





I. INTRODUCTION
The Alzheimer’s disease (AD) is a neurological brain disorder which causes permanent damage to brain cells associated with the ability of thinking and memorizing. The cognitive decline caused by this disorder ultimately leads to dementia. The report implies that the brain changes identified with Alzheimer’s may begin 20 or more years before the appearance of symptoms [1] and currently there is no treatment for AD [2]. According to 2018 Alzheimer’s disease facts and figures, United States is the sixth leading cause of death and about 5.7 million Americans are living with AD [3].
While no cure exists for the disease yet, there is consensus on the need and benefit for early diagnosis of AD. Currently, many neurologists and medical researchers have been contributing considerable time to researching methods to allow for early detection of AD, and promising results have been continually achieved [4]. At present, there have been many studies about diagnosis of AD based on Magnetic Resonance Imaging (MRI) data, playing a significant role in classifying AD. Various computer-assisted techniques are proposed, classifying the characterized extracted features from the input images. These features are usually extracted from the regions of interest (ROI) and volume of interests (VoI) [5] or even combine different extracted features [6]. While most of the existing work has focused on the binary classification which only classifies AD from NC, proper treatment requires classifying AD, MCI and NC. MCI is a stage prior to AD, where patients will result in mild symptoms of AD and bare the chance of getting transformed to dementia [7].
Recently, machine learning techniques, particularly deep learning, show great potential in aiding the diagnosis of AD using MRI scans. Deep learning methods, such as CNN, have been shown to outperform existing machine learning methods [8-9]. It has made a massive progress in the field of image processing, mainly due to the availability of large labeled datasets such as ImageNet, for better and accurate learning of models. ImageNet offers around 1.2 million natural images with above 1000 distinctive classes. CNN trained over such images results in high accuracy also improves medical image categorization. However, there are certain limitations of training CNN from scratch, requirement of large dataset is one of them. As a result, another alternative approach called transfer learning can be used to overcome this problem which requires minimum dataset and consumes less time [10, 11]. Transfer learning is a machine learning method where a pre-trained network is reused as the starting point for a model on a second task.
In this paper, we employ three pre-trained base models to illustrate transfer learning to effectively classify AD. The main objective of this paper is to show how instead of training a completely new model from scratch, we can utilize transfer learning approach without any preprocessing of the MR images and achieve high accuracy. Moreover, in this study we compare the performance of different deep learning models such as GoogLeNet, VGG-16, AlexNet and SqueezeNet by applying transfer learning method.
II. Materials Used
The data used in the study were taken from the Alzheimer’s disease Neuroimaging Initiative (ADNI) database (http://adni.loni.usc.edu/). The ADNI was launched in 2003 by the National Institute on Aging (NIA), the National Institute of Biomedical Imaging and Bioengineering (NIBIB), the Food and Drug Administration (FDA), private pharmaceutical companies and non-profit organizations, as a $60 million, 5-year public-private partnership. The primary goal of ADNI has been to test whether serial magnetic resonance imaging (MRI), positron emission tomography (PET), other biological markers, and clinical and neuropsychological assessment can be combined to measure the progression of mild cognitive impairment (MCI) and early Alzheimer’s disease (AD). ADNI is the result of efforts of many investigators and subjects have been recruited from over 50 sites across the U.S. and Canada.
All subjects were required to be 60 years of age or older. The entire image set was classified subjectively by a neurologist, radiologist, and psychiatrist into categories AD, MCI, and NC. The details of MR images used in this study is shown in Table 1.
| Class | Male | Female | Age range (years) |
|---|---|---|---|
| AD | 160 | 170 | 70-90 |
| MCI | 190 | 210 | 70-90 |
| NC | 143 | 147 | 70-90 |
III. Classification using Transfer Learning
The proposed method exploits the transfer learning technique for 3-way classification of AD. The architecture of utilizing transfer learning is shown in Fig. 1.
