





I. INTRODUCTION
Multi-view representation is the most intuitive and the closest to human perception for understanding 3-dimensional (3D) objects. Since the appearance of a 3D object may change considerably depending on viewpoints, a single view of an object often cannot give sufficient information for classifying the object. When the initial view of an object is very similar to different objects, humans will check other views until an informative view is found. Multi-view-based object detection methods should consider the different contributions from informative and uninformative views, especially when most of the views of an object are highly similar to the other object and only a few views are informative. Therefore, the challenge of multi-view representation is how to make a correct decision by utilizing the informative view when the similarity between different objects leads to serious confusion.
Classical decision-making strategies [1] are commonly used for aggregating detection results from multiple views. However, the contributions of informative and uninformative views have yet to be well-considered in aggregation. This study proposes a novel decision-making model with graph convolutional networks (DM-GCN) that aggregates outputs predicted from multiple viewpoints while considering the contribution of each view. In the proposed method, the output from a more informative view has more influence on the decision than that from a less informative view. Outputs are represented in the non-Euclidean space and aggregated with graph convolutional networks (GCN) [2]. Each predicted output is defined as a node in the input graph, and a relationship is built among the nodes based on the class labels and views. By leveraging the relationship, DM-GCN enhances the contributions of informative views when making a decision. Since the input graph only contains predicted class labels and confidence scores, DM-GCN can be applied to any object detector [3-5].
To investigate the performance of DM-GCN, a real captured multi-view single object detection dataset named Yogurt10 is proposed. Yogurt10 consists of 10 ‘Yogurt’ products with high similarity in shape, size, color, and texture. In addition, a new evaluation metric is proposed to evaluate the performance fairly. Experimental results show that DM-GCN outperforms classical decision-making strategies. It is light and has an insignificant computational cost. The inference latency of a 3-layer DM-GCN is only 0.2 ms on GPU and can be negligible compared to object detectors’ latency. Moreover, a visual explanation method is provided to inter-pret how DM-GCN gives correct multi-view single object detection results.
The rest of this paper is organized as follows. Section 2 briefly reviews classical decision-making strategies and the background of graph convolutional networks. The proposed DM-GCN model is presented in Section 3. Section 4 shows the experimental results of the proposed work. Section 5 concludes this paper.
II. RELATED WORK
Decision-making strategies can be categorized into voting-based rules and score fusion methods. Voting-based rules only consider class labels predicted by the models. The majority voting chooses the class with the highest number of votes. Borda count sorts the classes of each model and assigns different votes to them according to their ranks. The summation of votes across all the models is obtained, and the class with the most votes becomes the final decision. Behavior-Knowledge Space [6] constructs a look-up table to record the frequency of each label combination produced by the models based on the training data. The class with the highest frequency is selected according to the look-up table during the test. Score fusion methods consider both predicted class labels and scores. Algebraic combiners perform the mean, max, or product operations. These methods are simple, non-trainable, and widely adopted in the palmprint recognition task [7-8]. Decision Templates (DT) [9] average the decision profiles of each class based on the training data. The final decision is the class with the highest similarity between decision templates and the decision profile constructed from a test instance. However, these decision-making strategies do not exploit the relationship among multiple views.
Kipf and Welling [2] introduce graph convolutional networks for graph-based semi-supervised classification. The proposed layer-wise propagation rule is motivated by a localized first-order approximation of spectral graph convolutions. Some further works based on GCN are proposed for many computer vision tasks. Wang and Gupta [10] define the object region proposals from different frames as graph nodes for video action recognition. Yan et al. [11] propose a spatial-temporal GCN to learn spatial and temporal patterns from data for skeleton-based action recognition. Yang et al. [12] construct a scene graph to capture contextual information between objects and their relations via an attentional GCN.
III. PROPOSED METHOD
A graph is represented as G = (V, E), where V is the set of nodes, and E is the set of edges. vi denotes a node and eij denotes an edge between node vi and vj. The adjacency matrix A is a n × n matrix, where n is the number of nodes. Aij = 1 if eij ∈ E and otherwise Aij = 0. xv ∈ ℝn is the feature vector of the node v, where d is the dimension of xv. X ∈ ℝn × d represents a node feature matrix.
