




I. INTRODUCTION
The Internet which varies from the source with useful information has become more and more developing. Hence, the data across the Internet must be secure. Intrusion Detection System (IDS) is, therefore, the tool needed in for this requirement. IDS became an essential part of the security management since network administrator based on IDS in order to prevent malicious attacks. Furthermore, IDS can detect and block attacks on the network, retain the performance normal during any malicious outbreak, perform an experienced security analysis. IDS have two different classified groups. First is anomaly detection and other is signature based detection or misused detection. To detect unknown anomalies we used to anomaly detection. On the other hand, misused detection used the known pattern to detect attacks. However, misused detection cannot detect the unknown anomalies. There are many researchers have done significant this work to develop IDS. These papers proposed an architecture of the classification techniques, algorithms being used such as Machine Learning techniques and the algorithms of neural networks.
In this paper, we organized as follows: Section II introduce the related work. Section III presents briefly background recurrent neural network and activation functions. Experiential setup is shown in Section IV. Section V is the result of the experiment. Final Section includes conclusion for our work.
II. RELATED WORK
There are many approaches applied for IDS based on Machine Learning. An experimental framework to compare supervised (classification) and unsupervised (clustering) learnings for detecting attack activities by Laskov [1]. The results of [1] show that the supervised algorithms show better classification accuracy on the data with known attacks. Besides Lee at el. [2] build a classifier to detect anomalies in networks using data mining techniques.
In addition, there are several algorithms based on four techniques of computational intelligent: genetic algorithms (GA), artificial neural networks (ANN), fuzzy logics (FL) and artificial immune system (AIS). To GA, Sinclair [3] use genetic algorithms and decision tree to create rules for intrusion detection expert system. Then, Li [4] describes a few disadvantage of the algorithm in [3] and defines new techniques for IDS rules. Besides ANN have the ability to learning by example and generalize from limited, noisy, and incomplete data. By combining neural network and SVM Mukkamala [5] applied it to intrusion detection. To FL, Gomer and Dasgupta [6] show that with fuzzy logic, the false alarm rate in determining intrusive activities can be reduced. Finally, AIS which consist of molecules, cells, and tissues that establish body’s resistance to infection by pathogens like bacteria, viruses, and parasites. The first of AIS is modelled various computer security problems by Hofmeyr [7]. Then, Kim [8] provide key developments computer security and six immune features for an effective IDS. Zamani [9] [10] describe an artificial immune algorithm for IDS by proposed a multi-agent environment the computationally emulates the behavior of the natural immune system to reduce false positive rates.
III. BACKGROUND
In this section, we summary about the knowledge of Recurrent Neural Networks (RNN) and activation functions.
RNN is an extension from Feed Forward Neural Network. RNNs are called recurrent since they perform the same task for every element of a sequence, with the output being depended on the previous computations.
Fig.1 is a typical RNN and the unfolding in time of the computation involved in its forward computation. An RNN consists of three layers. The first is input layer (x). The second is hidden layer (h). Output layer (y) is the final.
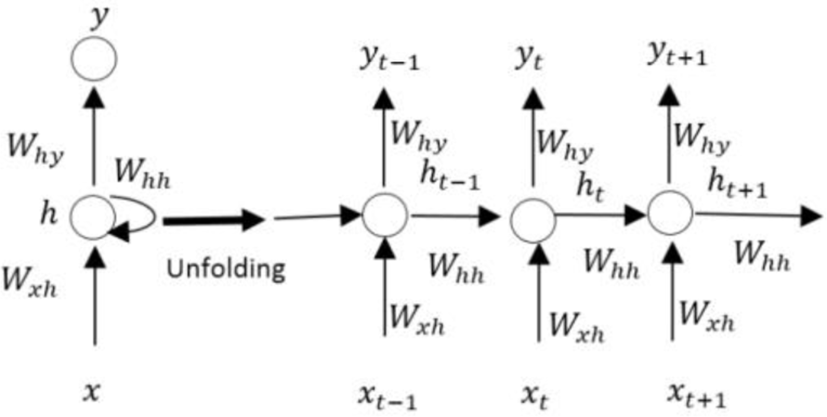
First, we need to calculate hidden layer at time t based on the previously hidden state and the input at the current step:
Second, we need to compute the prediction of the model from hidden layer to output layer.