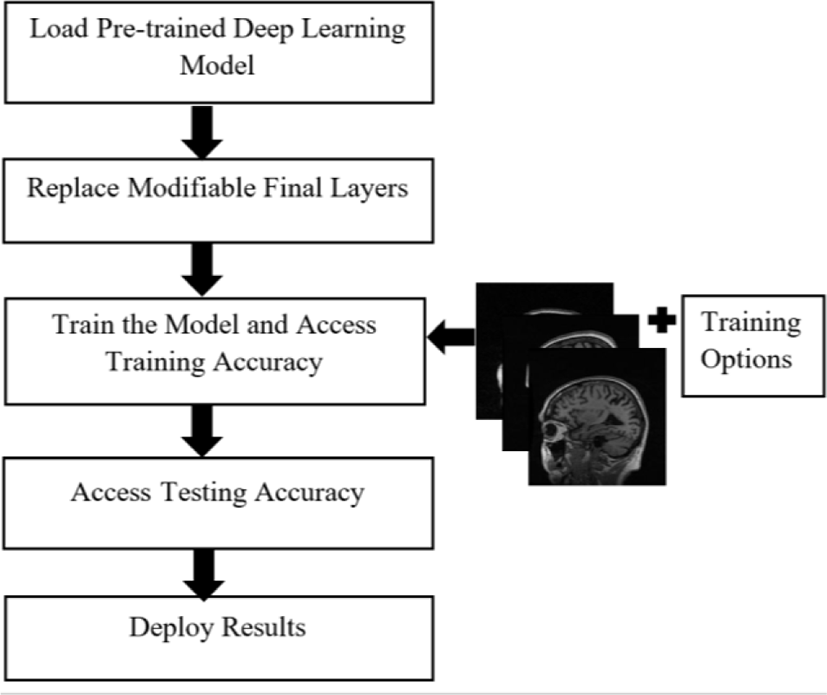
The transfer learning approach is helpful if we have a small training dataset for parameter learning [12]. We take a trained network, e.g., GoogLeNet as a starting point to learn a new task. GoogleNet pre-trained on ImageNet is taken as a base model to train a brain MR images from ADNI dataset. To use the transfer learning, the fully-connected layers are removed since the outputs of these layers are 1000 categories and is replaced by a new fully-connected layer followed by a softmax layer and an output layer for classifying 3 classes. Then, we train the network by providing training set MR images in addition to training options. Next, we test our model and obtain testing accuracy of the model. Finally, we deploy results using confusion matrix.
IV. Pre-trained CNN Architecture
Deep learning is a subfield of machine learning and a collection of algorithms that are inspired by the structure of human brain and try to imitate their functions. CNN is one such deep learning algorithm in which the transformations are done using the convolution operation. A typical CNN is comprised of three basic layers; a convolutional layer, a pooling layer and a fully-connected layer. However, an activation layer, normalization layer and a dropout layer also plays significant role in the deep architecture of CNN model.
The convolutional layer is the core building block of a CNN and is responsible for most of the computations done. It extracts the features from the input image which is to be classified [13]. Its parameter consists set of kernels or learnable filters. It performs the convolution operation or filtration over the input, forwarding the response to the next layer as a feature map [14]. The pooling layer is used to spatially reduce the spatial representation and the computational space [15]. It performs the pooling operation on each of the sliced inputs, reducing the computational cost for the next convolutional layer. The application of convolutional and pooling layers results in the extraction and reduction of features from the input images. The objective of a fully-connected layer is to take the output feature maps of the final convolutional or pooling layers and use them to classify the image into a label.
