





I. INTRODUCTION
3D facial models have been widely used in various facial applications, such as facial animation, facial synthesis, facial reconstruction, facial recognition, and facial tracking. To use 3D facial models, facial alignment, which is the process of moving and deforming a facial model to an image, is an essential pre-processing step. Since the human face has a regularized structure of facial components such as eyes, lips, and nose, facial alignment is performed efficiently using this as prior. However, in traditional facial alignment methods, there is alignment instability in large pose and expression changes. In the cases of large changes in pose and expression, it is unclear whether the change in facial shape is caused by identity, expression, or pose. If this ambiguity is expanded to the temporal domain, unnatural facial shape changes and jittering artifacts arise, and significant quality degradation occurs visually. To address this, in this paper, we propose a stabilized facial alignment framework in identity, expression, and temporal changes.
The 3D Morphable Model (3DMM), a statistical model of 3D faces, is the most widely used representative model to obtain the 3D face from a facial image in various face-related applications. Since the first 3DMM was introduced [1], variants of 3DMM have been built by decomposing facial scans of various identities and expressions using Principal Component Analysis (PCA) to represent an arbitrary human face. It can efficiently represent a 3D face from a target facial image. However, when fitting the 3DMM into a large expression or pose facial image, there is ambiguity in the facial shape whether facial shape deformation is caused by identity or expression. It does not cause large visual degradation in a static domain; however, it occurs in large visual degradation, such as unnatural facial shape changes and jittering artifacts in a temporal domain.
Recently, with the expansion of the Generative Adversarial Network (GAN) in deep learning, it has been found that using discriminators leads to a network with higher performance [2]. GAN is composed of two networks: a generator and a discriminator. The discriminator is trained to determine whether the input data distribution is close to the ground-truth data distribution or the generated data distribution. At the same time, the generator is trained to fool the discriminator, by generating more accurate data. Motivated by this, we propose a stable and accurate facial alignment framework by introducing stability discriminators that determine that the regressed camera and facial shape parameters are stable. The proposed facial alignment framework consists of a facial alignment network and stability discriminators. The facial alignment network is trained to regress camera, face identity, and expression parameters from an image. The stability discriminator is trained to discriminate whether the facial deformation generated from the estimated facial identity and expression parameters is stable and whether the deformation between neighbor frames is stable. Using these stability discriminators, the proposed facial alignment network shows accurate and stable facial alignment performance in both the static and temporal domains. The 300 Videos in the Wild (300VW) dataset [3], which provides large-scale facial tracking data, is used for qualitative and quantitative evaluations. In the experimental results, the proposed method shows significant improvements over state-of-the-art methods for temporal facial alignment. The results demonstrate that the proposed method enables accurate facial tracking with multiple discriminators by stabilizing facial locations and shapes over time.
II. RELATED WORKS
From the first 3DMM introduced by Blanz [1], various 3DMMs have been proposed [4-6]. From facial scans collected from multiple subjects, the features of 3D facial scans for identity, expression, and texture have been encoded using PCA decomposition. Since each facial scan has a different topology, mesh registration is required to find vertex correspondences. In [1], optical was used to find the correspondence between the vertex between facial scans. In [4], for an accurate alignment, non-rigid registration method, warping based on Thin-Plate Splines (TPS) [7] and non-rigid Iterative Closest Point (ICP) [8] was used. In [5], a multilinear facial model was proposed to represent facial identity and expression using the Singular Value Decomposition (SVD). In [6], based on the multilinear model, a bilinear facial model of identity and expression was constructed by deforming the facial scan into the template model with expression. Due to the many efforts to build an accurate 3DMM, an arbitrary 3D face can be accurately and effectively represented using 3DMM.
3D facial alignment aims to fit a 3DMM to a facial image. The first 3D facial alignment method [9] is performed by fitting the 3DMM, minimizing the pixel-wise difference between the target facial image and a rendered image of the 3DMM. In recent years, regression-based 3D facial alignment has been introduced that minimizes the difference between the target 2D landmark and the projected 2D landmark of 3DMM [10-13]. These methods have shown performance improvement; however, there remain two major challenges. First, self-occlusion arises due to a large pose or expression. Due to self-occlusion, facial semantic information is lost, and unreliable facial alignment may occur. Second, in the temporal sequences, temporal instability arises due to a large and fast motion. The results of facial alignment may look reliable in the static shot, but in the temporal sequence, jittering artifacts on facial alignment usually occur. To address these problems, in this paper, we propose novel stabilization discriminators that guide changes in the stabilized facial shape in large poses, expressions, and motion.
