we use public datasets to evaluate the experimental results. This dataset is the public dataset WISDM dataset of the Wireless Data Mining Laboratory of Fordham University. The WISDM dataset is a public dataset released by the Wireless Sensor Data Mining Laboratory (2012). This data set uses an Android smartphone as the data collection platform, and the smartphone is placed in the right front trouser pocket of the subject. The subjects completed 6 exercise modes including walking, jogging, going upstairs, going downstairs, sitting, and standing within a specific time. During this period, the built-in accelerometer of the mobile phone collects the data of the x, y, and z axes of the three-axis accelerometer at a sampling frequency of 20 Hz. The data set contains a total of 1,098,207 sample point data from 36 healthy subjects (the number of movements of each subject is not equal), and the distribution of the number of motion pattern samples is shown in Table 1. The continuous activity signal is segmented using a sliding window with a time length of 2.56s and an overlap rate of 50%. In this paper, 70% of the data is used as the training set and 30% of the data is used as the test set. For the convenience of processing, the data set is normalized. The processing flow is as follows:
| Sports mode | Ratio (%) |
|---|---|
| Walking | 38.6 |
| Jogging | 31.2 |
| Up Stairs | 11.2 |
| Down Stairs | 9.1 |
| Sitting | 5.5 |
| Standing | 4.4 |
In the formula: Xnormalize, Ynormalize, and Znormalize represent the normalized acceleration value. X, Y, and Z represent the raw data of the acceleration sensor; μx, μy, and μz represent the average values of the accelerometer’s x, y, and z axes, respectively; σx, σy, and σz represent the variance of the accelerometer’s x, y, and z axes, respectively.
In the evaluation, the model conducts 10 experiments on the test set, and takes the average result of 10 runs as the final value. The parameters of the LSTM network have a great influence on the recognition effect of the action pattern, so it is necessary to conduct experimental analysis on different parameters. In the experiment, the training model is aimed at 6 kinds of human action patterns, the weight and bias parameters are continuously updated, and the accuracy and loss values of the test data and training data after each iteration are recorded for comprehensive comparison and analysis. In addition, in the selection of model hyperparameters (such as the time step of LSTM neural network and the number of neurons), this paper determines the parameters through comparative experiments. This accuracy rate is selected as the indicator:
In the formula, True Positive (TP)and True Negative (TN) represent the number of samples that predict all positive samples as positive and negative samples, respectively. False Positive (FP) and False Negative (FN) represent the number of samples that predict all negative samples as positive and negative samples, respectively.
In this section, this paper evaluates the experimental results of our method on the WISDM dataset. Set the time step to 90 and the Dropout parameter to 0.2. The results of 6 different types of action patterns are shown in Table 2. The action mode Sitting has the highest accuracy rate, reaching 96.52%. The accuracy rate of Standing also exceeds 96%, slightly lower than Sitting, which is 96.36%. This is mainly because the movements of sitting and standing are the simplest, there is no change in movement, and the prediction model is easier to fit. Secondly, the accuracy rates of Jogging and Up Stairs reached 95.48% and 95.37%, respectively. Compared with the previous action modes, the accuracy rate of Down Stairs has dropped significantly, and its value is 93.11%, which is 3.41% lower than that of the Sitting category. The lowest experimental result is the Walking category, with an accuracy rate of 92.95%. For Walking, 3.14% and 3.36% of the data were identified as Up Stairs and Down Stairs. This is mainly because Walking has similarities in body swing and leg movements between walking and going up and down stairs, so there are relatively large misidentifications.
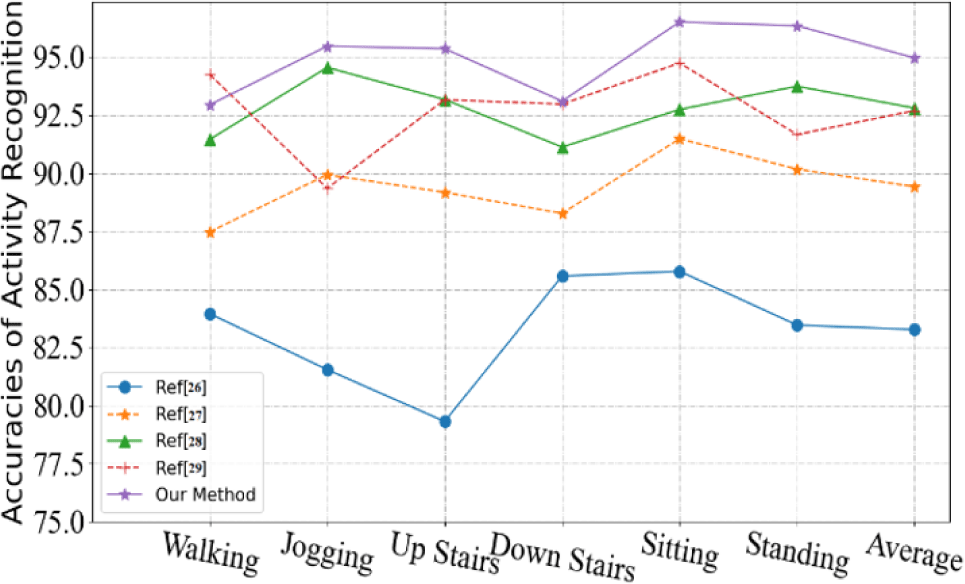
To further evaluate the effectiveness, the proposed method is compared with existing research. The four methods involved in the comparison (Methods in Ref [25], Ref [26], Ref [27], and Ref [28]) are all methods designed based on the deep learning architecture. The compared results can be seen in Fig. 2. The horizontal axis represents 6 different action pattern categories, and the last item is the average of all category results. The vertical axis is accuracy. The experimental performance of the method in Ref [25] is the worst among all 5 methods, and its average accuracy is 83.27%. The method in Ref [25] is even less than 80% accurate on the upstairs category dataset. Among all the five methods, the algorithm in this paper shows better performance, with an average accuracy rate of 94.97%. The average accuracy of Methods in Ref [27] and Ref [28] is very close, with a difference of only 0.1%. However, the experimental results of the two on different categories are quite different. The experimental results of Ref [27] are more stable in different categories with less fluctuation. The experimental results of Ref [28] in different categories fluctuate much more. The experimental results of this method in the two categories of Walking and Down Stairs are not lower than those of the method in this paper. Another very interesting observation is that several methods involved in the comparison all use more complex network structures. However, our method performs better in all datasets. The reason for this situation may be that the method in this paper is more applicable to the 6 simple action modes in the WISDM dataset. Models with more complex network structures are more prone to overfitting and performance degradation when dealing with these datasets.