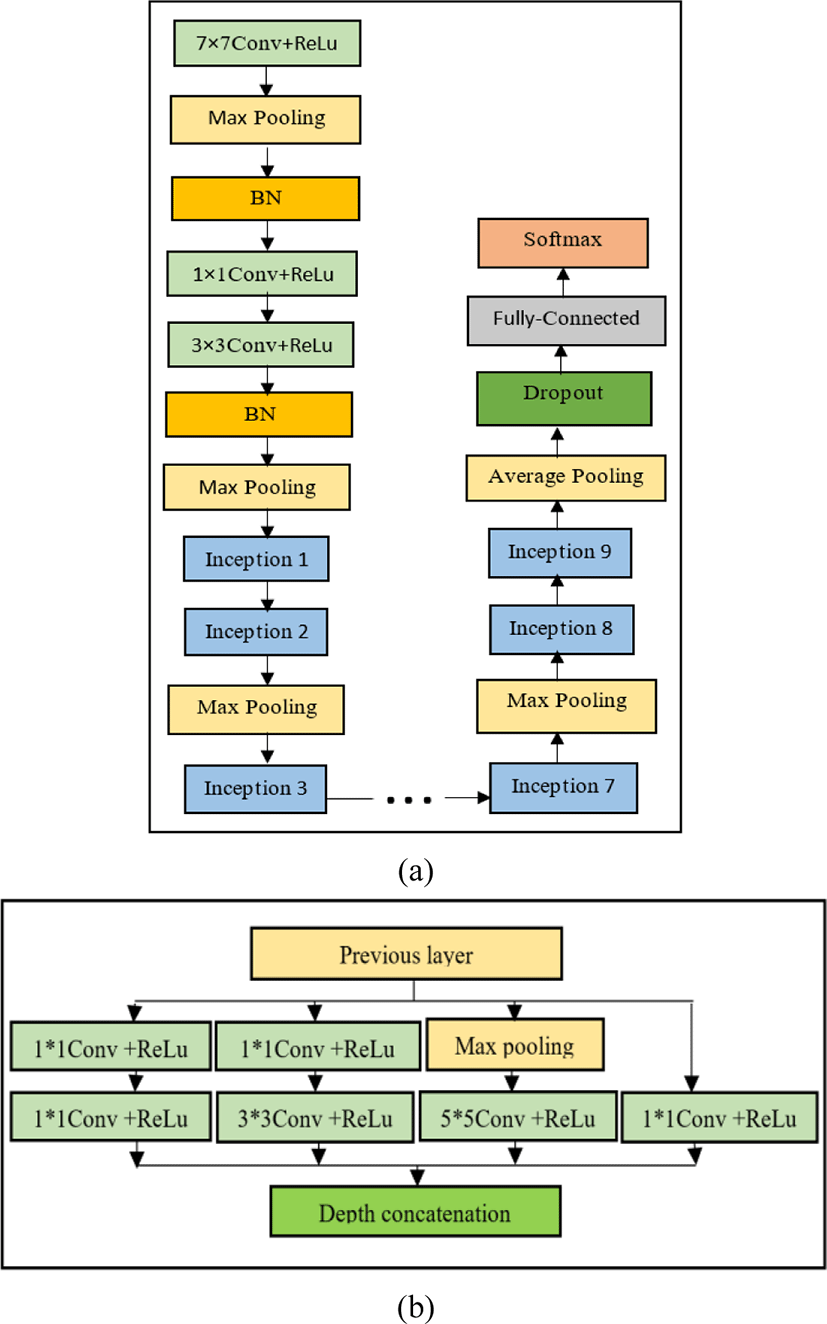
GoogLeNet has been trained on over a million images and can classify into 1000 object categories. It was introduced by a Google team and was the winner of ILSVRC-2014. The network is designed with computational efficiency and practicality in mind. The network is made up of 22-layers deep as shown in Fig. 2(a). All the convolutions, including those inside the inception modules, use rectified linear unit (ReLU) as an activation function. The size of the receptive field of our network is 224×224in the RGB color space with zero mean. Hence all the images were cropped and converted to 224×224×3 size which is a valid input size for our model. Uniqueness lies in the same 9 Inception modules used in GoogLeNet model [16]. Fig. 2(b) shows detailed structure of Inception layer.