This study constructs an undirected graph for multi-view single object detection. Each predicted output from an object detector is defined as a node v. The nodes with input scores lower than a threshold St are discarded to reduce the computational complexity. eij is given if node vi and vj are generated from the same view or have the same class label. Otherwise, nodes vi and vj are disconnected. Therefore, the adjacency matrix is built as follows:
Here, ci denotes the input class label of the node vi, and pk denotes the kth view. xv contains a confidence score and a class label. A confidence score is normalized between 0 and 1, and the class label is represented in a one-hot manner. Hence, d = 1 + C, where C is the number of categories.
This study designs three models with different depths as shown in Fig. 1. Following the work of Kipf and Welling [2], the graph convolutional layer is defined as:
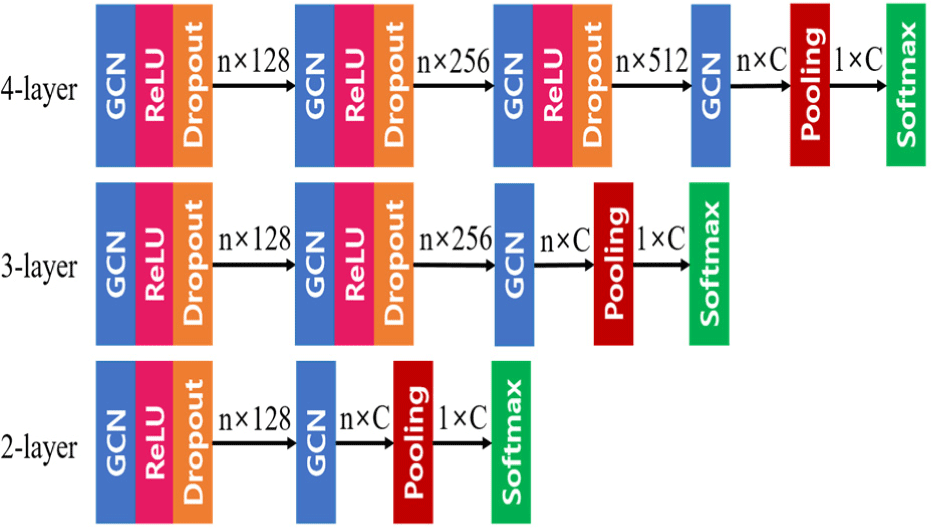
Here, Ã = A + IN is the adjacency matrix with added self-connections, where IN is the identity matrix. . Hl is the matrix of the activations at the lth layer and H0 = X. Wl is a layer-specific trainable weight matrix. σ is an elementwise nonlinear activation function. Let GCN denote a graph convolutional layer without an activation function. σ = ReLU. Dropout [13] with a probability of 0.5 is added after the activation operation to prevent networks from overfitting. Pooling denotes the mean pooling layer and performs a readout operation that generates a graph-level representation based on node-level representations, which can be expressed as:
Here, Hm is the feature matrix after the mean pooling operation. z is the index of the last graph convolutional layer. The standard cross entropy loss provided by the PyTorch library is adopted as the objective function for the optimization.
A visual explanation method is provided to interpret DM-GCN based on Grad-CAM [14]. To obtain the heat map on the input graph, a class-specific weight αc for the fth feature at layer l is first obtained by
where yc is the score for class c after the softmax layer. Thereafter, the class-specific heat map Gc is obtained by
where i is the index of the node v. The contribution of the node vi to the decision of class c is obtained by
where Si is the input confidence score of the node vi.
IV. EXPERIMENTS
Yogurt10 is a real captured dataset proposed for the multi-view single object detection task. As shown in Fig. 2, Yogurt10 comprises two groups of remarkably similar-looking products. Each group contains five products with different flavors of the same brand, which are slightly different in color, text, and patterns. This work collects 500 informative and 3,000 uninformative single-view images with a resolution of 640×480 by multiple randomly placed cameras in a white environment. Two experts annotate the bounding boxes and perform three rounds of double-checking. Subsequently, 1,000 sets of multi-view images are generated. Each set of multi-view images contains three random views of an object, including at least one informative view, to ensure a human-level accuracy of 100%. Each class has the same number of samples: 50 single-view images for fine-tuning the network and 40/60 train/test sets for validating multi-view single object detection methods.