III. METHOD
The proposed method utilizes a facial alignment network with 3DMM to produce accurate 3D facial alignment. Multiple discriminators are employed to ensure consistent facial alignments with an individual’s identity and expression over time. Fig. 1 illustrates the overall framework of the proposed method for facial alignment.
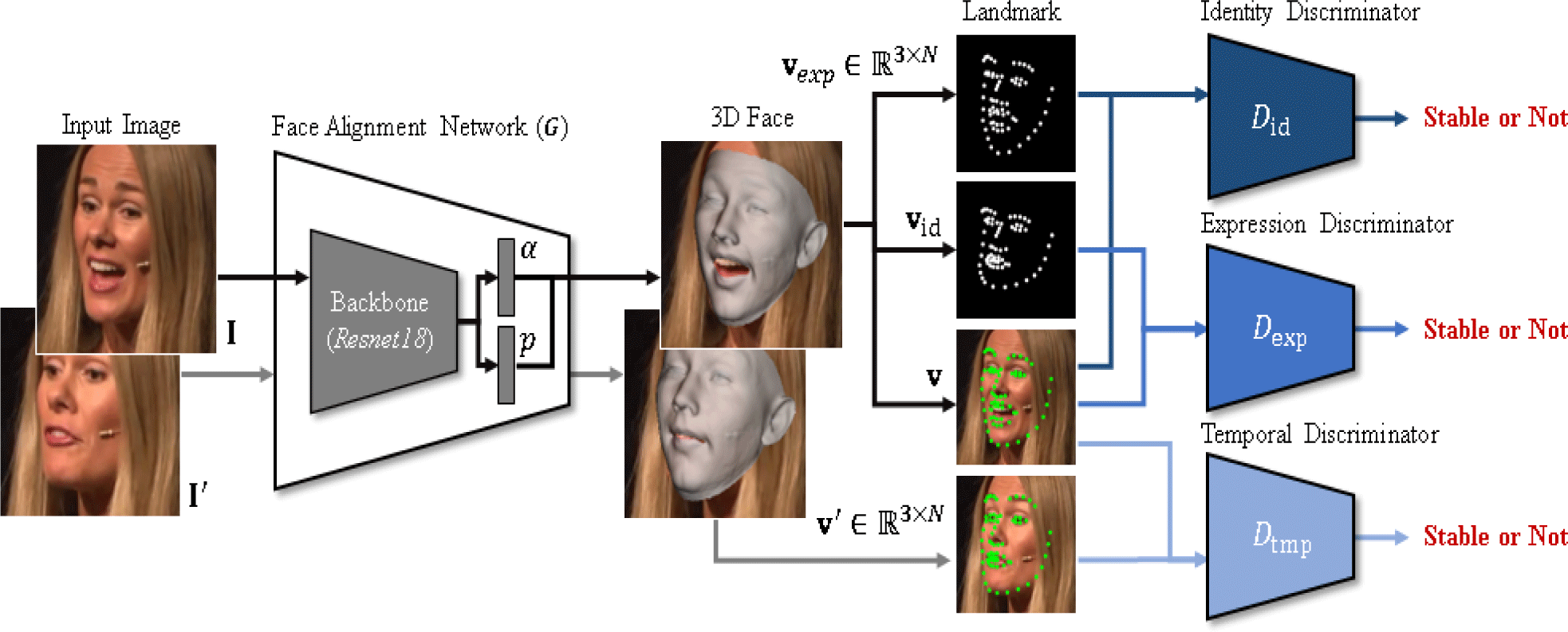
A 3DMM represents an arbitrary 3D face using bases decomposed through PCA. Using the 3DMM, the 3D face (S) can be represented by parameters for both identity and expression, as follows:
where F∈R3×N is the 3D face with N vertices, F is the mean face, A represents the 3D shape bases, and α is the shape parameter corresponding to A. The facial shape bases, denoted by A, are decomposed into two parts: A=[Aid, Aexp]. Here, Aid is trained using 3D facial meshes with a neutral expression, while Aexp is computed as the difference between the facial mesh with expression and the neutral facial mesh. The facial shape parameter α=[αid, αexp] is divided into two components: αid and αexp, which correspond to the facial identity and expression bases, respectively. In this paper, Aid and Aexp are from the Basel Face Model [4] (αid ∈ ℝ199) and FaceWareHouse [6] (αexp ∈ ℝ300), respectively. By applying a rotation matrix R ∈ ℝ3×3, a 2D translation vector t ∈ ℝ3, a focal length scalar f, and a projection matrix P, the 3D face is projected onto image coordinates v as follows:
where * is the matrix multiplication operator.