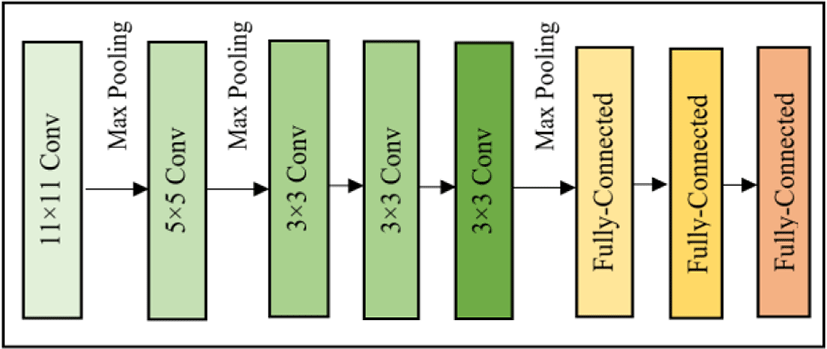
The original AlexNet architecture was trained over the ImageNet dataset [17] comprising images belonging to 1000 object classes. It was designed by Alex Krizhevsky and was the winner of ISLRVC-2012 [18]. The architecture of Alexnet is depicted in Fig. 3. It contains 8 layers with the first 5 layers as convolutional followed by 3 fully connected layers. AlexNet accepts input images of size 227×227in RGB color space. Therefore all the images were resized and converted to fit the network criteria to perform transfer learning.
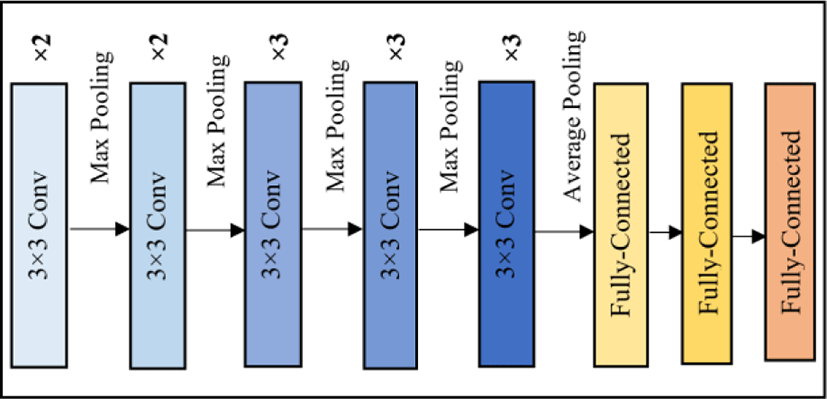
VGG-16 is a CNN model proposed by K. Simonyan and A. Zisserman in 2014 [19]. As the name indicates, the VGG-16 model contains 16 layers in total. Since VGG-16 was trained on RGB i.e., 3 channel images it can accept input only if it has exactly 3 channels. Thus, the input to the first convolutional layer is a fixed size 224×224 RGB image, resulted by cropping and converting the image. Fig. 4 shows the overall architecture of VGG-16 model.
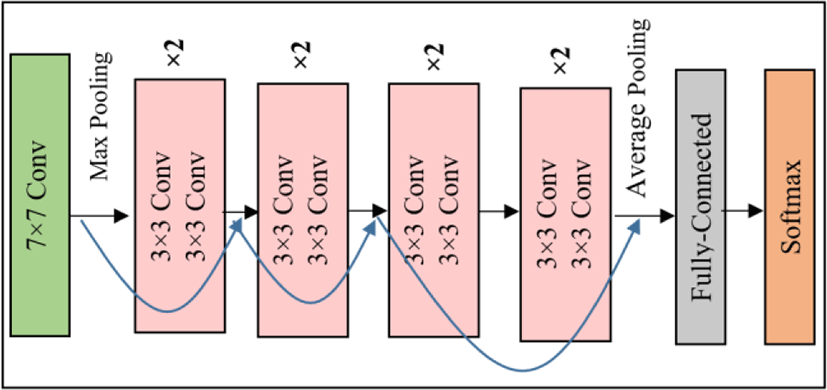
Deep Residual networks, shortly named as ResNet is developed based on the core idea addressed as shortcut connections or skip connections. These connections provide alternate pathway for data and gradients to flow, thus making training possible. The simplest model is ResNet-18 which has 18 layers. The input image size of this model is 224×224×3. It was developed by Kaiming et al., [20] and was winner of ILSVRC-2015. The detailed architecture of ResNet-18 and how skip connections run in parallel is shown in Fig. 5.