A new evaluation metric is proposed by combining the average precision (AP) and the localization intersection over union (IoU) metric. Specifically, a correct multi-view detection should satisfy two criteria: a correct class label and the average IoU (mIoU) over multiple views is higher than a threshold θ, where θ ∈ [0.50, 0.95] with a uniform step size of 0.05. Here, only the bounding box with the maximum confidence score in each view is considered during localization performance evaluation. In this experiment, mvAP50, mvAP75, and mvAP are used as the evaluation metrics, where mvAP is obtained by averaging over all ten mIoU thresholds.
The experiments are performed on one NVIDIA Titan Xp GPU and Intel(R) Xeon(R) Gold 5118 CPU @2.30 GHz. All the models are implemented in PyTorch and trained with CUDA 9.0 and cuDNN 7 as computational back-ends. YOLOv3 [10] is used as the object detector to extract predicted outputs. The post-processing step non-maximum suppression is removed to avoid the loss of detection candidates. The predicted outputs are constructed as the input graphs and adjacency matrices for DM-GCN. DM-GCN is trained for 200 epochs with a warm-up epoch of 4 and a batch size of 1. The initial learning rate is set to 0.001 and gradually decreased to 0 through the cosine annealing strategy. The SGD optimizer is used with a momentum of 0.9 and a weight decay of 0.0005. The input score threshold St is set to 0.1, which approximately ensures a recall of 100.
Table 1 shows the results of four classical decision-making strategies and proposed 3-layer DM-GCN on the Yogurt10 dataset. DM-GCN achieves the best performance and has a significant improvement over the baselines. The accuracy gains are 1.9%, 1.8%, and 1.3% compared with the max rule on mvAP50, mvAP75, and mvAP, respectively. The improvement indicates that DM-GCN gives more weight to outputs from the informative views. For computational efficiency, the model size is independent of the number of views and has only 0.05 million trainable parameters. With an input image size of 640, the inference latency of 3-view YOLOv3 is approximately 104 ms. As a result-level aggregation model, DM-GCN only increases 0.2 ms latency and thus remains the real-time performance of the detector.
| Method | mvAP50 | mvAP75 | mvAP |
|---|---|---|---|
| Majority voting | 90.7 | 88.5 | 68.3 |
| Mean rule | 92.8 | 90.7 | 69.8 |
| Max rule | 94.8 | 92.7 | 71.3 |
| DT | 94.0 | 91.8 | 70.7 |
| DM-GCN | 96.7 | 94.5 | 72.6 |
Compared to the mean pooling layer in DM-GCN, using the max pooling layer degrades the performance and only has 95.8% mvAP50. The accuracy drop indicates that DM-GCN prefers to make a correct decision based on the global information of all the nodes rather than the local information of a single node.
The 2-layer DM-GCN has 96.0% mvAP50, 0.8% lower than the performance of the 3-layer one. As a deeper model, the 4-layer one only has a 0.1% accuracy improvement than the 3-layer one, indicating that a deeper model may result in an overfitting problem owing to more propagation among nodes.
The input score threshold St ∈ [0.1, 0.9] with a uniform step size of 0.1 is applied during the test. To fairly check the performance of DM-GCN, the trained weight obtained at St = 0.1 is used. As shown in Fig. 3, DM-GCN outperforms the other four strategies under different thresholds. With the increase of St, the number of miss detections increases, and mIoU decreases, causing a drop in accuracy. Note that when keeping the same training data, the performance of trainable combination rule DT severely declines with the increase of St while DM-GCN is much more robust.