Where:
-
Wxh is weight matrix connecting between input layer to hidden layer
-
Whh is weight matrix connecting between hidden layer to hidden layer
-
Why is weight matrix connecting between hidden layer to output layer
-
f is an activation function, we describe in Section 3.2.
Activation functions transform neuron’s input into output layer. Features of activation functions consist of two issues. Firstly, it is a squashing effect is required. It prevents accelerating the growth of activation levels through the network. Secondly is simple and easy to calculate. There are many activation functions that are used to for neural network. However, we choose several representative activation functions which effect to train RNN model. They are nonlinear activation functions. We briefly describe these activation functions follow as:
-
SoftPlus
This activation function was proposed by Glorot [11]. This softplus function can be approximated by max function (or hard max), i.e. max(0, x + N(0,1)). The gradient of the sigmoid function vanishes as we increase or decrease x. The equation of SoftPlus is:
Here is the plot of this activation
-
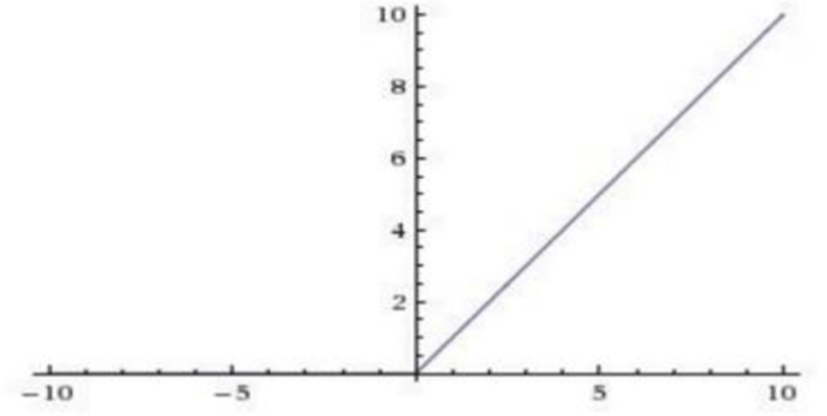
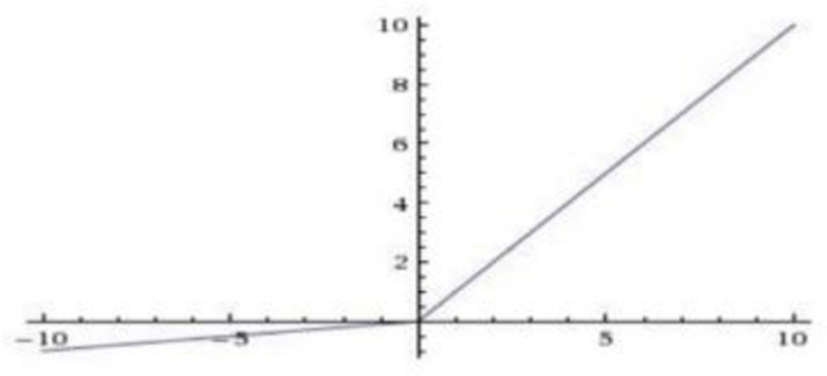
ReLU (Rectified Linear Unit)
ReLU was proposed by Nair [12]. ReLU does not face gradient vanishing problem as with sigmoid and tanh function. Also, it has been shown that deep networks can be trained efficiently using ReLU even without pre-training. The equation of this function is:
Here is the plot of ReLU activation:
-