An ADNI dataset of total 1020 images is shuffled and split into train and test set in the ratio 70:30. The training and testing set used for 3-way classification (AD vs. MCI vs. NC) for all three networks are same and is shown in Table 2.
| Class label | Training set size | Testing Set size |
|---|---|---|
| AD | 231 | 99 |
| MCI | 280 | 120 |
| NC | 203 | 87 |
We evaluated the performance by changing the learning rate, which controls the amount of change required in response to the estimated error each time the model weights are updated. Choosing the learning rate is challenging as a value too small may result in a long training process, whereas a value too large may result in learning a sub-optimal set of weights too fast or an unstable training process. It also affects the accuracy of the model.
V. Results and Discussion
The classification model was built using MATLAB 2018, which easily offers transfer learning. Training options such as 100 epochs by considering validation patience of 5 as an early stopping parameter, a learning rate of 0.0001, stochastic gradient descent with momentum (SGDM) as an optimizer to minimize the loss function as well as adjust the weight and bias factors, and a mini batch size of 12 were selected to train 621 images. One Epoch is defined as completed when entire dataset is passed forward and backward through neural network. In our case, it took 51 iterations to complete 1 epoch. Validation patience or an extra epoch checks if the model remains stable without any further improvement and thus prevents the model from over-fitting problem.
Since accuracy is the primary evaluation metric, we analyzed training and testing accuracy results by changing the learning rate from 1e-2 to 1e-5 to see how learning rate affects the accuracy and loss of the model. However, as expected the model produced optimal results for learning rate 1e-4. Therefore, we evaluated all models by fixing the learning rate to 1e-4. The accuracy was obtained using a confusion matrix, which describes the performance of a classification model. The confusion matrix of GoogLeNet, AlexNet, VGG-16 and ResNet-18 are showed from Table 3 to 6. The training and validation progress of all the models used in this paper is shown in Figs. 6-9.