We adopt ResNet-50 as the facial alignment network G to estimate the camera and shape parameters. We divided the 2048 output features from the final pooling layer into two sections: 128 features for camera parameters and 1920 features for facial shape parameters. Two fully connected layers, each with 512 hidden nodes, are added to each component to estimate the camera parameters, [R, t, f], and the shape parameters, [αid, αexp].
Given a 2D image I, the facial alignment network G encodes the camera parameters p=[f, R, t] and shape parameter α. Then, the projected landmark of the 3D face is estimated using a landmark index vector l ∈ ℝ68. The proposed facial alignment network is trained using the Lland loss for landmark s and regularization loss for shape and expression parameters. The landmark loss, denoted as Lland, is defined as follows:
where U is the labeled ground-truth 2D landmark locations of the input image. To prevent the generation of undesired facial shapes and expressions, L2 regularization terms are applied to the shape and expression parameters. Specifically, the shape regularization term is denoted Lid = |αid|2, while the expression regularization term is denoted as Lexp = |αexp|2. The loss of facial alignment is defined by combining these losses in the following manner:
where λid and λexp are the balancing factors between losses and we set to λid = λexp = 0.0001 in our experiments. Sufficiently small values of the balancing factors help avoid parameter overfitting without sacrificing alignment accuracy.
To train the facial alignment network to stabilize in both the temporal and static domains, we propose three different discriminators: identity, expression, and temporal cues. The identity and expression discriminator stabilizes the facial alignment network in a static domain by distinguishing between the estimated changes in facial shape based on the identity and expression parameters. The temporal discriminator stabilizes facial alignment over time by distinguishing changes in facial shape over time.
The identity discriminator determines whether the estimated changes in facial shape correspond to the desired facial shape based on the regressed facial identity parameter. The identity discriminator is trained by calculating the difference between facial landmarks and estimated landmarks without considering identity. To calculate the difference in facial landmarks, the facial shape without identity needs to be estimated as follows:
The facial landmarks can be detected from the projected facial vertices. However, since the landmark is located in the image coordinates, we normalize both the ground truth and the estimated landmark to the range of [0, 1] before calculating the difference. The difference to be used as input for the identity discriminator is computed by using the normalized landmarks as follows:
where xid is the difference calculated from the ground-truth landmark and xz,id is the difference calculated from the estimated landmark. To train the identity discriminator, xid is used as the real distribution and xz,id is used as fake distribution. The loss of identity discrimination is defined as follows:
Similar to the identity discriminator, the expression discriminator is trained to determine the change in facial shape based on the validity of the expression parameter. The facial shape without expression, denoted as Sid, is calculated by replacing Aexp and αexp with Aid and αid in (5), and the projected facial shape, denoted as vid, is then calculated using equation (2). Then, the difference between the facial landmarks with and without expression is computed by replacing vexp with vid in equation (7) and (8). To train the expression discriminator, we use the differences between the calculated landmarks without expression and the ground truth landmarks (xexp) as real distribution. Likewise, the differences between the estimated landmarks with expression and the ground truth landmarks (xz,exp) is used as fake distributions. Therefore, the expression discriminator loss is defined as follows:
The identity and expression discriminators stabilize the facial alignment network in a static domain. For improved temporal stabilization performance, we propose a temporal discriminator that can accurately judge the validity of any temporal changes in facial shape. The variation in facial landmarks between the current and previous frames is utilized as input for the temporal discriminator. Facial temporal changes are determined by calculating the difference between the current and previous frames as follows:
where v′ and U′ are the projected vertices and the ground-truth landmark of the previous frame, respectively. The temporal discriminator loss is defined as follows:
These multiple discriminators are trained to distinguish whether identity, expression, and temporal changes are valid. The facial alignment network, on the other hand, is trained to fool these discriminators. The total adversarial loss for these discriminators, namely Did, Dexp, and Dtmp, is defined as follows:
where λid, λexp, and λtmp are the balancing factors. The total loss for the facial alignment network (G) is defined by combining the alignment and adversarial losses as follows:
In our experiments, we set balancing factors to λid = λexp = λtmp = 0.1 for discriminators and facial alignment network. The same network structure is used for all discriminators. From the landmark difference, the two fully connected layers with 256 hidden nodes are used to deter mine the stability, a single scalar value ranging from 0 to 1.