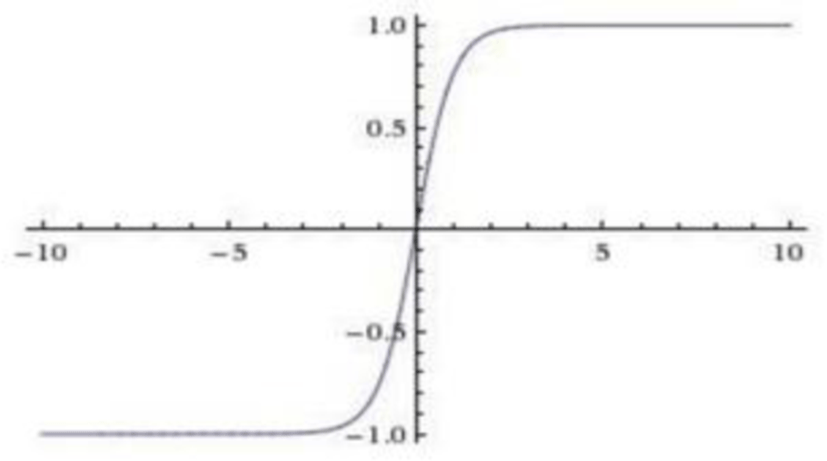
Tanh
Tanh is a transformed version of Sigmoid which takes values in ±1 instead of the unit interval. Input with large absolute values and approximate 1 for large positive inputs. The equation of this function is:
Here is the plot of Tanh activation:
-
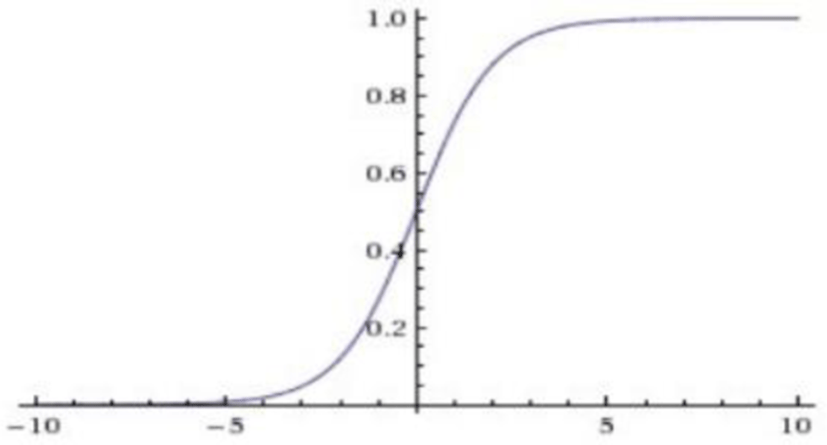
Sigmoid
Sigmoid function has range [0, 1]. Hence this function can be used to model probability. The equation of this function is:
Here is the plot of this activation:
-
LeakyReLU (Leaky Rectified Linear Unit)
This activation is first introduced in the acoustic model by Maas [13]. A LeakyReLU can help fix the dying ReLU problem. ReLU’s can die if a large enough gradient changes the weights such that the neuron never activates on new data. We have the equation:
Here is the plot of LeakyReLU:
-
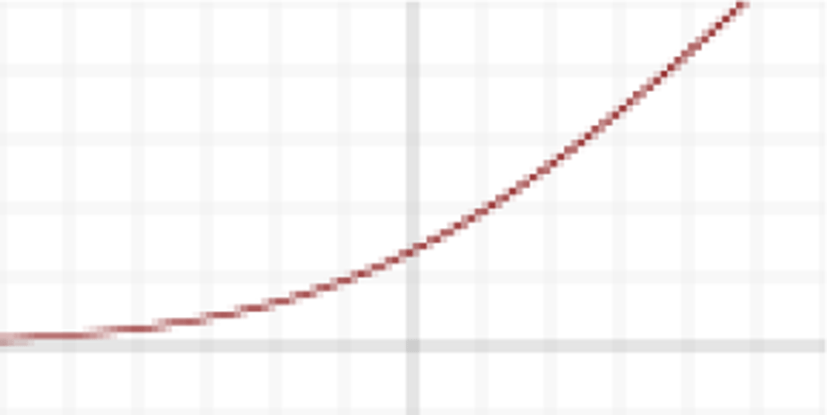
ELU (Exponential Linear Unit)
This activation function is proposed by Clevert [14]. This function which speeds up learning in deep neural networks. ELU alleviate the vanishing gradient problem via the identity for positive values. The formula for this function is:
The plot of ELU is shown in graph below:
IV. EXPERIMENTAL SETUP
There are several main points which we need to mention in our processing. The first, we need to choose a suitable dataset to experiment. The second, we set up the best of values for model’s hyperparameters. The third, the implementing environment is set up for training and testing processes. The final, we use to evaluation metrics to evaluate our training model.