| Class label | AD | MCI | NC | Total Data | Accuracy |
|---|---|---|---|---|---|
| AD | 96 | 0 | 3 | 99 | 97.05% |
| MCI | 0 | 120 | 0 | 120 | 100.00% |
| NC | 2 | 0 | 85 | 87 | 97.70% |
| Class label | AD | MCI | NC | Total Data | Accuracy |
|---|---|---|---|---|---|
| AD | 88 | 8 | 3 | 99 | 86.90% |
| MCI | 5 | 114 | 1 | 120 | 95.00% |
| NC | 0 | 0 | 87 | 87 | 100.00% |
| Class label | AD | MCI | NC | Total Data | Accuracy |
|---|---|---|---|---|---|
| AD | 76 | 0 | 23 | 99 | 76.80% |
| MCI | 4 | 107 | 9 | 120 | 89.2% |
| NC | 0 | 0 | 87 | 87 | 100.00% |
| Class label | AD | MCI | NC | Total Data | Accuracy |
|---|---|---|---|---|---|
| AD | 92 | 5 | 2 | 99 | 92.90% |
| MCI | 0 | 120 | 0 | 120 | 100% |
| NC | 2 | 0 | 85 | 87 | 97.70% |
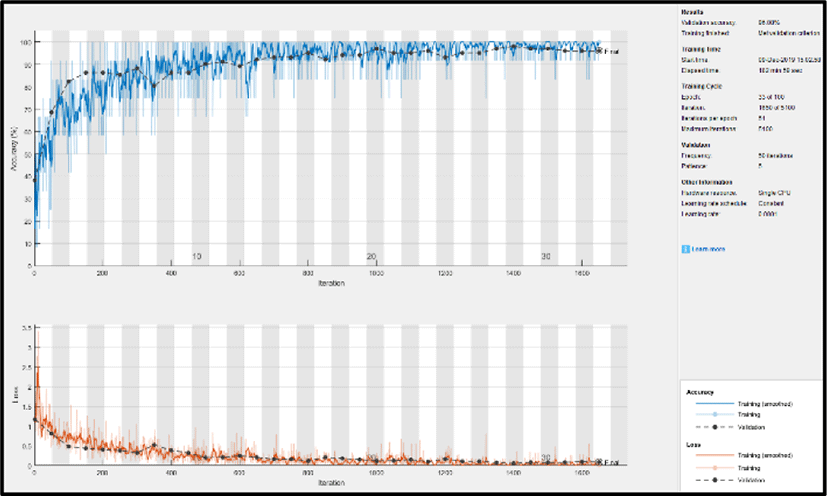
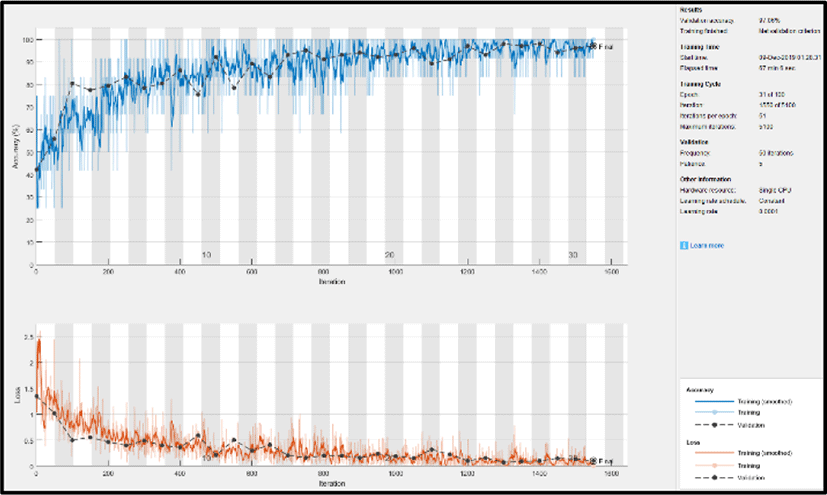
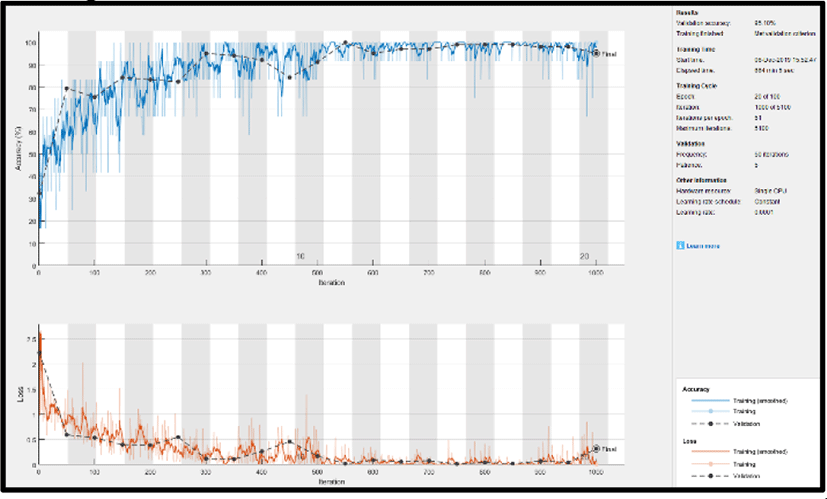
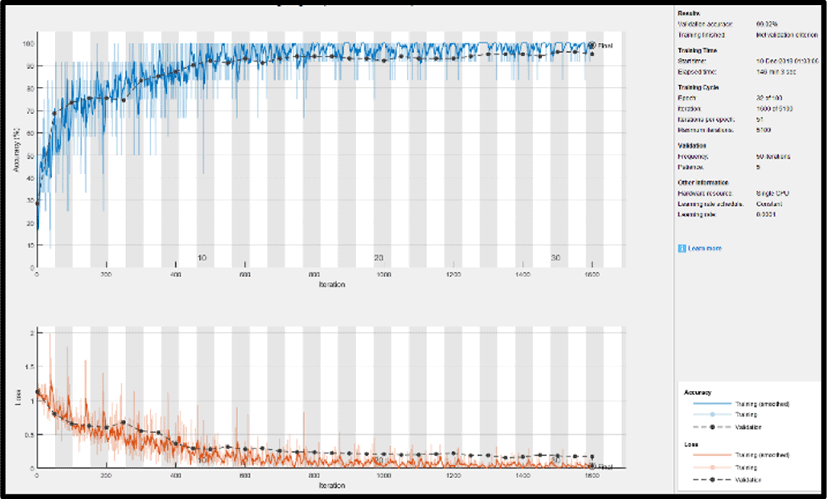
Figs. 5~8 show how the models progresses when training the model and how its accuracy and loss change. Although every models were trained for 100 epochs, it was trained for less epochs due to early stopping in order to prevent the model from overfitting. In Fig. 5, we can clearly note that the training loss of GoogLeNet steadily declined and almost reached zero while raising the accuracy of the model. The possble reason for this is the inception modules used in GoogLeNet, which increases the depth of the model and learns more features from the image. Nevertheless, other models were also capable in reducing the loss with an increase in accuarcy. ResNet-18 in Fig. 8 also performed well with the reduction in loss to almost zero. It was more efficient as compared to AlexNet and VGG-16 due to skip connections used in the network.
In Table 3., we can clearly note that GoogLeNet was successful in classification with 97.05% of AD, 100% of MCI and 97.70% of NC being correctly classified. Thus, the overall testing accuracy of GoogLeNet resulted in 98.25%, Moreover, the other models also resulted in good accuracies such as AlexNet, VGG-16 and ResNet-18 shown in Table 4, 5 and 6 respectively. Among these models ResNet-18 outperfomed the other two models with 92.90% of AD, 100% of MCI and 97.70% of NC correctly classified. However, GoogLeNet surpasssed the other models with the highest testing accuracy, hence, outcoming as the best model to classify AD.