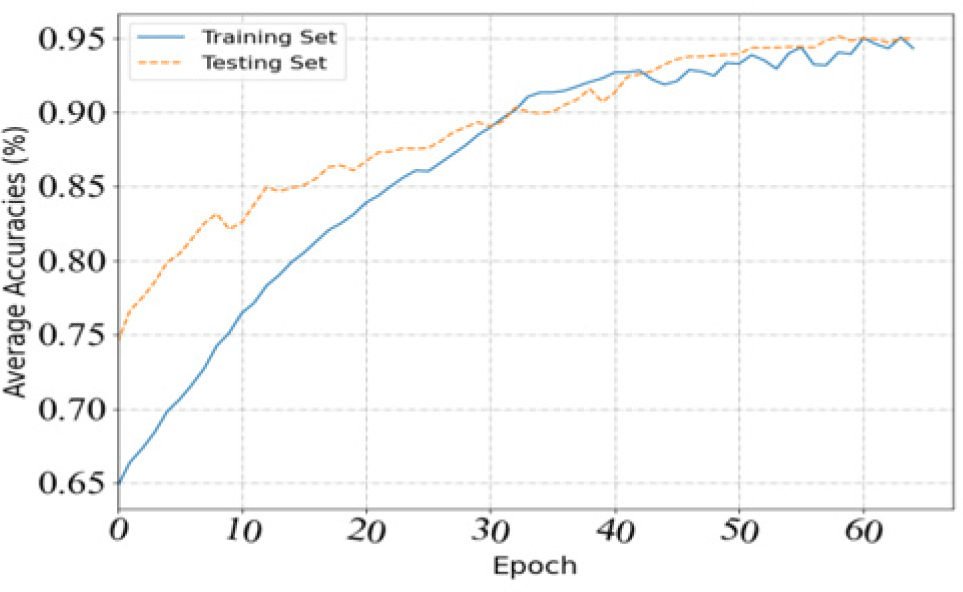
This section evaluates how the experimental results change as the number of iteration training increases. The accuracy curves of the training set and the test set during the training process are shown in Fig. 3. It can be seen from the figure that in the initial stage, the accuracy of the model on the training and testing data sets can reach 64.75% and 74.46%, respectively. This shows that our model has an advantage in handling action recognition. With the increase of the number of iterations, the recognition rate of the model gradually increases whether it is the training data set or the test data set. The experimental results on the training data set rise rapidly as the model iterates and cross with the experimental results on the test set. When the iteration reaches about 55 times, the experimental results on the test data set gradually converge and become stable. In this paper, the time step is set to 90, and the dropout parameter is 0.2. It can be seen that the model is better in terms of recognition rate stability and overfitting. This is because when the dropout parameter is 0.2, the dropout layer will randomly generate the network structure, which can effectively prevent overfitting. Therefore, the hyperparameter time step used by the final LSTM neural network is 90, and the dropout layer parameter is set to 0.2.
V. CONCLUSION
In the field of film and television animation, the use of motion capture technology to model three-dimensional dynamic images of the human body can meet the requirements of a certain degree of professionalism faster and more conveniently than traditional hand K animation. At the same time, it can shorten the production cycle and improve the efficiency of 3D animation modeling. Considering the strong randomness and continuity of human motion, time series information is needed to describe the characteristics of the motion process to increase the accuracy of action recognition. In this paper, a human motion recognition method based on LSTM neural network is designed using open dataset WISDM as raw data. A two-layer LSTM network is constructed to model and describe human temporal motions. The experimental results show that the average recognition accuracy is 94.97%. To measure the performance of this method, this method is compared with four methods based on in-depth learning model. The experimental results verify the validity of this method. In the future, the research group will study the human multi-node motion information, and further explore the human motion capture method based on inertial information.