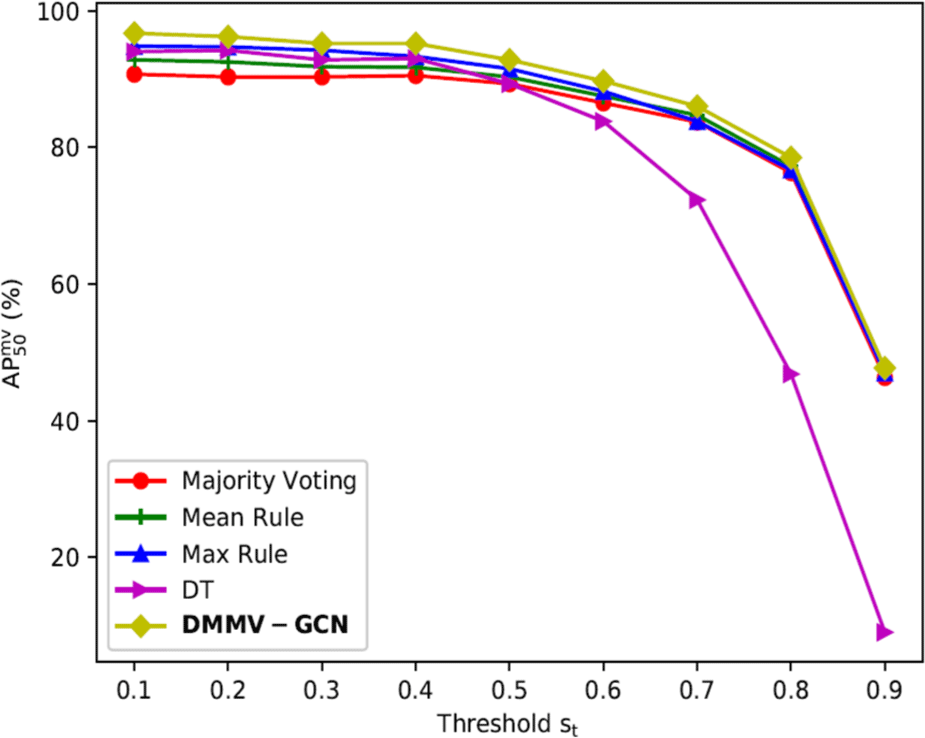
Fig. 4 shows an example set of 3-view images for the ‘BStrawberry’ object. As shown in Fig. 2, ‘BPeach’ is highly similar to ‘BStrawberry’. In this example, View 1 is informative, while Views 2 and 3 are uninformative. Yellow and orange nodes in the input graph represent ‘BPeach’ and ‘BStrawberry’, respectively. The node size in the input graph and heat map represents its input score and class-specific contribution, respectively. Here, the sum of predicted confidence scores of ‘BPeach’ is larger than that of ‘BStrawberry’, and the mean rule will make a wrong decision. Unlike the mean rule, DM-GCN obtains a higher confidence score of ‘BStrawberry’ than ‘BPeach’ via a wei-ghted combination of outputs by building the relation among them.

The heat map illustrates that DM-GCN can automatically distinguish which outputs are helpful for the final decision. For the ‘BStrawberry’ decision made by DM-GCN, all the nodes with the ‘BPeach’ label are eliminated, indicating that the outputs with a certain class label have no contribution to the decision with a different class label. Moreover, when a single view has outputs with different class labels, DM-GCN will inhibit the contributions of each output. In this example, it is mainly reflected in the reduced sizes of nodes from View 3. Since the outputs from Views 1 and 2 only contain one class label, the node sizes remain the same as those in the input graph. DM-GCN utilizes identical input scores as the mean rule. However, the proposed method makes a correct decision, indicating that the weights for the input scores in View 1 increase in the combination. The process is similar to human perception because when humans recognize the object from these three views, View 1 will play a more critical role in their understanding. The result shows that DM-GCN enhances the contribution of the informative view when making a decision.
V. CONCLUSION
This study proposes a novel decision-making model with graph convolutional networks for multi-view single object detection. The proposed model is light, fast, and performs excellently on the Yogurt10 dataset. DM-GCN can be applied to any 2D object detector, which enables real-world applications. For future work, DM-GCN will be investigated on multi-view multi-object detection tasks.