From Table 7, we can conclude that GoogLeNet is a powerful deep learning model for medical images specifically MR images classification. GoogLeNet produced highest training and testing accuracy over other models. The second highest accuracies was obtained by ResNet-18 outperforming AlexNet and VGG-16.
| Models | Training Accuracy | Testing Accuracy |
|---|---|---|
| GoogLeNet | 99.84% | 98.25% |
| AlexNet | 99.18% | 93.97% |
| VGG-16 | 98.37% | 88.66% |
| ResNet-18 | 99.02% | 96.8% |
VI. CONCLUSION
The detection of Alzheimer’s disease remains a difficult problem, yet important for early diagnosis to get proper treatment. Currently, there is no treatment for AD and hence, early detection and classification is very important task to treat the patient. While there are many classification algorithms used in present days, classification using deep learning has captivated every researchers due to its flexibility and capacity to produce optimal results. However, in medical field acquiring enough data (images) is quite difficult as well as training a model from scratch is time consuming. Therefore, to overcome these problems transfer learning is used which requires only minimal data and takes few hours to classify MR images.
In this paper, we used transfer learning approach using different deep learning models such as GoogLeNet, AlexNet, VGG-6 and ResNet-18 as the base model for accurately classifying MR images amongst three different classes: AD, MCI and NC. We analyzed these models by changing the learning rate and the performance obtained at 1e-4 outperformed the performance of other cases. The models were well trained for our datasets and all the models were efficient in classification. Among all the other models, GoogLeNet produced the highest training and testing accuracy of 99.84% and 98.25% respectively. Therefore, transfer learning using GoogLeNet is definitely a successful approach to classify MR images into AD, MCI and NC.