We choose KDD Cup dataset to train our model. There are four types of category attack as such as DoS, R2L, U2R, and Probe. Each attack consists of many small attacks. Dos (Denial of Service) is denied legitimate requests to a system. U2R (User-to-Root) is unauthorized access to local super user (root) privileges. R2L (Remote-to-Local) is unauthorized access from a remote machine. Probing (Probe) is surveillance and another probing. Each attack consists of many small attacks. The training dataset has 22 types of attacks is shown in Table 1. And Table 2 shows 37 types of attacks for the testing dataset. How to do preprocessing this dataset for our experiment is mentioned in [15].
The hyperparameters of values are important when we train our model. Therefore, choosing these values as suitable will help us achieve better performance. In our work, we set up the hyperparameters to train for our model as the manual. The values are shown in detail in Table 3:
| Name of hyperparameter | Value |
|---|---|
| Learning rate | 0.001 |
| Number of hidden layers | 80 |
| Epochs | 500 |
We perform to measure classification performance on our environment as following: Intel ® CoreTM i7-4790 CPU @3.60GHz; GPU: NIVIA GeForce GTX 750; RAM: 8GB and OS: Windows 7.
We use to confusion matrix to evaluate our model. There are some metrics to compute such as Accuracy, Precision, and Recall. Here are some equations:
Where,
-
TP is a number of predicted as Normal while they actually were Normal.
-
FP is a number of predicted as Attack while they actually were Normal.
-
FN is a number of predicted as Normal while they actually were Attack.
-
TN is a number of predicted as Attack while they actually were Attack.
Besides, we calculate the False Alarm Rate (FAR) which is the ratio of misclassified normal attack.
V. EXPERIMENTAL RESULTS
We perform our approach with six activation functions to finding the best activation function for RNN on IDS.
In Fig. 2, we observe the graph that describes the classifying of each attack on IDS with our model using activation functions.
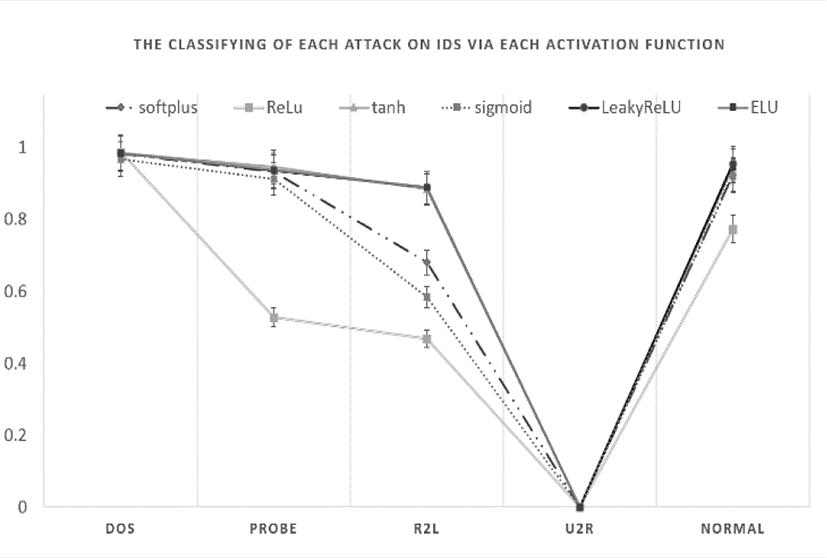
In particular, the result in detail of that graph is shown in Table 4. Among them, the best of the result is at LeakyReLu activation with almost the biggest of values.