IV. EXPERIMENTS
The 300VW dataset [3], which provides large-scale facial tracking data, is used for both qualitative and quantitative evaluations. The 300VW dataset comprises 114 videos, totaling 218,595 frames, each with 68-point landmark labels. Out of 114 videos, 50 are allocated for training purposes, while the remaining 64 are designated for testing. The test videos are divided into three categories (A, B, and C), with C being the most challenging test set. For training purposes, each frame is cropped using a ground-truth landmark and resized to 256×256 pixels to be used as input for the facial alignment network. To enhance the network’s resilience to temporal changes, the frame interval between the current and previous frames is randomly increased within the range of 1 to 6. After a roughly aligned network is formed, each frame is cropped using a landmark estimated from the previous frame. In the testing phase, the first frame is cropped based on the landmarks detected using a conventional landmark detection algorithm called MTCNN [14]. From the second frame onward, each subsequent frame is cropped using a landmark estimated from the previous frame. The proposed method used in all experiments was trained for 500 epochs using Tensorflow (version 2.10.0), (CUDNN version 8.1), and CUDA (version 11.2). We used the Adam optimizer for optimization and trained the model on a single NVIDIA 2080Ti (11GB) with a batch size of 20.
We used a learning rate of 0.001 during the initial training phase, which gradually decreased to 0.00001.
For evaluation, we compare our method with other state-of-the-art facial alignment methods: 3DDFA [15] and RingNet [16], DSFNet [17]. For quantitative comparison, we measure the Normalized Mean Error (NME) of the 2D facial landmarks. NME is calculated as the average normalized landmark error divided by the facial bounding size based on previous facial alignment methods [18-19]. The size of the facial bounding box is defined as the square root of the product of the width and height of the rectangular hull calculated from all the landmarks. The quantitative measurements are summarized in Table 1. Also, Fig. 2 visualizes some examples of the 3D facial alignment results. In the experimental results, the proposed method outperforms other methods in every case. Especially, our method has a distinct advantage in the tracking challenging case (300VW-C) compared to other methods.
| Type | 300VW-A | 300VW-B | 300VW-C |
|---|---|---|---|
| 3DDFA | 2.913 | 3.035 | 3.387 |
| RingNet | 2.845 | 2.983 | 3.343 |
| DSFNet | 2.799 | 2.878 | 3.214 |
| Ours | 2.495 | 2.549 | 2.734 |

We performed four ablation tests on the discriminator to verify the primary contributions of the proposed multiple discriminators. For the baseline, we trained the facial alignment network without using any discriminator. On the baseline, each discriminator is used to evaluate its own performance. The ablation tests are conducted by measuring the accuracy of facial alignment, which is represented by the Normalized Mean Error (NME). The results of these tests are presented in Table 2.
The results show that discriminations on an individual’s identity, expression, and temporal changes give distinct performance gains. In particular, temporal discrimination is shown to play the most important role in accomplishing stable alignments in time, while identity discrimination plays the least. By comparing the result in Table 2, it is demonstrated that using multiple discriminations on temporal identity and expression simultaneously gives strong benefits to obtaining stable 3D faces.
V. CONCLUSION
In this paper, we propose a stable and accurate facial alignment framework by introducing multiple stability discriminators. The proposed discriminators determine the regressed camera, face identity, and expression parameters simultaneously from an image. The proposed framework consists of a facial alignment network and multiple discriminators: identity, expression, and temporal discriminators. To verify the performance of the proposed discriminators, the large-scale facial tracking dataset, 300VW dataset, is used for qualitative and quantitative evaluations. The experimental results show significant performance improvements over state-of-the-art methods, demonstrating the strong benefits of our method in accurate facial alignment over time. We believe that our work would be helpful in various facial applications, such as facial recognition [20-21].