Besides, we perform performance of classifying on IDS with RNN using six activation functions. By computing the Accuracy, Recall, and Precision, we present our result in Fig.3. And this result is described in Table 5 in detail.
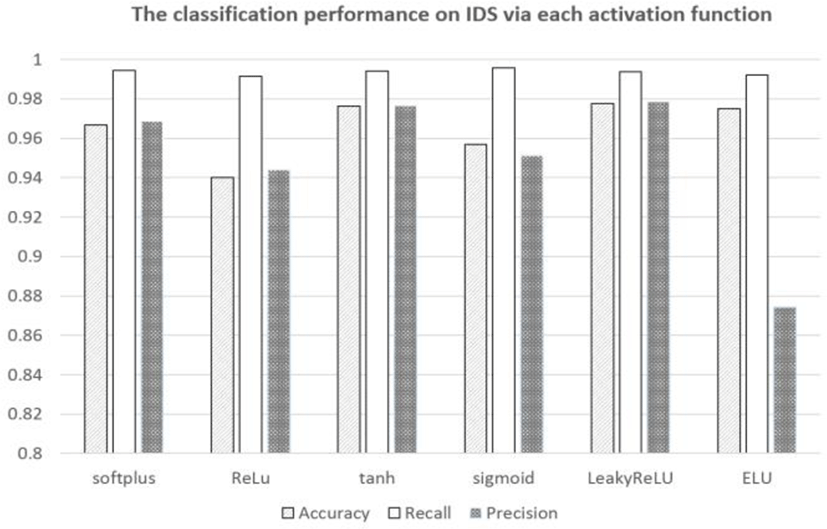
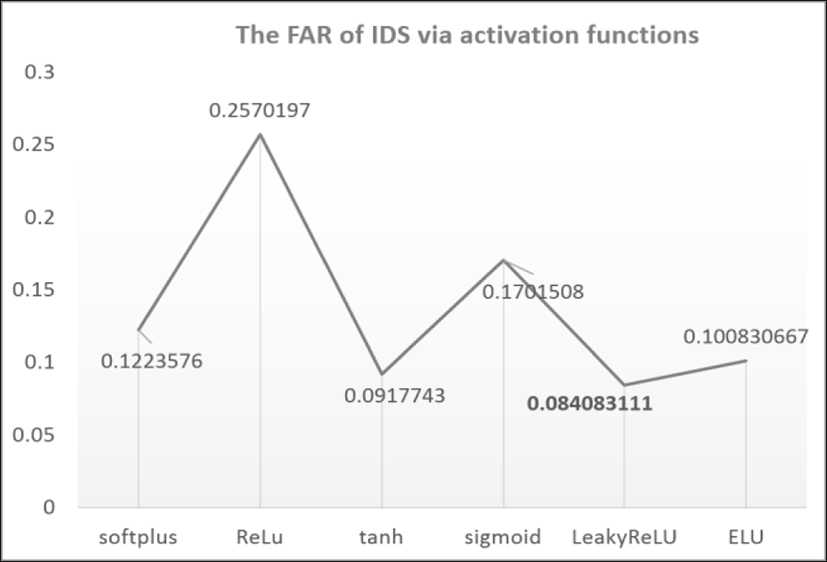
Furthermore, we compute False Alarm Rate (FAR) measurement. The smaller value of FAR, the better our approach. Obviously, the smallest of FAR is near 0.084 at LeakyReLu activation.
From these results, we conclude LeackyReLu activation is used to RNN outperform to others.
VI. CONCLUSION
In our work, we perform our approach using RNN model though six activation functions. By our results, we found that LeakyReLU function returns to the best of performance classification among them. Particularly, we achieve 97.77%, 87.85% and 99.38% to accuracy, precision and recall. Hence, we confirm that RNN model using LeakyReLU function can build a new better IDS classifier.